









1. Open
vSwitch介绍
1.1虚拟化网络架构图
1.2 Open
vSwitch功能介绍
2. 安装,启动,关闭
2.1 源码安装
2.2 apt安装
2.3 启动脚本
2.4 关闭脚本
2.5 virsh启动
3. 配置,使用
3.1流规则
3.2VLAN
3.3 sflow
3.4接入物理机
4. 遇到的问题
4.1找不到opevswitch_mod.ko和 brcompatd.ko内核模块怎么办?
4.2 Xen无法创建虚拟机?
4.3关于兼容模块brcompatd.ko
4.4 tap和vif的区别
4.5深入认识tap和tun
4.6当没有内核支持的时候,如何使用ovs?
4.7什么叫虚拟边缘网络?
4.8关于软交换(待续)
4.9网络设备虚拟化(待续)
4.10网桥能有IP么?
1.Open vSwitch介绍
1.1虚拟化网络架构图:

1.2 Open
vSwitch功能介绍:
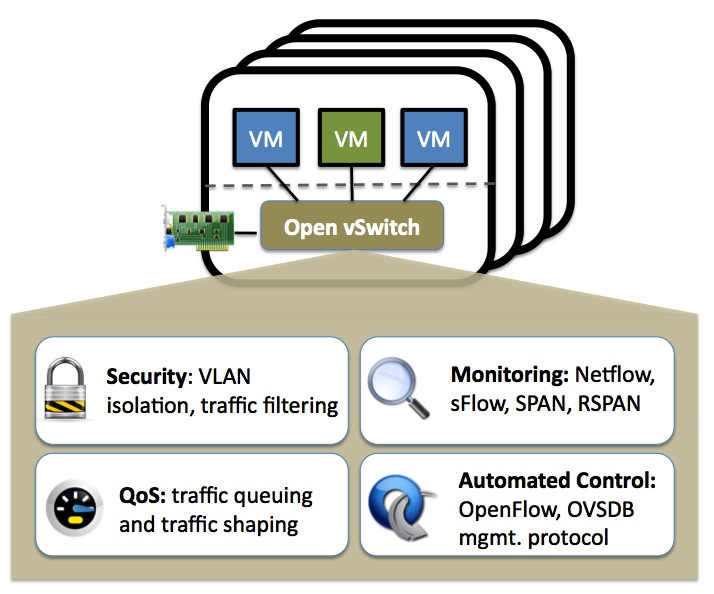
Open vSwitch的目标,是做一个具有产品级质量的多层虚拟交换机。通过可编程扩展,可以实现大规模网络的自动化(配置、管理、维护)。它支持现有标准管理接口和协议(比如netFlow,sFlow,SPAN,RSPAN,CLI,LACP,802.1ag等,熟悉物理网络维护的管理员可以毫不费力地通过Open vSwitch转向虚拟网络管理)。
下文将会介绍几个配置实例:安全方面的VALN,流量监控方面的sflow,访问控制方面的openflow。
2. 安装,启动,关闭
2.1 源码安装
从官方网站http://openvswitch.org/中下载Open vSwitch源代码包,最新版本可使用下面的链接:http://openvswitch.org/releases/openvswitch-1.1.0pre2.tar.gz,下载完后输入以下命令解压
[root@localhost ~]# tar –xzvf openvswitch-1.1.0pre2.tar.gz
进入解压后目录,输入以下命令配置Open vSwitch工程,生成Makefile文件。
[root@localhost ~]# ./configure --with-linux=/lib/modules/`uname -r`/build
–with- linux:生成内核模式的Open vSwitch时需指定的内核源码编译目录
指定Open
vSwitch的安装位置加参数:–prefix=/…
如有其他问题可参考源码根目录下的帮助文件:INSTALL.Linux
编译、链接、生成和安装Open vSwitch,命令如下,make install目录只安装Open vSwitch除内核模块外的其他所有模块,如ovs-vsctl、ovs-vswitchd、ovs-ofctl等
[root@localhost ~]# make [root@localhost ~]# make install
卸载原有虚拟网桥模块,命令如下,如果Xend正常启动,将自动加载linux虚拟网桥模块bridge.ko。
[root@localhost ~]# rmmod bridge
如果无法卸载,可用“lsmod”命令查看已加载的依赖于bridge的内核模块,并用“rmmod 模块名”卸载,常见的无法卸载的情况可通过预先执行下面两条命令解决。
[root@localhost ~]# /etc/init.d/iptables stop [root@localhost ~]# rmmod xt_physdev
加载Open
vSwitch内核模块openvswitch_mod.ko和linux虚拟网桥兼容模块brcompat_mod.ko
[root@localhost ~]# insmod openvswitch-1.1.0pre2/datapath/linux-2.6/openvswitch_mod.ko [root@localhost ~]# insmod openvswitch-1.1.0pre2/datapath/linux-2.6/brcompat_mod.ko
根据ovsdb模板vswitch.ovsschema创建ovsdb数据库ovs-vswitchd.conf.db,用于存储虚拟交换机的配置信息,只需第一次运行Open
vSwitch时创建
[root@localhost ~]# ovsdb-tool create /usr/local/etc/ovs-vswitchd.conf.db openvswitch-1.1.0pre2/vswitchd/vswitch.ovsschema
启动ovsdb数据库服务器,Open vSwitch虚拟网桥模块将通过ovsdb-server获得虚拟交换机配置信息,“—detach”表示以后台方式运行, ovsdb-server其他参数请参考“ovsdb-server –help”
[root@localhost ~]# ovsdb-server /usr/local/etc/ovs-vswitchd.conf.db --remote=punix:/usr/local/var/run/openvswitch/db.sock --remote=db:Open_vSwitch,manager_options --private-key=db:SSL,private_key --certificate=db:SSL,certificate --bootstrap-ca-cert=db:SSL,ca_cert --detach
初始化Open
vSwitch控制接口,以便用ovs-vsctl管理配置虚拟交换机
[root@localhost ~]#
ovs-vsctl –no-wait init
启动Open
vSwitch用户态模块,unix:后的文件为socket文件,为ovsdb-server监听的socket文件。
[root@localhost ~]#
ovs-vswitchd unix:/usr/local/var/run/openvswitch/db.sock –detach
启动linux原有虚拟网桥兼容模块用户态组件ovs-brcompatd,该模块必须在ovsdb-server和ovs-vswitchd启动后才能启动。
[root@localhost ~]# ovs-brcompatd --pidfile --detach
2.2 apt-get安装
$apt-get install openvswitch-*
注意:使用deb安装openvswitch-datapath*也是需要依赖/lib/modules/`uname -r`/build,否则无法编译内核模块
2.3 启动脚本:(见ovs-start.sh)
#!/bin/bash #./configure --with-l26=/lib/modules/`uname -r`/build #echo "close applications or modules depending on bridge.ko" #if service iptables status|grep running > /dev/null 2>&1; then #/etc/init.d/iptables stop; #fi #if lsmod|grep xt_physdev > /dev/null 2>&1; then #rmmod xt_physdev; #fi echo "remove module bridge" if lsmod|grep bridge > /dev/null 2>&1; then if rmmod bridge >/dev/null 2>&1; then echo "bridge.ko removed">/dev/null else echo "Failed to remove kernel module bridge" exit fi fi echo "clean obsolete socket files in /var/run/openvswitch/" for i in `ls /var/run/openvswitch/|grep "ctl$"`; do rm -f /var/run/openvswitch/$i; done echo "insert kernel module openvswitch_mod.ko" if lsmod|grep bridge > /dev/null 2>&1; then echo "bridge is already running">/dev/null; elif lsmod | grep openvswitch_mod >/dev/null 2>&1;then echo "module openvswitch_mod exist" else if insmod 、、/var/lib/dkms/openvswitch/1.4.0/3.2.0-30 \ -generic/x86_64/module/openvswitch_mod.ko ; then echo "openvswitch_mod.ko inserted"; else echo "failed to insert openvswitch_mod.ko"; exit fi fi #first use this when install ovsdb-tool create /usr/local/etc/ovs-vswitchd.conf.db \ /var/lib/dkms/openvswitch/1.4.0/build/vswitchd/vswitch.ovsschema #before starting ovs-vswitchd ,wo need to start its config database echo "start daemon ovsdb-server" if ps -ef|grep -E "[[:digit:]][[:space:]]+ovsdb-server" >/dev/null 2>&1; then echo "ovsdb-server is already running">/dev/null; else ovsdb-server "/usr/local/etc/ovs-vswitchd.conf.db" --remote=punix:/var/run/openvswitch/db.sock --remote=db:Open_vSwitch,manager_options --private-key=db:SSL,private_key --certificate=db:SSL,certificate --bootstrap-ca-cert=db:SSL,ca_cert --detach ; fi #initialize the db ovs-vsctl --no-wait init #start vswitch itself echo "start daemon ovs-vswitchd" if ps -ef|grep -E "[[:digit:]][[:space:]]+ovs-vswitchd" >/dev/null 2>&1; then echo "ovs-vswitchd is already running" >/dev/null; else ovs-vswitchd unix:/var/run/openvswitch/db.sock --detach ; fi # echo "start daemon ovs-brcompatd" if lsmod | grep brcompat_mod >/dev/null 2>&1; then echo "module ovs-brcompatd exist" else if insmod /var/lib/dkms/openvswitch/1.4.0/3.2.0-30-generic/x86_64/module/brcompat_mod.ko; then echo "module ovs-brcomptd inserted" else echo "failed to insert module ovs-brcomptd" exit fi fi ovs-brcompatd --pidfile --detach #-vANY:console:EMER unix:/usr/local/var/run/openvswitch/db.sock ; echo "add and configure bridge ovsbr0" if ovs-vsctl list-br|grep ovsbr0 > /dev/null 2>&1; then echo "bridge ovsbr0 already exists" >/dev/null else ovs-vsctl add-br ovsbr0 fi ifconfig ovsbr0 up #ifconfig ovsbr0 172.16.18.230/16 #echo "attach all interfaces to bridge ovsbr0" #if /usr/sbin/brctl show |grep peth0 > /dev/null 2>&1; then #echo "peth0 is added" >/dev/null; #else #ovs-vsctl add-port xenbr0 peth0 > /dev/null 2>&1; #for i in `ifconfig|grep vif|awk '{print $1}'`; #do #ovs-vsctl add-port ovsbr0 $i > /dev/null 2>&1; #done #fi #echo "Open vSwitch started successfully" #ovs-vsctl add-port xenbr0 peth0 /etc/init.d/networking restart
2.4 关闭脚本:(见ovs-stop.sh)
#!/bin/sh kill `cd /var/run/openvswitch && cat ovs-brcompatd.pid ovsdb-server.pid ovs-vswitchd.pid ovs-controller.pid ovs-monitor-ipsec.pid`
使用libvirt/virsh启动虚拟机:
阅读源代码目录下的INSTALL.Libvirt。
将原来的配置文件中的下列部分:
... <interface type='network'> <mac address='52:54:00:71:b1:b6'/> <source network='default'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface> ...
改成这个样子:
... <interface type='bridge'> <mac address='52:54:00:71:b1:b6'/> <source bridge='ovsbr'/> <virtualport type='openvswitch'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface> ...
3. 配置
3.1 ovs-vsctl使用:
添加名为br0的网桥
ovs-vsctl
add-br br0
删除名为br0的网桥
ovs-vsctl
del-br br0
列出所有网桥
ovs-vsctl
list-br
判断网桥br0是否存在
ovs-vsctl
br-exists br0
列出挂接到网桥br0上的所有网络接口
ovs-vsctl
list-ports br0
将网络接口eth0挂接到网桥br0上
ovs-vsctl
add-port br0 eth0
删除网桥br0上挂接的eth0网络接口
ovs-vsctl
del-port br0 eth0
列出已挂接eth0网络接口的网桥
ovs-vsctl
port-to-br eth0
3.2 流规则:
每条流规则由一系列字段组成,分为基本字段、条件字段和动作字段三部分:
基本字段包括生效时间duration_sec、所属表项table_id、优先级priority、处理的数据包数n_packets,空闲超时时间idle_timeout等,空闲超时时间idle_timeout以秒为单位,超过设置的空闲超时时间后该流规则将被自动删除,空闲超时时间设置为0表示该流规则永不过期,idle_timeout将不包含于ovs-ofctl dump-flows brname的输出中。
条件字段包括输入端口号in_port、源目的mac地址dl_src/dl_dst、源目的ip地址nw_src/nw_dst、数据包类型dl_type、网络层协议类型nw_proto等,可以为这些字段的任意组合,但在网络分层结构中底层的字段未给出确定值时上层的字段不允许给确定值,即一条流规则中允许底层协议字段指定为确定值,高层协议字段指定为通配符(不指定即为匹配任何值),而不允许高层协议字段指定为确定值,而底层协议字段却为通配符(不指定即为匹配任何值),否则,ovs-vswitchd 中的流规则将全部丢失,网络无法连接。其中dl是datalink的缩写,nw是network的缩写,tp是transport的缩写。
动作字段包括正常转发normal、定向到某交换机端口output:port、丢弃drop、更改源目的mac地址mod_dl_src/mod_dl_dst等,一条流规则可有多个动作,动作执行按指定的先后顺序依次完成。
实例:
1.
查看虚拟交换机ovsbr0的信息:
| $ovs-ofctl show ovsbr0 |
2.
查看ovsbr0上各交换机端口的状态
| $ovs-ofctl dump-ports ovsbr0 |
3.
查看ovsbr0上的所有流规则
| $ovs-ofctl dump-flows ovsbr0 |
4.
丢弃从2号端口发来的所有数据包
| $ovs-ofctl add-flow ovsbr0 |
注意:此处的in_port是指虚拟网卡(vif,tap)的号码,并非传输层的端口号(如www:80,ftp:21,22等),通过ovs-ofctl show ovsbr0可查得端口号,传输层的端口号有tp_src/tp_dst指定。
5.
删除条件字段中包含in_port=2的所有流规则
| $ovs-ofctl del-flows ovsbr0 in_port=2 |
6.
丢弃所有收到的数据包
| $ovs-ofctl add-flow ovsbr0 |
注意: (1)流规则中可包含通配符和简写形式,任何字段都可等于*或ANY,
(2)简写形式为将字段组简写为协议名,目前支持的简写有ip,arp,icmp,tcp,udp,与流规则条件字段的对应关系如下:
dl_type=0×0800 <=> ip
dl_type=0×0806 <=> arp
dl_type=0×0800,nw_proto=1 <=> icmp
dl_type=0×0800,nw_proto=6 <=> tcp
dl_type=0×0800,nw_proto=17 <=> udp
(1.1.0 即以后版本支持)
dl_type=0x86dd. <=> ipv6
dl_type=0x86dd,nw_proto=6. <=> tcp6
dl_type=0x86dd,nw_proto=17. <=> udp6
dl_type=0x86dd,nw_proto=58. <=> icmp6
3.3 测试VALN:
参考文章:
http://openvswitch.org/support/config-cookbooks/vlan-configuration-cookbook/
配置实例:
在两台xen+openvswitch的服务器上172.16.19.206和172.16.19.208,启动四个虚拟机(206:VM3, VM4; 208:VM1, VM2 ),结构图如下所示:
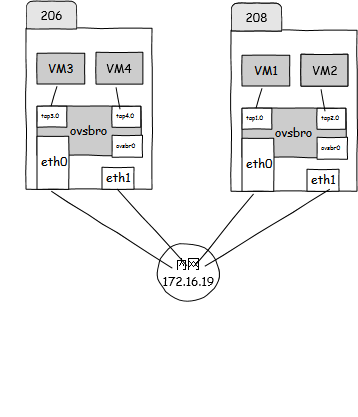
配置如下:
1.在206上:
Ifconfig eth1
172.16.19.206/16 up
(1)创建网桥:
Ovs-vsctl add-br ovsbr0
#注意创建网桥之后,会在网桥上创建同名的端口ovsbr0,类型为internal,用于给网桥配置IP方便管理等。
(2)让网桥ovsbr接管eth0:
Ovs-vsctl add-port
ovsbr0 eth0
(3)配置网桥的IP:
Ifconfig eth0 0.0.0.0
Ifconfig ovsbr0
172.16.19.230/16 up
(4)创建虚拟机:
Virsh create VM1.xml
Virsh create VM2.xml
(5)查看网桥:
Ovs-vsctl show ovsbr0
会发现ovsbr0下面会有6个端口ovsbr0,eth0,tap1.0,tap2.0,vif1.0,vif2.0。(关于tap和vif参见其他内容,在本服务器上起作用的是tap,具体哪个起作用还需要测试)
2. 在208上,配置类似:
3.配置VLAN
(1)VM1, VM2属于VLAN1
Ovs-vsctl set port
tap1.0 tag=1
Ovs-vsctl set port tap2.0
tag=1
之VM1和VM2之间可以互ping,
(2)VM1属于VLAN1,
VM2属于VLAN1
Ovs-vsctl set port
tap1.0 tag=1
Ovs-vsctl set port tap2.0
tag=2
之VM1和VM2之间无法互ping,
(3)VM1, VM2, VM3,VM4属于VLAN1
208上:
Ovs-vsctl set port
tap1.0 tag=1
Ovs-vsctl set port
tap1.0 tag=1
206上:
Ovs-vsctl set port tap3.0
tag=1
Ovs-vsctl set port tap4.0
tag=1
之VM1, VM2, VM3,VM4之间可以互ping,
(4)VM1, VM3,属于VLAN1,
VM2,VM4属于VLAN2
208上:
Ovs-vsctl set port
tap1.0 tag=1
Ovs-vsctl set port
tap2.0 tag=2
206上:
Ovs-vsctl set port
tap3.0 tag=1
Ovs-vsctl set port
tap4.0 tag=2
在我的试验中,VM1, VM2,
VM3,VM4之间无法互ping,而理论上应该是VM1和VM3可以互ping,VM2和VM4之间可以互ping。目前还不知道什么原因造成的。待续。。。
3.4 Sflow:
1.下面先来关注几个问题:
(1) Sflow是什么呢? 与sflow相应的有一个Netflow。 sFlow和Netflow聽起來很相似,但在骨子裡卻不一樣。Netflow會針對所有流經的網路封包去取得其特徵,包含Source IP
address、Destination IP address、Source
port for UDP or TCP, 0 for other protocols、Destination
port for UDP or TCP, type and code for ICMP, or 0 for other protocols、IP protocol、Ingress interface (SNMP ifIndex)、IP Type of Service這些資訊。
由於Netflow會對所有流經的封包進行處理,若網路流量極大時,Netflow所提供的資料量亦會隨之增加,若資料量太大,後端分析引擎可能會不堪負荷,進而影響資料判讀時的正確性。
sFlow的作法和Netflow不同,sFlow以取樣的方式取出資料的摘要,使用者可以自訂其取樣大小及取樣週期,即使流經大量網路流量,但sFlow經取樣後的資料相對於Netflow而言會大量的減少,如此一來就可以兼顧資料正確性並確保後端分析引擎處理能力。
在實務上,sFlow較常運用於高速網路的環境,也是因為其具有此特性的關係。sFlow提供的資料格式在之後實作的階段會加以展示,在此不多作說明。
在實作時,會遭遇到許多的困難,這是因為sFlow僅在部分設備上提供,也不像Netflow,在Linux中可使用nfdump套件來產生符合其格式的流量。
(2) 是不是open
vswitch支持了sflow就不支持了netflow?不是,在其官方的介绍里(上文的官方图片),可以看到也是支持netflow的。目前我的做法是,使用sflowtool将sflow转换为netflow。
2.配置实例:
目标: 流量导出,并可以使用snort,tcpdump对流量进行监控和分析。
配置图如下所示:

在208服务器上安装xen和openvswitch,并启动两个虚拟机VM1,VM2。不在赘述。
(1)
配置sflow流量导出
| #!/bin/sh COLLECTOR_IP=172.16.18.18 COLLECTOR_PORT=6343 AGENT_IP=eth1 HEADER_BYTES=128 SAMPLING_N=2 POLLING_SECS=1 ovs-vsctl – |
这是配置sflow的一个脚本,现在解释其中的意思:
COLLECTOR_IP是指进行流量监控的机器,本次实例中是指172.16.18.18
COLLECTOR_PORT=6343 是指把流量发到COLLECTOR_IP的6343端口
AGENT_IP=eth1是指把流量从本地的eth1端口发出去
并指定每1秒poolling一次,每次的取样频率为64(即,每隔64个Packet取样一次)。
(2)
转换sflow
现在让VM1(ip:x.x.x241) ping VM2(ip: x.x.x242)
执行上面那个脚本,在18.18机器上用snort会看到206发到18.18的包,而不会看到241和242之间通信的数据包。因为241和242通信的数据被sflow封装起来之后再发给18.18.如果想看到这个数据,需要将sflow转换为snort和tcpdump的格式,具体命令如下:
| $sflowtool 或者 $sflowtool |
(3)
sflowtool的使用:
-f可以转发到另一台机器上
| $sflowtool –p 6343 –t –f x.x.x.x/6343 |
-c可以将sflow转换为netflow
其他的使用信息,参见 man sflowtool
3.5 Ovs接入物理机器
目的:是open vswitch不仅可以控制虚拟机(VM1, VM2),也可以控制物理机器(PY1)
配置图如下:

具体配置如下:
(1)
由网桥ovsbr0接管eth0和eth2。
Ovs-vsctl add-port
ovsbr0 eth0
Ovs-vsctl add-port
ovsbr0 eth2
(2)
Eth0接外网,eth1接hub
(3)
在208上启动两个虚拟机VM1,VM2。并配置IPx.x.x.241, x.x.x.242
(4)
配置物理机PY1的IP为, x.x.x.250
(5)
现在已经联通了,下面测试一下,可以有250 ping 241, 启动sflow便可观测到相应的信息。
4. 遇到的问题
4.1找不到opevswitch_mod.ko和 brcompatd.ko内核模块怎么办?
编译安装和apt安装都需要编译内核模块,而编译内核模块需要安装linux-header,即需要/lib/modules/`uname -r`/build,下的内容。请确保系统已安装linux-header。
4.2
Xen无法创建虚拟机?
查看xen日志文件,并判断错误原因
| $tail |
(1)
如果出现以下错误:
| $tail -n 100 domid: 44 -c config qemu tap44.0 ovsbr0 can’t add tap44.0 to /etc/xen/scripts/qemu-ifup: Could not |
需要加载open vswitch的bridge的兼容模块brcompatd.ko,即
| $insmod |
(2)一切都配置妥当的时候,我还遇到个错误,导致虚拟机无法正常启动,是因为xml配置文件中<interface>部分写在了<disk>的前面,改过来之后就好了。
4.3
关于兼容模块brcompatd.ko
看看官方给出的解释:http://openvswitch.org/cgi-bin/gitweb.cgi?p=openvswitch;a=blob_plain;f=INSTALL.bridge;hb=HEAD
This file documents how Open vSwitch may be used as a drop-in
replacement for a Linux kernel bridge in an environment that includes
elements that are tightly tied to the Linux bridge tools
(e.g. "brctl") and architecture. We recommend directly using the
management tools provided with Open vSwitch rather than these
compatibility hooks for environments that are not tightly tied to the
Linux bridging tools; they are more efficient and better reflect the
actual operation and status.。。。。
大致意思是有很多工具,软件等等和Linux kernel bridge的关联比较紧密,比如我们使用的xen-4.1。上一小节提到xen无法创建,错误里面有句话是” /etc/xen/scripts/qemu-ifup: could not launch network script”,而查看这个脚本,里面的内容是:
| #!bin/sh Echo |
| Echo Ifconfig Brctl addif $2 $1 |
此处便发现这个脚本使用Brctl,而其依赖于linux bridge。
4.4
tap和vif的区别
PV虚机只有一个vifX.N,而HVM虚机不安装PV
Driver的时候会有两个网络接口vifX.N和tapX.N,而且实际上使用的是tapX.N。HVM虚机安装PV
Driver并重启后,tapX.N会消失,使用vifX.N(若不重启还是使用tapX.N)
tap interfaces -> qemu-emulated NICs (realtek model by default),
used
when no PV drivers installed (using OS’ own driver for that model)
vif interfaces (the one that you can rename) -> xen network frontend
NICs, used when you have PV drivers installed (like GPLPV,
http://meadowcourt.org/downloads/)
the vif is a
virtual interface that works with
pv drivers in domU. The tap is a Qemu interface that is used with HVMs that don’t have pv drivers.
So, if you start a HVM domU, you’ll
have the vif that Xen creates and the tap that
Qemu creates, if pv drivers are
available, then once they are loaded Domu uses them and the tap goes away, but if not then both
remain, but only the tap interface is
being used. Obviously, if you need more detailed explaination, then I’m of no further use.:)
4.5
深入认识tap和tun
官方FAQ: http://vtun.sourceforge.net/tun/faq.html
TUN时点对点的设备,tap表示以太网设备的,做为虚拟网卡驱动,Tun/tap驱动程序的数据接收和发送并不直接和真实网卡打交道,而是通
过用户态来转交。在linux下,要实现核心态和用户态数据的交互,有多种方式:可以通用socket创建特殊套接字,利用套接字实现数据交 互;通过proc文件系统创建文件来进行数据交互;还可以使用设备文件的方式,访问设备文件会调用设备驱动相应的例程,设备驱动本身就
是核心态和用户态的一个接口,Tun/tap驱动就是利用设备文件实现用户态和核心态的数据交互。
当没有内核模块支持的时候,Open vSwitch完全运行于用户态,ovs的数据通路有tun来实现。
参见4.6,当没有内核支持的时候,如何使用ovs。
为了对tap/tun有更深入的体会,下面将观看tun源代码,并使用tun写个程序。
tun源代码可从此处获得http://vtun.sourceforge.net/tun/index.html。其头文件是”if_tun.h”,这个适用于编程时用的。另外要编译tun.c,将tun作为内核模块加载进去。下面是tun.c中几段代码
/* file_operations 结构体,将正常的文件操作对应于tun相应的函数,这样可以像操作文件一样操作tun*/ static struct file_operations tun_fops = { owner: THIS_MODULE, llseek: tun_chr_lseek, read: tun_chr_read, write: tun_chr_write, poll: tun_chr_poll, ioctl: tun_chr_ioctl, open: tun_chr_open, release:tun_chr_close, fasync: tun_chr_fasync }; static struct miscdevice tun_miscdev= { TUN_MINOR, "net/tun", &tun_fops }; /*c语言中的 __init 保证该函数只执行一次 */ int __init tun_init(void) { printk(KERN_INFO "Universal TUN/TAP device driver %s " "(C)1999-2000 Maxim Krasnyansky\n", TUN_VER); if (misc_register(&tun_miscdev)) { printk(KERN_ERR "tun: Can't register misc device %d\n", TUN_MINOR); return -EIO; } return 0; } void tun_cleanup(void) { misc_deregister(&tun_miscdev); } /*加载tun模块*/ module_init(tun_init); module_exit(tun_cleanup);
下面应用一下tun,写个程序体会一下(tun源码中的一个example)
#include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <sys/time.h> #include <sys/types.h> #include <linux/if_tun.h> #define max(a,b) ((a)>(b) ? (a):(b)) int main(int argc, char *argv[]) { char buf[1600]; int f1,f2,l,fm; fd_set fds; if(argc < 2) { printf("Usage: bridge tap|tun\n"); exit(1); } sprintf(buf,"/dev/%s%d",argv[1],0); f1 = open(buf, O_RDWR); sprintf(buf,"/dev/%s%d",argv[1],1); f2 = open(buf, O_RDWR); fm = max(f1, f2) + 1; ioctl(f1, TUNSETNOCSUM, 1); ioctl(f2, TUNSETNOCSUM, 1); while(1){ FD_ZERO(&fds); FD_SET(f1, &fds); FD_SET(f2, &fds); select(fm, &fds, NULL, NULL, NULL); if( FD_ISSET(f1, &fds) ) { l = read(f1,buf,sizeof(buf)); write(f2,buf,l); } if( FD_ISSET(f2, &fds) ) { l = read(f2,buf,sizeof(buf)); write(f1,buf,l); } } }
4.6 当没有内核支持的时候,如何使用ovs?
参考官方文档:
http://openvswitch.org/cgi-bin/gitweb.cgi?p=openvswitch;a=blob_plain;f=INSTALL.userspace;hb=HEAD
当没有内核模块支持的时候,ovs可以完全在用户空间运行,当然要损失一部分性能。下面介绍做法。
出了内核模块openvswitch_mod.ko和brcompatd.ko模块的编译和安装省略之外,其他部分正常。
如4.5中提到的用户态和核心态的转换有那么几种方式,ovs的用户态的转换需要内核的tun/tap驱动可以正常使用。查看/sys/class/misc/tun中是否存在,如果没有存在加载相应模块 ”modprobe tun”
tun 设备也必须存在于/dev/net/tun目录下面。如果没有则创建之,创建的方法如下:
mkdir /dev/net mknod /dev/net/tun c 10 200
为了在用户空间使用ovs,需要创建一个网桥br0,并设置其datapath_type为”netdev”:
ovs-vsctl add-br br0 ovs-vsctl set bridge br0 datapath_type=netdev ovs-vsctl add-port br0 eth0 ovs-vsctl add-port br0 eth1 ovs-vsctl add-port br0 eth2 ovs-vswitchd
将会创建一个和网桥br0同名的 tap设备作为网桥的本地interface。
4.7 什么叫虚拟边缘网络?
一般来说:虚拟边缘网络是指如何对虚拟机的流量进行转发和策略控制。由于虚拟机是共驻于宿主机上,因此有两个选择,一个是在主机侧直接用软件来实现,一个是把它发出去到硬件上做完决策后再发回来。
4.8 关于软交换(待续)
详细中文介绍可以参考这里d
http://hi.baidu.com/cattydong/item/952033177ada9df6ddeeca2d
http://hi.baidu.com/cattydong/item/304c153be4149bf197f88d43
关于这方面的内容,open vswitch的官方网站也有两篇论文
http://openvswitch.org/papers/hotnets2009.pdf
http://openvswitch.org/papers/dccaves2010.pdf
4.9网络设备虚拟化(待续)
Virtio
I/O 虚拟化
虚拟 LANs
硬件加速
4.9网桥能有IP么?
可以有,目前我知道的一个作用是便于远程控制。
Ovs-vsctl add-br ovsbr0 或者brctl addbr br0
在创建网桥的时候,还会创建一个同名的端口ovsbr0或者br0,可以在这个上面配置IP。dd















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









