








1.3.第2部分 - 关联映射
我们映射了一个持久化实体类到一张数据库表,让我们在这个基础上添加一些类关联关系,首先,我们为这个应用添加相关人员信息,并且储存他们参与的事件列表。
1.3.1.映射Person类
这个Person类很简单:
public class Person {
private Long id;
private int age;
private String firstname;
private String lastname;
public Person() {}
// Accessor methods for all properties, private setter for 'id'
}
创建一个新映射文件,名叫Person.hbm.xml(不要忘记顶部的DTD定义):
< class name ="events.Person" table ="PERSON" >
< id name ="id" column ="PERSON_ID" >
< generator class ="native" />
</ id >
< property name ="age" />
< property name ="firstname" />
< property name ="lastname" />
</ class >
</ hibernate-mapping >
最后,将新映射加入Hibernate的配置文件:
现在,我们在这两个实体之间建立一个关联。显然,人员可以参与事件,而且事件都有参与的人,我们必须去面对的设计问题是:方向性、多重性以及集合行为。
1.3.2.单向的基于集合(Set)的关联
我们将要为Person类添加一个events的集合,这样我们可以轻松的访问Person的Events,而不需要执行一个额外的查询,只需要调用aPerson.getEvents()方法就可以了。我们使用一个Java Collection,一个Set,因为一个Collection不会保存两个同样的元素,并且我们不关心这些元素的排序。
我们需要一个使用Set实现的单向的、多值关联,让我们使用Java来实现它,然后进行映射。
private Set events = new HashSet();
public Set getEvents() {
return events;
}
public void setEvents(Set events) {
this .events = events;
}
}
在我们进行关系关联以前,从另外一个角度考虑下,显然,我们可以保持这种单向,或者,我们可以在Event对象上创建另外一个Collection集合,如果想要达到双向都可以访问的目的,例如anEvent.getParticipants(),从功能角度来看,这是没有必要的。因为你总是可以执行一个明确的查询,来取得一个event对象的关联对象(Person),这是设计者留给用户的选择,但从这个讨论来讲,有一点是明确的,那就是两边都有对方的引用,我们称之为“多对多”关联,所以,我们使用Hibernate的多对多映射。
< id name ="id" column ="PERSON_ID" >
< generator class ="native" />
</ id >
< property name ="age" />
< property name ="firstname" />
< property name ="lastname" />
< set name ="events" table ="PERSON_EVENT" >
< key column ="PERSON_ID" />
< many-to-many column ="EVENT_ID" class ="events.Event" />
</ set >
</ class >
Hibernate支持所有类型的聚集映射,,
这个数据映射的数据库图解如下:
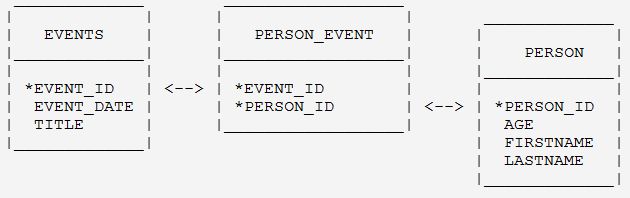
1.3.3.让关联工作起来
我们在EventManager在添加一个新方法,以将person和event对象一起保存:
Session session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Person aPerson = (Person) session.load(Person. class , personId);
Event anEvent = (Event) session.load(Event. class , eventId);
aPerson.getEvents().add(anEvent);
session.getTransaction().commit();
}
当查询出一个Person对象和一个Event对象以后,使用常规的集合处理方法,简单的修改person对象的集合变量,正如你看到的这样,这里没有另外执行update()和save()方法,Hibernate会自动检测集合变量是否已改变需要进行更新,这个功能叫做自动脏数据检测(automatic dirty checking),你也可以通过修改对象的名称或日期变量来使用这个功能。只要对象处于持久化(persistent)状态,亦即,绑定在某个Hibernate会话之上(例如:刚刚被加载或保存),Hibernate会检测对象的任何改变并使用“滞后写入”的机制(write-behind fashion)执行SQL。同步线程同步内存中的对象和数据库数据,通常情况下会在处理的后阶段,称作flushing。在我们的代码,工作单元以数据库事务的commit(或rollback)结束,thread配置项为CurrentSessionContext定义的。
你当然可能在不同的工作单元加载person和event,或者你在一个会话之外修改一个对象,这时它不在持久状态(如果它在持久之前,我们称这个状态为分离的),你甚至可以修改一个分离的对象:
Session session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Person aPerson = (Person) session
.createQuery( " select p from Person p left join fetch p.events where p.id = :pid " )
.setParameter( " pid " , personId)
.uniqueResult(); // Eager fetch the collection so we can use it detached
Event anEvent = (Event) session.load(Event. class , eventId);
session.getTransaction().commit();
// End of first unit of work
aPerson.getEvents().add(anEvent); // aPerson (and its collection) is detached
// Begin second unit of work
Session session2 = HibernateUtil.getSessionFactory().getCurrentSession();
session2.beginTransaction();
session2.update(aPerson); // Reattachment of aPerson
session2.getTransaction().commit();
}
Update()方法的调用让一个分离的对象重新进入持久状态,你可以说它又和新的工作单元绑定了,因此当在一个分离状态的时候,你对它所做的任何改变都可以被保存到数据库,包括对之所做的所有改变(新增或删除)。
好了,这些先走可能没多大用,但它是一个很重要的概念,你可以将它用在你自己的应用中。现在,先完成这个练习,添加一个新的action到EventManager的main方法,并且在命令行运行之。如果你需要person和event的标识id,需要save()方法返回它(你可能要修改我们之前的方法来返回这个标识id):
Long eventId = mgr.createAndStoreEvent( " My Event " , new Date());
Long personId = mgr.createAndStorePerson( " Foo " , " Bar " );
mgr.addPersonToEvent(personId, eventId);
System.out.println( " Added person " + personId + " to event " + eventId);
这是两个对等类和两个实体之间关联的一个例子,如前所述,除此之外还有其他类型的关联类型,通常“不太重要”。正如一些你已经看到的,比如一个int或者一个String。我们把它成为值类型(value types),它们的实例依赖于一个特定的实体。这些类型的实例既没有自己的标识,也无法在实体之间共享(两个persons类无法引用同一个firstname对象,即便它们的firstname相同)。当然,不单单是JDK里的值类型(实际上,在一个Hibernate应用中,所有的JDK类都被认为是一个值类型),你也可以自己写一个单独的类,例如Address、MonetaryAmount等等。
你也可以设计一个值类型的集合,这从概念上和一个实体引用的集合是很不相同的,但在Java中看起来似乎一样。
1.3.4. 值集
我们为Person实体类增加了一个值类型对象集合,我们打算存储email地址,所以我们使用的是String类型,集合使用的Set类型。
public Set getEmailAddresses() {
return emailAddresses;
}
public void setEmailAddresses(Set emailAddresses) {
this .emailAddresses = emailAddresses;
}
映射:
< key column ="PERSON_ID" />
< element type ="string" column ="EMAIL_ADDR" />
</ set >
和我们之前所做的映射不同的地方是element部分,告诉Hibernate该聚集不含有对另外一个实体的引用,而是一些类型为String的元素集合(小写的string名称告诉你这是一个Hibernate映射类型/转换器),Set节点的table属性依然表示的是此集合所对应的数据库表,key节点定义了聚集表中的外键列名,element节点的column属性定义了字符串数据实际被存储的列名。
看一下更新后的数据库结构:

从上图可以看到,关联表的主键实际上是复合主键,使用了两个列。这也说明了每个人不可以拥有两个相同Email地址,这也是我们为什么使用Java Set的原因。
现在我们可以尝试着为该关联表添加些数据了,就像我们之前做的将persons和events关联起来那样,Java代码是一样的:
Session session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Person aPerson = (Person) session.load(Person. class , personId);
// The getEmailAddresses() might trigger a lazy load of the collection
aPerson.getEmailAddresses().add(emailAddress);
session.getTransaction().commit();
}
此时我们没有使用一个Fectch查询去初始化一个collection,因此,对一个getter方法的调用将会触发另一个查询操作进行初始化,所以我们可以添加一个元素到集合,查看SQL日志,并且尝试使用一个积极的(eager)fetch操作进行优化。
1.3.5.双向关联
接下来,我们来对一个双向关联做映射,在Java中实现person和event双向关联,当然,数据库结构并不进行任何改变,还是多对多的关系。一个关系数据库比一个网络编程语言更加的灵活可变,我们不用担心任何事,像查询方向——数据可以使用任何可能的方式进行查询得到。
首先,添加一个collection类型的变量participants到Event类:
public Set getParticipants() {
return participants;
}
public void setParticipants(Set participants) {
this .participants = participants;
}
在Event.hbm.xml中,也将另一端进行映射:
< key column ="EVENT_ID" />
< many-to-many column ="PERSON_ID" class ="events.Person" />
</ set >
正如你看到的这样,在Event.hbm.xml和Person.hbm.xml这两个文件中都是一般的set映射。注意看,key节点和many-to-may节点的column属性,在两个映射文章中是互换的,这里最重要的新增内容是Event映射文件中,set节点的inverse=”true”属性,它的具体含义是当需要查询两者之间关联的具体数据时,Hibernate应该从另外一方——Person.class为主取得,只要你看下这两个实体之间的双向连接是如何建立的就会很容易理解了。
1.3.6.双向链接关系
首先,记住Hibernate并不改变正常的Java语法,我们在之前的一个单向例子中是如何在Person和Event之间创建一个连接的?我们添加了一个Event的实例到Person实例中的event引用collection变量。所以,很显然,如果我们想要让该关联双向可用,我们在另一头也必须如此做,添加一个Person的引用到Event对象中的collection,这种“在两边设置连接”是绝对必要的,并且你永远都不要忘记这样做。
很多开发者使用保护模式,并且创建一个连接管理方法,来进行正确的设置,例如,在Person中:
return events;
}
protected void setEvents(Set events) {
this .events = events;
}
public void addToEvent(Event event) {
this .getEvents().add(event);
event.getParticipants().add( this );
}
public void removeFromEvent(Event event) {
this .getEvents().remove(event);
event.getParticipants().remove( this );
}
注意,现在get和set方法是protected的了,这允许相同包内以及其子类然而可以访问这些方法,但防止其他的对象对该collection进行无序的直接访问,你可能在其他地方也要做类似设置。
Inverse映射属性怎样呢?对你并且对Java来说,一个双向的连接是一个简单的事实,就是在双方正确的设置引用(references)。然而Hibernate缺乏足够的信息来争取的组织SQL插入和更新语句(来避免违反约束),并且需要协助来正确地处理双向关联。设置关联的一边inverse就是告诉Hibernate忽略它,将它认为是另一方的一个镜像(mirror),这些在Hibernate解决当将一个方向性导航模型转换到SQL数据库结构时所有问题的时候是必需的。你必须记住的规则很简单:所有的双向连接需要一方设为inverse,在一个一对多(one-to-many)关联中,是多的一方,在一个多对多(many-to-many)关联中,可以任选一边,没有任何区别。
下面我们来做一个小的Web应用。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
英文原文版权归原作者所有, 本译文转载请注明出处!
译者:abigfrog 联系:QQ:800736, MSN:J2EE@HOTMAIL.COM
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}