




 本文介绍了一种车牌字符识别的数据集构建方法,通过预处理车牌图片并使用CNN进行训练,实现高精度的字符识别。文章分享了数据集获取方式,并提供了Keras训练代码示例。
本文介绍了一种车牌字符识别的数据集构建方法,通过预处理车牌图片并使用CNN进行训练,实现高精度的字符识别。文章分享了数据集获取方式,并提供了Keras训练代码示例。
数据集
dataset/char
1.因为我做的是车牌字符识别,所以木有 I,O
2.为什么有O的文件夹呢?我放入的是非字符图片,作为负样本,防止分隔点等杂质误判
3.每个文件夹里的字符图像是经过预处理的单个字符图片,尺寸20*20
PS:这些数据我怎样得到的呢?首先收集大量含车牌的车辆图片,提取车牌-->分割字符-->处理
可参考我的另一篇:【opencv】车牌定位及倾斜较正
如果你对上面提到的不感兴趣,将处理好的分享给你~
链接:https://pan.baidu.com/s/1ZZS-w7msgWTH1OCXfjUGPQ
提取码:g7br


训练(Keras)
import skimage.io
import skimage.color
import skimage.transform
import matplotlib.pyplot as plt
import numpy as np
import os
import random
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import cv2
DATASET_DIR = './dataset/'
classes = os.listdir(DATASET_DIR + "/char/")
data = []
for cls in classes:
files = os.listdir(DATASET_DIR + "/char/"+cls)
for f in files:
img = skimage.io.imread(DATASET_DIR + "/char/"+cls+"/"+f)
img = skimage.color.rgb2gray(img)
data.append({
'x': img,
'y': cls
})
random.shuffle(data)
X = [d['x'] for d in data]
y = [d['y'] for d in data]
ys = list(np.unique(y))
y = [ys.index(v) for v in y]
x_train = np.array(X[:int(len(X)*0.8)])
y_train = np.array(y[:int(len(X)*0.8)])
x_test = np.array(X[int(len(X)*0.8):])
y_test = np.array(y[int(len(X)*0.8):])
batch_size = 128
num_classes = len(classes)
epochs = 10
# input image dimensions
img_rows, img_cols = 20, 20
def extend_channel(data):
if K.image_data_format() == 'channels_first':
data = data.reshape(data.shape[0], 1, img_rows, img_cols)
else:
data = data.reshape(data.shape[0], img_rows, img_cols, 1)
return data
x_train = extend_channel(x_train)
x_test = extend_channel(x_test)
input_shape = x_train.shape[1:]
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train2 = keras.utils.to_categorical(y_train, num_classes)
y_test2 = keras.utils.to_categorical(y_test, num_classes)
#模型搭建按你喜欢来~
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train2,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test2))
score = model.evaluate(x_test, y_test2, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
model.save_weights('char_cnn.h5') #输出模型我设置的网络如下,可以按照你自己的改一哈~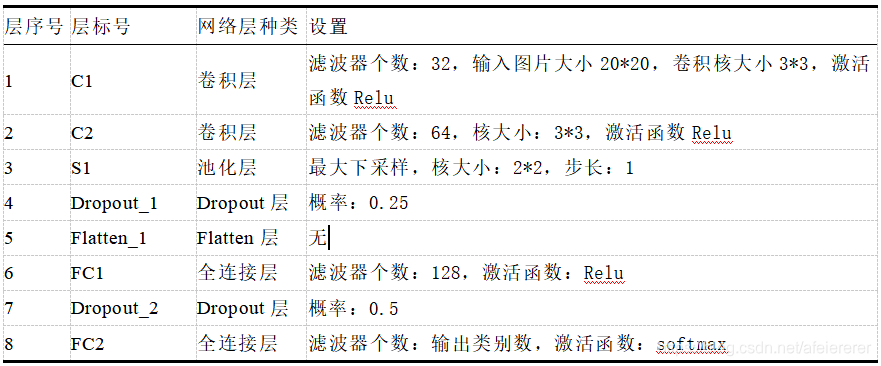
char_cnn.h5就是输出的模型啦
测试
import cv2
import keras
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
class CNN():
def __init__(self, num_classes, fn):
self.model = Sequential()
self.model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=[20, 20, 1]))
self.model.add(Conv2D(64, (3, 3), activation='relu'))
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(Dropout(0.25))
self.model.add(Flatten())
self.model.add(Dense(128, activation='relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(num_classes, activation='softmax'))
self.model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
self.model.load_weights(fn)
def predict(self, samples):
r = self.model.predict_classes(samples)
return r[0]
if __name__ == '__main__':
list_char = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z']
char_model = CNN(35, "char_cnn.h5")
img_test=cv2.imread("test.jpg",0)
img_test=img_test.reshape(-1,20,20,1)
res=char_model.predict(img_test)#返回索引 0:0 1:1 。。。。10:A
print(list_char[res])
输入:![]() 输出:4
输出:4
给个赞嘛~~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









