






1. 龙年第一个爆火的,竟然是AI?
2024年2月16日,就在我们忙着过春节时,大洋彼岸,OpenAI又悄无声息地放出了“王炸”:颠覆人类对AI视频认知的文生视频大模型——Sora。
虽然未经提前预热,但Sora很快成为科技圈的重磅热点,引发360创始人周鸿祎等人下场讨论。
周鸿祎认为:Sora的诞生意味着AGI(通用人工智能)实现可能从10年缩短至一两年!
各社交媒体上,引发了大量关于sora的讨论:
短短数日,在抖音上,关于sora的讨论量也达到1.7亿:
![]()
2. Sora是什么?能做什么?
Sora,是指OpenAl在2024年2月16日发布的首个文本生成视频模型。Sora可以根据用户的提示,生成长达一分钟的视频,同时保持较高的视觉质量。
从2022年11月Chat GPT的横空出世,到2024年初Sora的爆火,再到国产AI软件层出不穷,AI技术正在以惊人的速度发展。
暂时抛开“版权”“隐私”和“伦理”问题,很明显,无论是否准备好,我们正在迅速迈向一个由AI驱动的世界。
AI的应用领域十分广泛,我们回归到熟悉的领域:地理信息系统。
那么,AI和GIS能擦出什么样的火花?AI能带动GIS发展吗?还是说GIS能助力AI,成为AI发展的王牌助手?
在讨论这个问题之前,我们先简单了解一下AI是什么?
3. 什么是AI?
人工智能(Artificial Intelligence,简称AI)是一门研究如何使计算机系统具备智能行为的学科。其目标是使机器能够执行需要智能的任务,模拟甚至超越人类的某些智能能力。人工智能涉及多个领域,包括机器学习、深度学习、自然语言处理、计算机视觉、专家系统等。
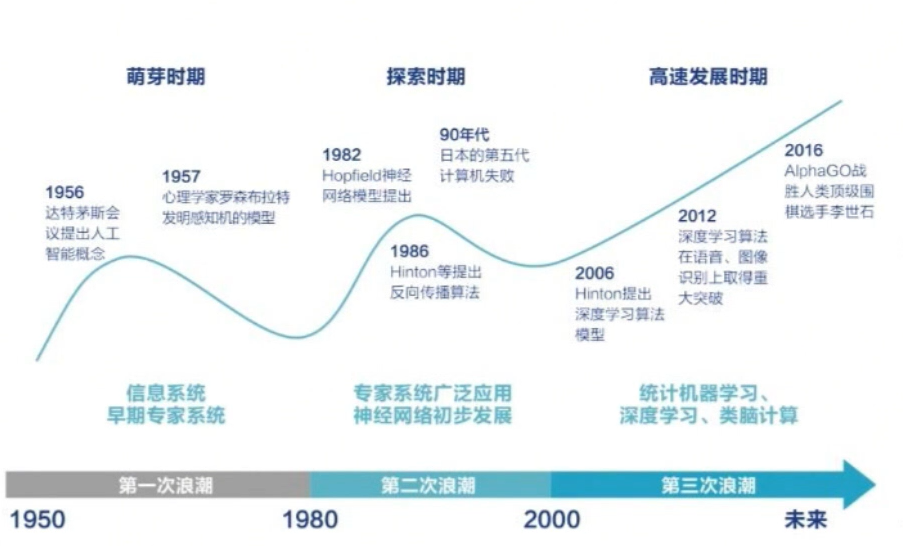
AI的发展历程
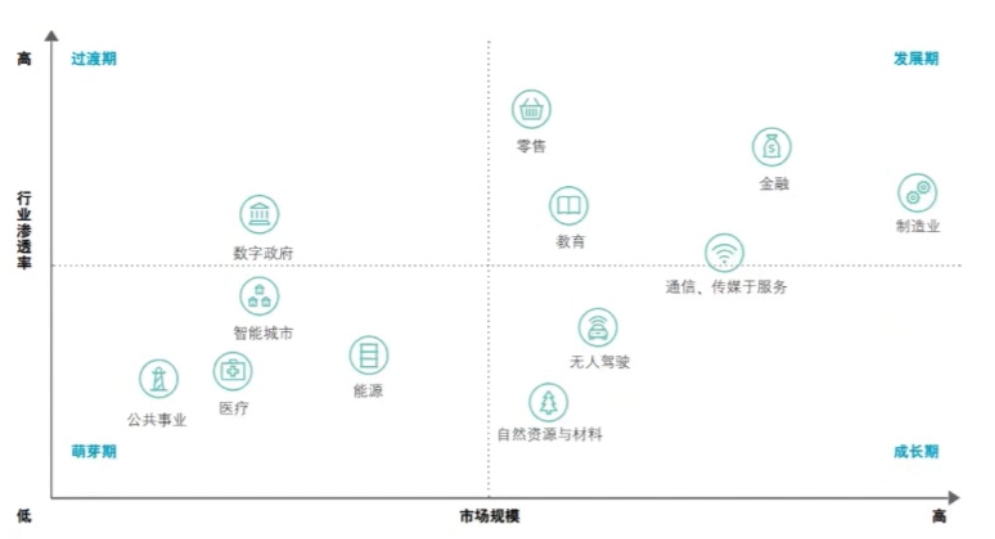
AI的市场规模
4. 什么是计算机视觉?
由于AI应用范围比较广泛,这里重点介绍计算机视觉方面,跟GIS联系较为紧密。
计算机视觉是AI领域的一个重要分支,致力于使计算机系统具备对图像和视频进行理解和解释的能力。
它涉及使用计算机算法和模型,使计算机能够模拟人类视觉系统的功能,从而实现对图像和视频的感知、分析和理解。
常见的计算机视觉任务,主要主要有四类:
图像分类:图像分类是将图像分为不同类别的任务,通过训练模型使计算机能够自动识别图像中的对象。
物体识别:物体识别涉及识别图像中的整个物体,并理解其在场景中的位置和角度。
目标检测:目标检测是识别图像中特定物体或目标的过程,可以用于自动驾驶、安防监控等应用。
三维重建:三维重建涉及从二维图像中还原出三维场景的空间结构,常用于计算机辅助设计和虚拟现实。
5. AI在GIS软件方面的应用
以mapgis为例,下面是AI在GIS方面应用的一个整体框架:
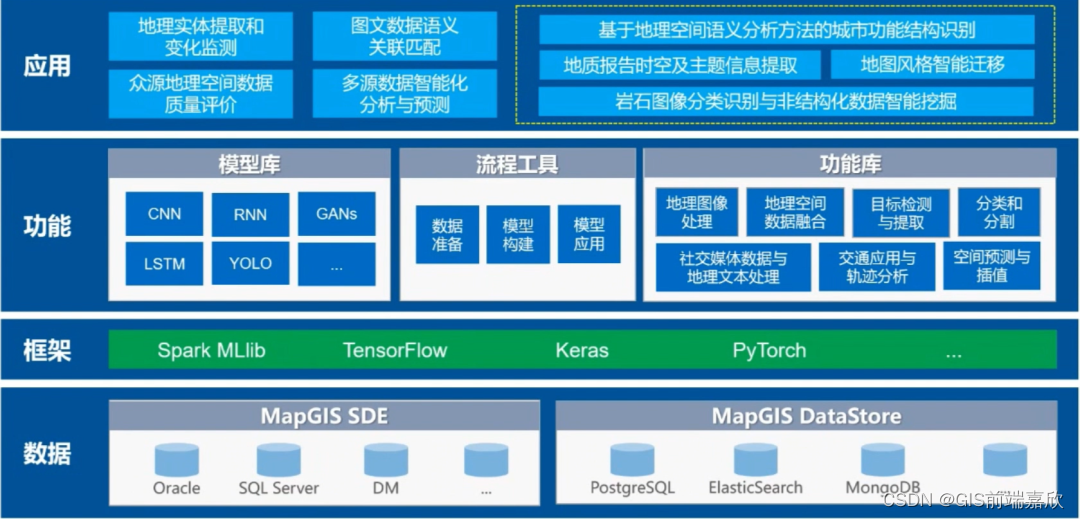
这个框架呢主要就是分了四层,第一底层是数据层,主要就是我们MapGIS SDE和MapGIS的data store;第二层是一个框架层,主要就是这些个人工智能的框架,能够对这些算法进行支持;主要我们使用的最多的应该是TensorFlow和PyTorch。
第三个就是针对不同任务,进行一个细致划分的一个功能层。主要包括模型库、流程工具和功能库,这个模型库里边,主要就是我们已经封装好的一些算法,比如说什么常见的一些CNN RNN,还有这个对抗生成网络GAN,还有这个长短长短期记忆网络,或者是YOLO。
这些网络流程工具主要用来处理视觉上面的一些数据。因为我们视觉方面的数据大部分都是一些遥感图像,所以就需要涉及到数据准备一些工作。
这些AI工具最擅长的是应用层主要就是什么地理实体提取和变化检测之类的一些数据处理方面,就是通过data store进行一个管理,主要管理的就是影像和矢量图层。
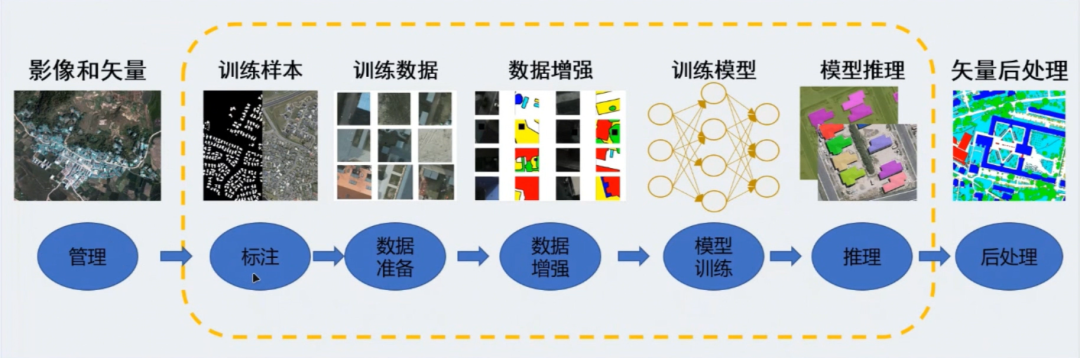
人工智能数据处理框架图
6. 这些工具主要有哪些功能呢?
标准数据增强:
主要包括线性拉伸、随机旋转、数据归一化等手段进行标准的数据增理

图像裁剪增强:
RandErasing方法,随机生成掩膜来增加模型对复杂地物的适应性

图像混叠类增强:
可增强模型的抗干扰能力

7. 常见的AI算法
说到底层技术,不得不谈到算法,AI的核心还是模型和算法。GIS方面应用较多的AI算法有以下几类,这里仅距离说明。
1、影像分类:
影像分类是指对影像的类别进行定性地分析,在多幅相似或不同的遥感影像中可以精确地分辨出遥感影像的类别(或影像所描述的场景),针对大范围影像分类结果返回一个大小均匀的矢量网格,每个网格带有其对应位置影像的类别标签:针对单张图片,影像分类结果返回的是图片的类别信息,总体来说影像分类是一种高于像元级别的粗粒度分类方法。
该方法不仅仅适用基于小范围遥感影像的语义分析对遥感影像数据进行分析和管理,还可以基于对图像的场景理解,对图像的类别做出评估。
自动化图像分类:
图像分类网络通过学习大量标记好的图像数据,能够自动识别和分类图像中的内容。这使得大规模图像的分类工作可以高效自动完成,减轻了人工劳动负担。
提高图像识别准确性:
图像分类网络通过深度学习算法,能够学习图像中的复杂特征和模式,从而提高了图像识别的准确性。这对于各种应用场景,如医学影像、安防监控、自动驾驶等,具有重要意义。
推动深度学习发展:
图像分类网络是深度学习领域的代表性应用之一。其成功应用推动了深度学习技术的发展,为其他复杂任务的解决提供了经验和基础
2、语义分割
是计算机视觉领域中一种重要的图像分析任务,其目标是将图像中的每个像素分配到预定义的类别中,从而实现对图像的精细化理解。与目标检测不同,语义分割不仅关注物体的位置,还关注物体的边界和形状,使得每个像素都被赋予语义标签。

U-Net(全卷积网络)是一种用于图像分割任务的深度学习架构,由德国图灵奖获得者Ronneberger等人于2015年提出。U-Net的设计灵感来源于生物医学图像分割的需求,尤其是医学图像中器官和病变的精确分割。
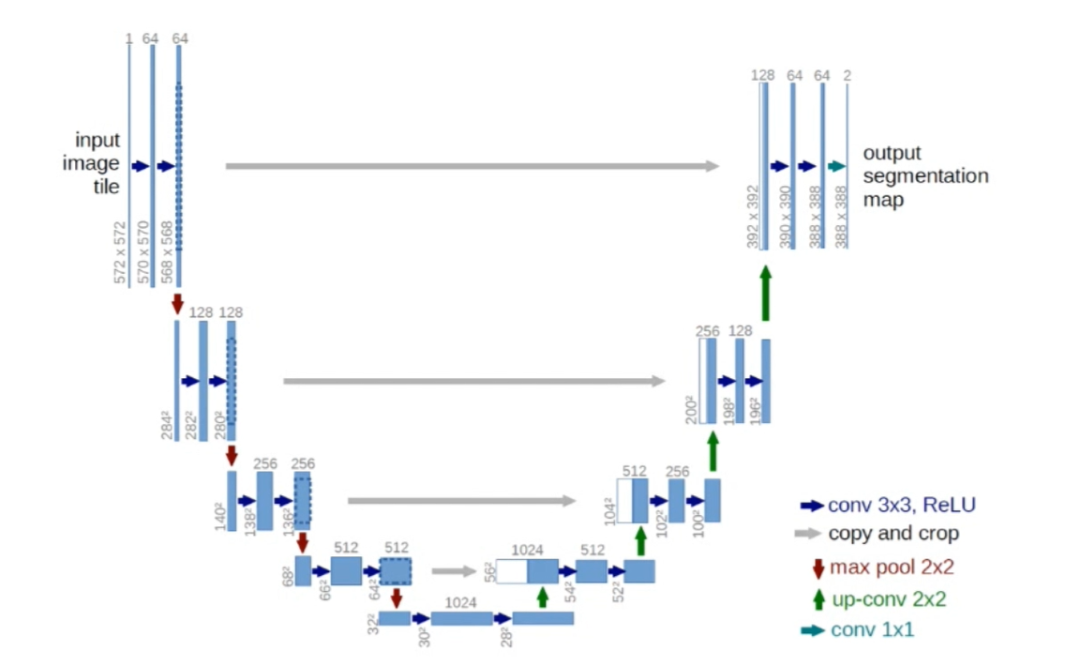
U-net网络结构示意图
DeepLab是一系列用于语义分割任务的深度学习模型,由Google提出。这一系列模型以卷积神经网络为基础,通过引入深度可分离卷积和空洞卷积等技术,致力于解决图像分割中的细节捕捉和计算效率的问题。
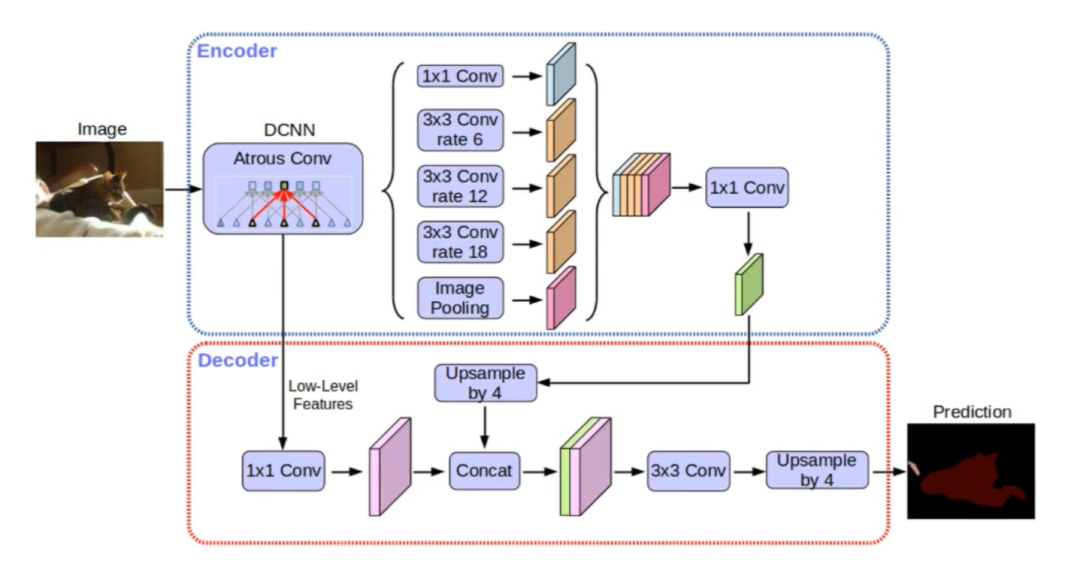
DeepLab v2模型示意图
其他的这里就不一一赘述。
需要更多详细介绍的同学,可以戳下面备注【人工智能与GIS】,领取详细视频讲解:
8. AI在GIS中的应用

模型说明:
-
适用功能:影像分析,二元分类和多元分类。
-
适用场景:建筑物、道路等地物提取。
输入数据类型:
-
影像数据
算法特点:
-
速度快、精度高、网络结构清晰
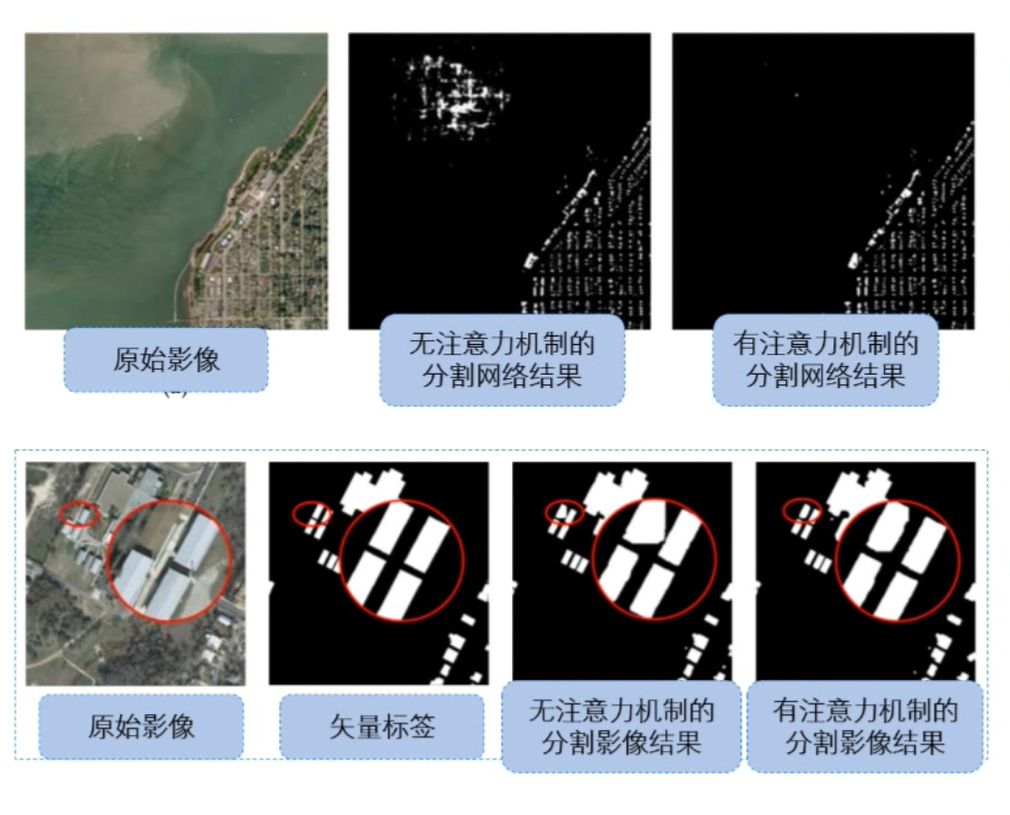
结果说明:
通过对测试数据进行预测后,计算出了精度(Accuracy)、召回率(Recall)和F1指标(F1 score)我们可以看出,加入了注意力机制,模型的精度极大提升。
9. AI未来的发展方向之:语言大模型(LLM)
最后,谈一下红极一时的chatgpt对人工智能发展的一些贡献和特点。
Chatgpt主要贡献:
-
强化学习中引入人类反馈的学习方法
-
高质量微调数据指令集的重要性
核心能力:生成、总结、提取、分类、检索和改写
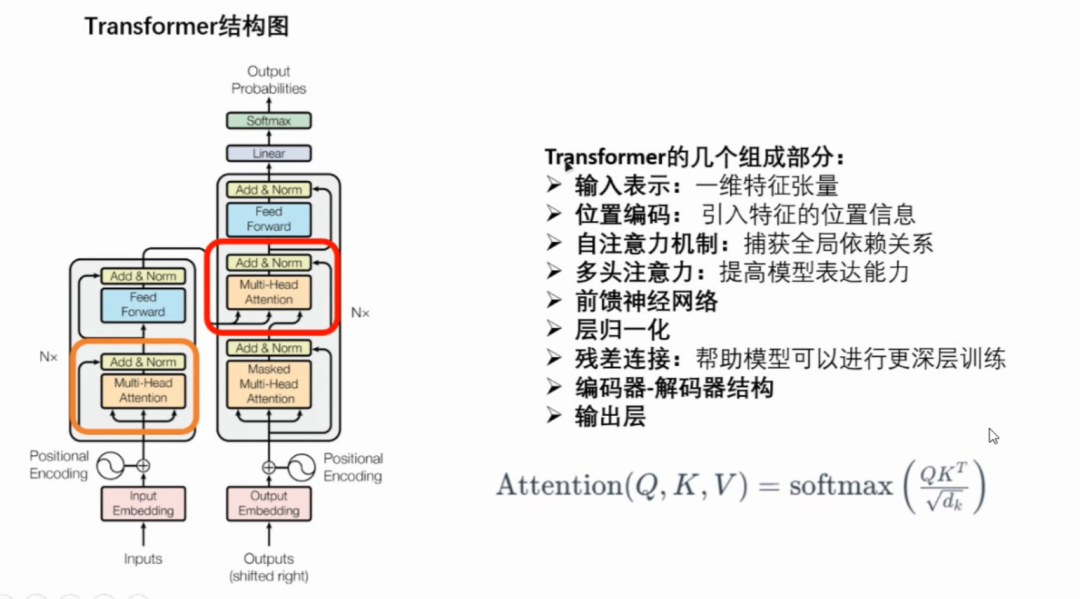
10. ChatGPT的主要技术:
Transformer架构: ChatGPT基于Transformer架构。Transformer是一种使用自注意力机制(Self-Attention Mechanism)的深度学习模型,适用于处理序列数据,如自然语言。自监督预训练: ChatGPT采用了自监督预训练的方法。这意味着在模型在特定任务上进行微调之前,它首先在大规模的语料库上进行了预训练。GPT模型通过学习预测序列中缺失的一部分内容,从而学到了语言的结构和上下文理解。
大规模参数: GPT-3是一个参数规模庞大的模型,具有1750亿个参数,这使得家在各种任务上表现出色,包括聊天式对话。
微调: ChatGPT可能会在特定的任务上进行微调,以适应更具体的应用。微调过程通常涉及在特定任务的有标签数据上对模型进行额外的训练。
上下文处理: GPT模型使用自注意力机制,能够有效地处理长文本序列,这对于处理上下文丰富的对话非常有用。
12. GIS+GIS=GeoGPT:
将语言大模型和GIS工具集结合在一起,降低非专业用户解决地理空间任务的门槛。主要应用在:间数据抓取、空间查询、设施选址和制图等方面。
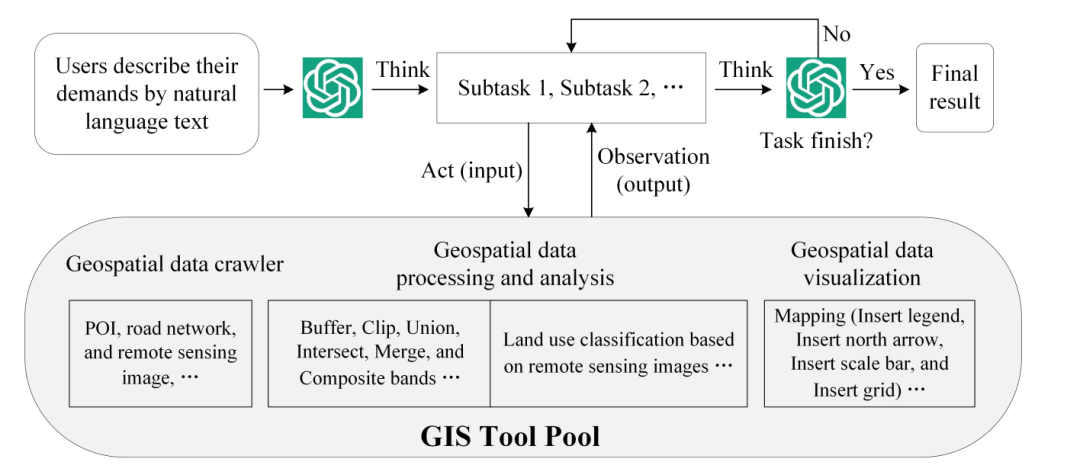
简单概括一下上述GIS tool pool的流程:
首先用户提需求,通过AI模型的反复分析,分解为各个指令,再从GIS的相关应用词里面抽取一部分符合任务描述要求的工具,组成一个流程图,最后输出的一个结果。
再看下面这个图:
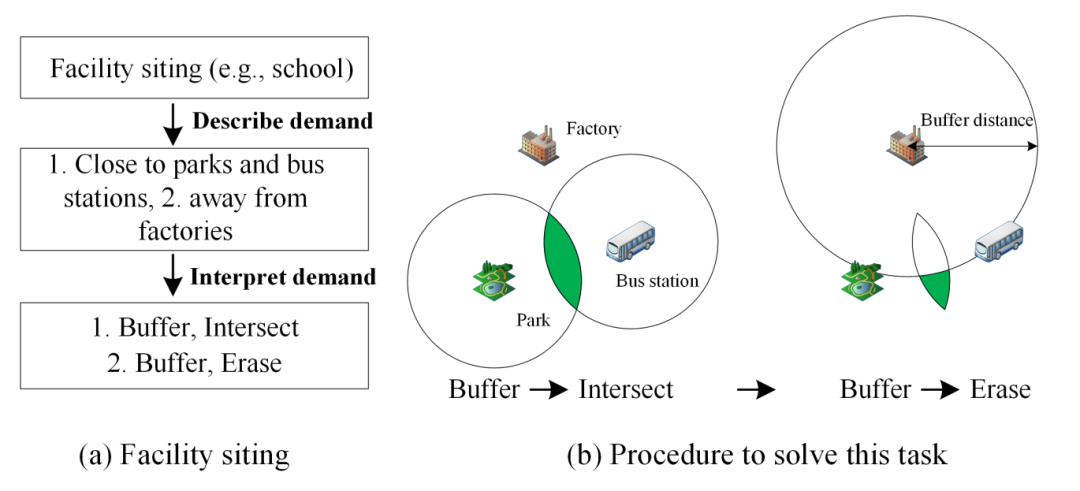
这个图就是一个学校的选址的流程。
要求1:我想要离公园近一点;
要求2:我还想要离工厂远一点;
这里就涉及到GIS中的缓冲区的概念。
右边的图中可以看到公园和那个公交站的一个交叉区域,通过离工厂的一个半径,最后筛选出来,适合选址的一个区域。
这样做的主要优势在于,能够就是降低非专业用户的门槛——非GIS专业的认,也能够通关AI模型,解决地理空间任务和问题。
关于GIS和AI的内容,我们暂时介绍到这里。















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









