






Java精选面试题 (微信小程序): 5000+ 道面试题和选择题, 真实面经 , 简历模版 ,包含Java基础、并发、JVM、线程、MQ系列、Redis、Spring系列、Elasticsearch、Docker、K8s、Flink、Spark、架构设计、大厂真题等,在线随时刷题!
Apache tika是Apache开源的一个文档解析工具。Apache Tika可以解析和提取一千多种不同的文件类型(如PPT、XLS和PDF)的内容和格式,并且Apache Tika提供了多种使用方式,既可以使用图形化操作页面(tika-app),又可以独立部署(tika-server)通过接口调用,还可以引入到项目中使用。
本文演示在spring boot 中引入tika的方式解析文档。如下:
引入依赖
在spring boot 项目中引入如下依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-bom</artifactId>
<version>2.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
</dependency>创建配置
1. 将tika-config.xml文件放在resources目录下。tika-config.xml文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<encodingDetectors>
<encodingDetector class="org.apache.tika.parser.html.HtmlEncodingDetector">
<params>
<param name="markLimit" type="int">64000</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.UniversalEncodingDetector">
<params>
<param name="markLimit" type="int">64001</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.Icu4jEncodingDetector">
<params>
<param name="markLimit" type="int">64002</param>
</params>
</encodingDetector>
</encodingDetectors>
</properties>推荐程序员摸鱼地址:
https://www.yoodb.com/slack-off/home.html
2. 创建配置类MyTikaConfig
import java.io.IOException;
import java.io.InputStream;
import org.apache.tika.Tika;
import org.apache.tika.config.TikaConfig;
import org.apache.tika.detect.Detector;
import org.apache.tika.exception.TikaException;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.Parser;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import org.xml.sax.SAXException;
/**
* tika配置类
*/
@Configuration
public class MyTikaConfig {
@Autowired
private ResourceLoader resourceLoader;
@Bean
public Tika tika() throws TikaException, IOException, SAXException {
Resource resource = resourceLoader.getResource("classpath:tika-config.xml");
InputStream inputStream = resource.getInputStream();
TikaConfig config = new TikaConfig(inputStream);
Detector detector = config.getDetector();
Parser autoDetectParser = new AutoDetectParser(config);
return new Tika(detector, autoDetectParser);
}
}Tika类中提供了文芳detect、translate和parse功能, 在项目中通过注入TIka, 就可以使用了。
在项目使用
配置完成后在项目中可以通过注入TIka即可完成文档的解析。如下图所示:
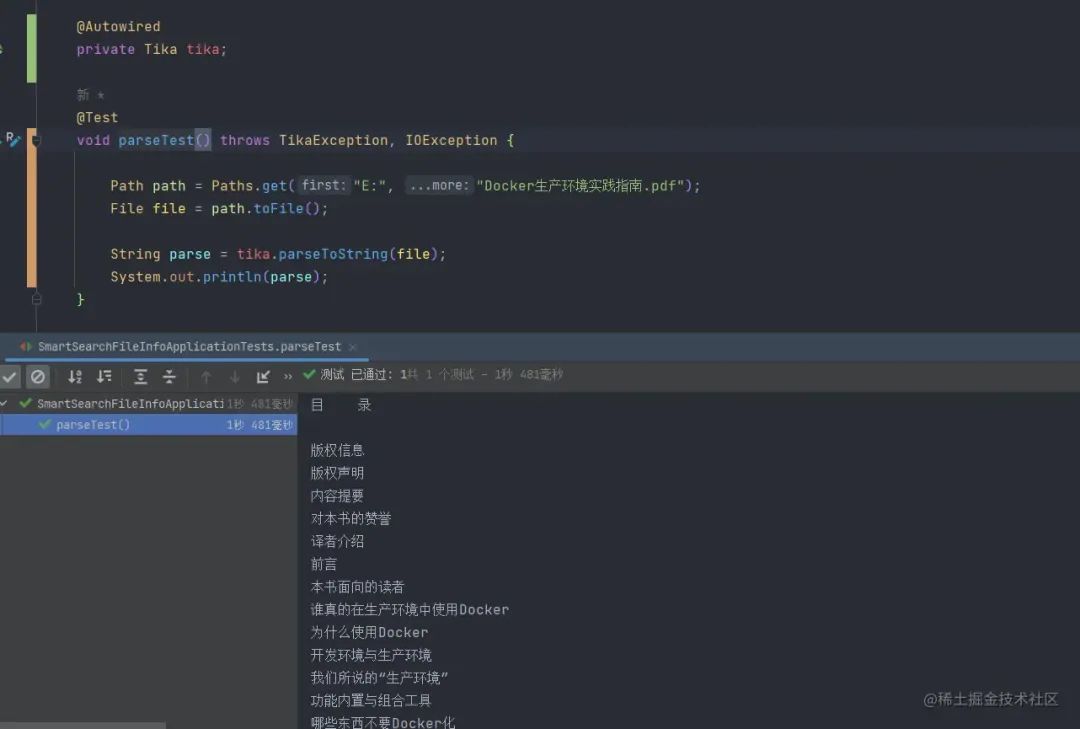
作者 | 不可食用盐
来源 | https://juejin.cn/post/7252159509848899640
公众号“Java精选”所发表内容注明来源的,版权归原出处所有(无法查证版权的或者未注明出处的均来自网络,系转载,转载的目的在于传递更多信息,版权属于原作者。如有侵权,请联系,笔者会第一时间删除处理!
最近有很多人问,有没有读者交流群!加入方式很简单,公众号Java精选,回复“加群”,即可入群!
Java精选面试题(微信小程序):3000+道面试题,包含Java基础、并发、JVM、线程、MQ系列、Redis、Spring系列、Elasticsearch、Docker、K8s、Flink、Spark、架构设计等,在线随时刷题!
------ 特别推荐 ------
特别推荐:专注分享最前沿的技术与资讯,为弯道超车做好准备及各种开源项目与高效率软件的公众号,「大咖笔记」,专注挖掘好东西,非常值得大家关注。点击下方公众号卡片关注。
点击“阅读原文”,了解更多精彩内容!文章有帮助的话,点在看,转发吧!














 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









