






目录
引言
在人工智能的快速发展中,大型语言模型(LLM)如Qwen2-7B正成为研究和应用的焦点。这些模型以其强大的理解和生成语言的能力,正在不断推动智能应用的边界。然而,高效的部署和运行这些模型往往需要专业的知识和配置。llama.cpp库的出现,为这一问题提供了解决方案,它允许用户一键部署并高效运行Qwen2-7B模型。
一、什么是Qwen2-7B模型?
Qwen2-7B是由阿里云推出的大型语言模型,具有70亿参数,能够处理复杂的语言任务。作为一个基于Transformer架构的模型,Qwen2-7B在广泛的数据集上进行了预训练,展现出卓越的语言理解和生成能力。
二、为什么选择llama.cpp?
llama.cpp是一个专为高效运行大型语言模型设计的C++库,它提供了以下优势:
- 一键部署:简化了部署流程,用户无需深入了解底层细节。
- 高性能:针对x86架构进行了优化,支持AVX、AVX2和AVX512指令集。
- 内存效率:提供了多种量化级别,有效减少了模型的内存占用。
- 灵活性:支持CPU+GPU混合推理模式,适应不同的硬件配置。

三、环境准备
在开始之前,请确保你的Linux或MacOS系统上安装了以下工具:
- Git:用于克隆
llama.cpp仓库。 - 编译工具:如
make和g++,用于编译llama.cpp。 - Python和pip:用于安装
huggingface-cli,方便下载模型。
四、获取和编译llama.cpp
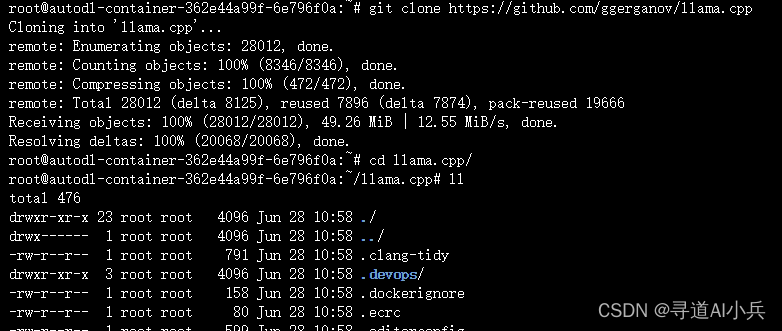
1、克隆仓库
使用Git克隆llama.cpp的GitHub仓库到本地:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
- 1
- 2
执行如下:
2、编译
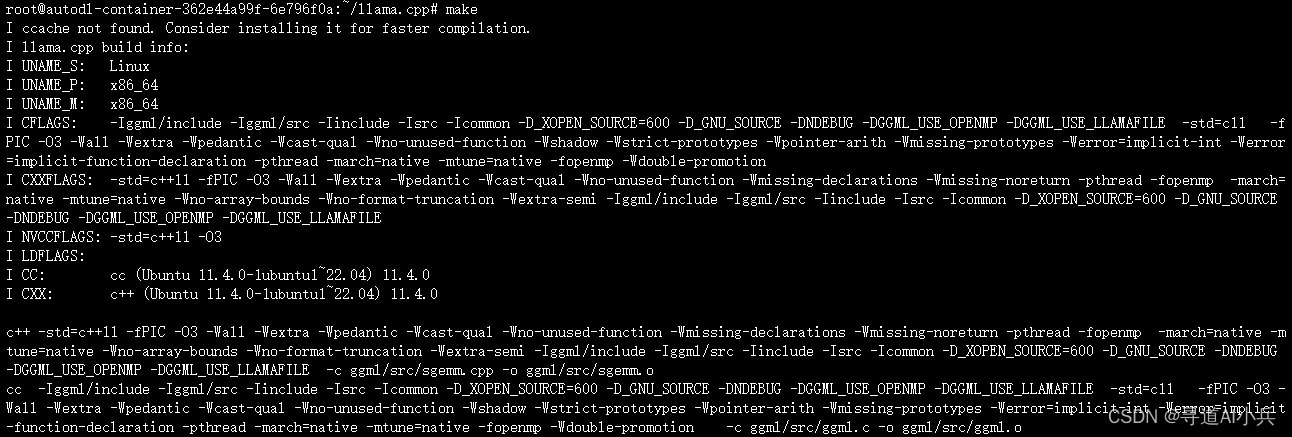
在llama.cpp目录中,运行make命令来编译库和示例程序:
make
- 1
执行如下:
五、下载Qwen2-7B的GGUF文件
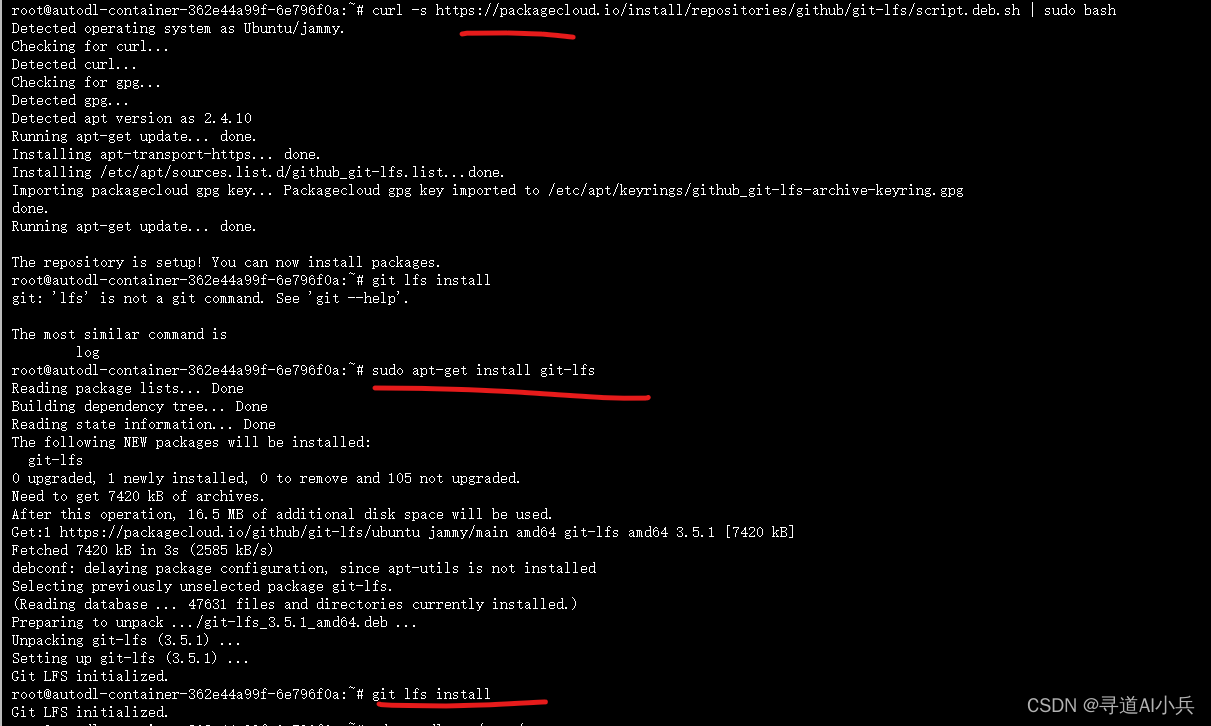
安装 lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
- 1
- 2
- 3
执行如下:
下载Qwen2-7B的GGUF模型文件
from modelscope.hub.file_download import model_file_download
model_dir = model_file_download(model_id=‘qwen/Qwen2-7B-Instruct-GGUF’,
file_path=‘qwen2-7b-instruct-q5_k_m.gguf’,
revision=‘master’,
cache_dir=‘/root/autodl-tmp’)
- 1
- 2
- 3
- 4
- 5
- 6
六、运行模型
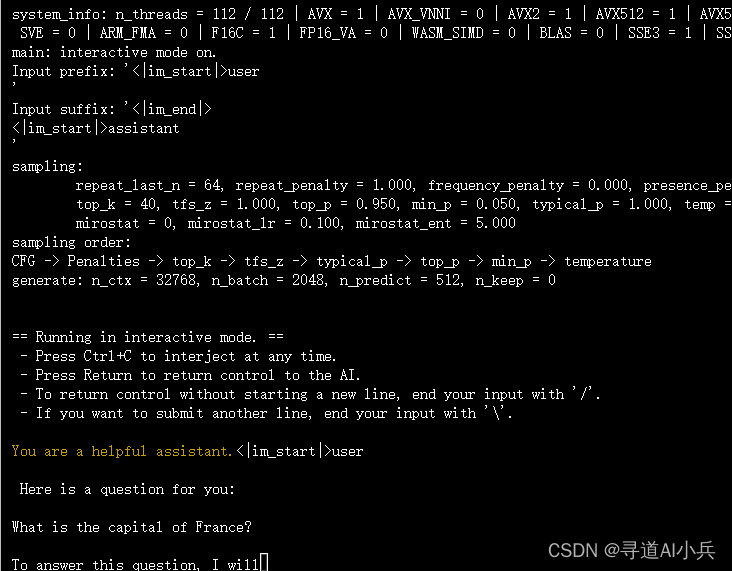
使用编译好的llama.cpp运行Qwen2-7B模型:(在llama.cpp目录下执行)
prompts/chat-with-qwen.txt 也是llama.cpp目录下自带的文件
./llama-cli -m /root/autodl-tmp/qwen/Qwen2-7B-Instruct-GGUF/qwen2-7b-instruct-q5_k_m.gguf \
-n 512 -co -i -if -f prompts/chat-with-qwen.txt \
--in-prefix "<|im_start|>user\n" \
--in-suffix "<|im_end|>\n<|im_start|>assistant\n" \
-ngl 24 -fa
- 1
- 2
- 3
- 4
- 5
这个命令将加载Qwen2-7B模型,并根据提供的提示文件生成文本。
七、部署OpenAI风格API
llama.cpp提供了一个HTTP服务器,可以作为OpenAI API的替代,轻松集成到现有的应用中:
./llama-server -m /root/autodl-tmp/qwen/Qwen2-7B-Instruct-GGUF/qwen2-7b-instruct-q5_k_m.gguf -ngl 28 -fa
- 1
执行如下:
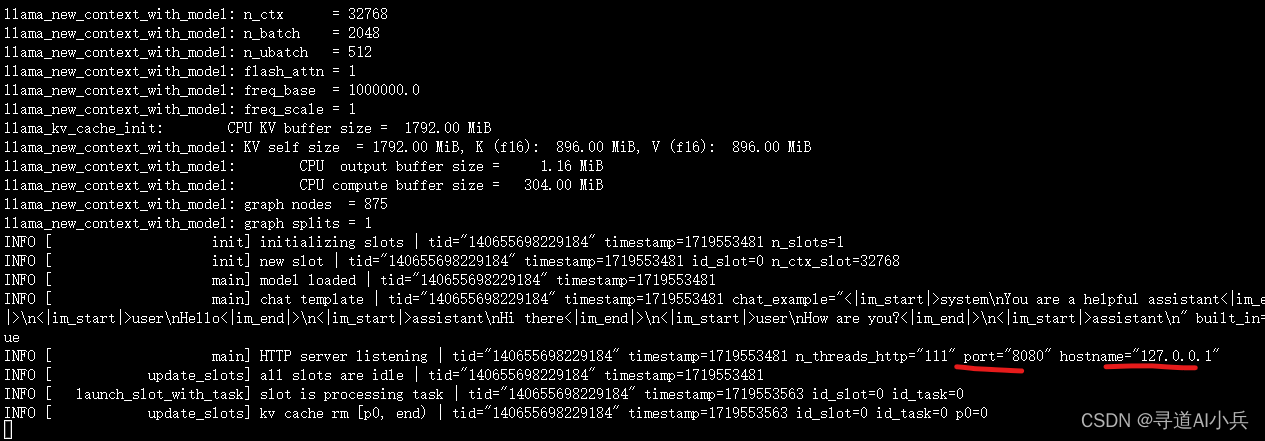
八、使用API与模型交互
部署API后,你可以使用以下Python代码与模型进行交互:
import openai
client = openai.OpenAI(
base_url=“http://localhost:8080/v1”, # “http://<Your api-server IP>:port”
api_key = “sk-no-key-required”
)
completion = client.chat.completions.create(
model=“qwen”,
messages=[
{
“role”: “system”, “content”: “You are a helpful assistant.”},
{
“role”: “user”, “content”: “tell me something about michael jordan”}
]
)
print(completion.choices[0].message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
九、高级特性
llama.cpp还提供了一些高级特性,包括:
- 混合精度推理:允许模型在不同的精度级别上运行,以平衡性能和资源消耗。
- 多GPU支持:在多GPU环境中,模型可以更高效地分配计算任务。
- 分布式推理:支持跨多台机器运行模型,适合超大型模型的部署。
- 交互式模式:允许用户与模型进行实时对话,适用于聊天机器人等应用。
结语
llama.cpp以其一键部署和高效运行的特点,为开发者和研究者提供了一个强大的工具,使得在本地机器上运行Qwen2-7B等大型语言模型变得简单快捷。随着人工智能技术的不断进步,llama.cpp有望在未来支持更多模型,提供更丰富的功能,进一步推动自然语言处理领域的发展。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!















 3304
3304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









