







一 大模型演变与概念
1.1 人工智能
我们常说人工智能,然而人工智能是一个非常广泛的领域,涵盖了多种技术和方法,包括但不限于机器学习、自然语言处理、计算机视觉、专家系统、机器人学等。
人工智能旨在创建能够模拟人类智能行为的系统或软件。它包括感知、推理、学习、决策和语言理解等多种能力,目标是让计算机能够像人类一样思考和行动。
在人工智能领域,有两个和人工智能紧密相关的概念,分别是机器学习和深度学习,这两个概念相信各位小伙伴也经常听别人说起。
我们可以这样简单理解三者之间的关系:
- 深度学习是机器学习的一个分支,机器学习是人工智能的一个核心领域。
1.2 机器学习
机器学习是人工智能的一个核心子领域,它专注于开发算法和模型,使计算机能够从数据中自动学习和改进。简单来说, 机器学习的目标是让计算机通过数据“学会”某种规律或模式。
机器学习又分为多种不同的算法,如监督学习、无监督学习以及强化学习。
1.2.1 监督学习
想象一下,你正在教一个小孩子学习如何识别苹果和香蕉。你会怎么做呢?
你可能会拿一些苹果和香蕉的图片,然后指着图片告诉孩子:“这是苹果,这是香蕉。”慢慢地,孩子就会学会,以后再看到类似的图片时,就能自己分辨出这是苹果还是香蕉。
监督学习就是类似的过程,只不过是在教计算机学习。
监督学习是一种让计算机通过**“学习”来解决问题的方法**。具体来说,就是给计算机很多已经“标注好答案”的例子,让它从中找出规律,然后用这些规律去解决新的问题。
比如想要判断一张图片是猫还是狗。那么我们需要给计算机很多猫和狗的图片,并且告诉它哪些是猫,哪些是狗。计算机学会了区分猫和狗的特征,以后再看到新的图片时,就能自己判断出是猫还是狗。
监督学习的两个关键点
- 有“答案”的数据:
- 就像教孩子时,每张图片都有“这是苹果”或“这是香蕉”的答案,监督学习需要很多已经标注好的数据来教计算机。
- 让计算机自己找规律:
- 计算机不是死记硬背,而是通过这些例子找出规律。比如,它会发现“有长尾巴的是猫,有短尾巴的是狗”,然后用这些规律去判断新的图片。
1.2.2 无监督学习
想象一下,你给一个小孩子一堆玩具,但没有告诉他这些玩具的名字或者分类方式。孩子自己会去观察这些玩具,把它们分成几组,比如把所有的小汽车放在一起,把所有的洋娃娃放在一起,或者把所有红色的玩具放在一起。孩子是根据自己的观察和判断来分组的,而不是按照别人告诉他的规则。
无监督学习就是类似的,只不过是在让计算机自己去发现数据中的规律和结构。
无监督学习是一种让计算机自己探索数据的方法。和监督学习不同,无监督学习没有“正确答案”可以参考。计算机需要自己去观察数据,找出其中的模式、规律或者分组方式。
比如现在有一堆照片,但没有告诉计算机照片的内容。计算机自己观察这些照片,比如把所有风景照放在一起,把所有人物照放在一起。计算机自己发现了照片的分类方式,而不是别人告诉它的。
假设你是一家超市的老板,想了解顾客的购买习惯,但你没有预先设定的分类方式。你可以用无监督学习来分析顾客的购买数据:顾客的购买记录,比如买了什么商品、花了多少钱、购物的频率等。然后让计算机自己分析这些数据,发现一些规律,比如把顾客分成“经常购买生鲜的顾客”“喜欢买零食的顾客”“偶尔购物的顾客”等。在这个过程中是计算机自己发现了顾客的分群方式,而不是你事先告诉它的。
无监督学习的两个关键点
- 没有“答案”的数据:
- 和监督学习不同,无监督学习没有标注好的“正确答案”。计算机需要自己去探索数据,发现其中的规律。
- 发现隐藏的结构:
- 计算机的任务是找出数据中的模式或分组方式。比如,它可能会发现数据中有几个“簇”,或者某些特征之间有某种关系。
1.2.3 强化学习
想象一下,你正在教一只小狗学会“坐下”这个动作。你会怎么做呢?每次小狗成功坐下时,你就会给它一块小零食作为奖励,如果它没有坐下,你可能就不会给奖励。慢慢地,小狗会发现,只要它坐下,就会得到奖励,于是它就会越来越频繁地坐下。
强化学习就是类似的过程,只不过是在教计算机或者机器人学习。
强化学习是一种让计算机或机器人通过“试错”来学习的方法。它就像一个正在探索世界的小孩子,通过不断地尝试,看看哪些行为会得到奖励,哪些行为会受到惩罚,然后根据这些反馈来调整自己的行为,最终学会如何做出最好的选择。 小狗学会了“坐下”。
强化学习的三个关键要素
- 环境(Environment):
- 这就是小狗所处的世界,比如客厅、院子等。在强化学习中,环境就是计算机或机器人需要与之互动的场景。
- 动作(Action):
- 这是小狗的行为,比如坐下、跑开、叫等。在强化学习中,动作是计算机或机器人可以采取的行为。
- 奖励(Reward):
- 这是小狗得到的零食或者表扬。在强化学习中,奖励是一个信号,告诉计算机或机器人它的行为是好是坏。
强化学习的特点
- 试错学习:
- 就像小狗通过不断尝试来学习坐下,强化学习也是通过试错来学习。机器人会不断尝试不同的动作,看看哪些能得到奖励。
- 奖励驱动:
- 奖励是强化学习的核心。机器人会根据奖励信号来调整自己的行为,目标是最大化奖励。
- 动态调整:
- 机器人会根据每次的反馈动态调整自己的策略。如果一个动作总是能得到奖励,它就会更多地选择这个动作。
机器学习常见算法是这些,在这些算法里边,一般是从监督学习开始。。
1.3 深度学习
深度学习是一种让计算机通过“多层思考”来学习和解决问题的方法。它模仿了人脑的工作方式,就像大脑中有许多神经元一层一层地处理信息一样,深度学习也通过多层的“神经网络”来处理数据,从而发现数据中的复杂规律。
想象一下,你有一堆水果,包括苹果、香蕉和橙子。你希望让计算机学会区分这些水果。传统的方法可能需要你手动告诉计算机很多规则,比如“苹果是红色的”“香蕉是长条形的”“橙子是圆形的”。但深度学习不需要这样,它就像一个聪明的学生,自己通过观察和学习来发现水果的特征。
在深度学习中,你只需要给计算机这些照片,并告诉它每张照片对应的水果名称(比如“这是苹果”“这是香蕉”)。然后,计算机自己会通过多层的“思考”来学习如何区分这些水果。
多层思考
深度学习的核心是“神经网络”,它就像一个有很多层的筛子,每一层都在处理数据的一部分,逐步提取更复杂的特征。
-
第一层:计算机可能会先学会识别简单的形状和颜色,比如“这里有圆形的东西”“这里有红色的东西”。
-
第二层:它会进一步组合这些简单特征,比如“这是一个红色的圆形物体”“这是一个黄色的长条物体”。
-
第三层:它会根据前面的分析,判断出这是哪种水果,比如“这是一个苹果”“这是一个香蕉”。
深度学习的神奇之处在于,你不需要手动告诉计算机每一条规则,它会自己从数据中学习。比如,它可能会发现“苹果通常是红色或绿色的,表面光滑”“香蕉是黄色的,形状细长”“橙子是橙色的,表面有点凹凸”。
深度学习的特点
-
自动学习:计算机自己从数据中学习规律,不需要手动编写复杂的规则。
-
多层结构:通过多层的“思考”,逐步提取数据中的复杂特征。
-
强大的能力:深度学习可以处理非常复杂的问题,比如识别各种形状和颜色的水果,甚至在有干扰的情况下也能正确分类。
这就是在人工智能领域我们常见的一些概念和术语,以及这些这些概念之间的一些关系。
简单来说:
-
人工智能是最高层次的概念,涵盖了所有与智能相关的技术和应用。人工智能是深度学习和机器学习的最终目标,即通过这些技术实现智能化的系统和应用。
-
机器学习是实现人工智能的关键技术之一,通过数据驱动的方法让计算机自动学习和改进。机器学习是人工智能的核心实现手段,为人工智能提供了学习和适应的能力。
-
深度学习是机器学习的一个高级分支,专注于通过深度神经网络解决复杂问题,它为机器学习提供了更强大的模型和算法。
1.4 生成式人工智能
生成式人工智能(Generative Artificial Intelligence)可以理解为一种“会创作的AI”。它通过学习大量数据(如文字、图片、音频等),掌握这些数据的规律,然后像人类艺术家一样创造出全新的内容。例如:
-
写文章:ChatGPT 可以根据你的要求生成一篇故事或邮件草稿;
-
画图:Midjourney 能根据“一只戴帽子的猫在月球上跳舞”这样的描述生成一幅画;
-
作曲:AI 可以模仿贝多芬的风格创作一段音乐。
它的核心能力是模仿+创新——既不是完全复制已有内容,也不是随机乱造,而是基于学习到的模式生成合理的新内容。
生成式AI是深度学习的“高级应用“。
-
传统深度学习:主要用于“分析”任务,比如人脸识别、语音转文字;
-
生成式 AI:利用深度学习技术实现“创造”,例如:
-
生成对抗网络(GAN):两个 AI 互相“较量”,一个生成假图片,另一个判断真假,最终生成逼真内容;
-
Transformer 模型:像 ChatGPT 这类大语言模型,通过分析海量文本学会写作。
总结下,深度学习是“学会观察世界”,生成式 AI 则是“用学到的知识创作新事物”。
二 大模型训练
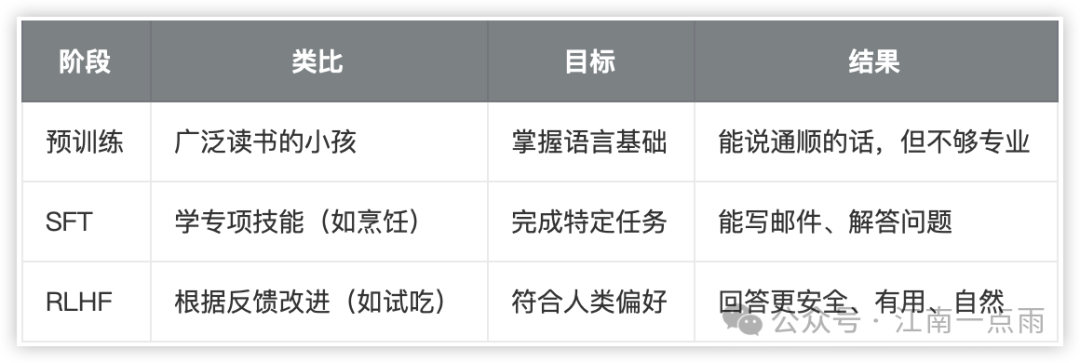
整体上来说,大模型的训练可以分为三个阶段:
-
预训练(Pre-training)
-
监督微调(SFT,Supervised Fine-Tuning)
-
基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)
这三个阶段分别是啥意思呢,我们逐个来看。
2.1 预训练
预训练是大模型的基础学习阶段,通过“阅读”海量文本(如书籍、网页)学习语言的通用规律,类似人类通过广泛阅读积累常识。
预训练的流程一般是这样:
-
数据输入:模型学习互联网上的文本(如维基百科、新闻、小说),目标是预测句子中的下一个词。
-
学习能力:掌握语法、逻辑、简单推理(如“猫吃鱼”的因果关系)。
-
结果:形成“基础模型”(如GPT-3),能生成通顺但可能不准确的回答。
预训练的模型具备基础能力,知识面广,但是缺乏深度,能回答一些简单的基础问题,但是知识推理能力不足。此时的大模型相当于只会成语接龙。比如此时你问他埃菲尔铁塔在哪里,它可能回答你故宫在哪里,而不会回答法国,因为还缺乏推理能力。
这个阶段就像我们从小所接受的基础教育,语文、数学、英语、物理、化学、地理、历史、生物等等都要学习,广泛涉猎。
2.2 监督微调(SFT)
监督微调是在预训练基础上,用标注数据教模型完成具体任务(如回答问题、写邮件)。
监督微调的流程一般是这样:
-
数据输入:使用人工标注的指令-答案对(如“翻译这句话:Hello→你好”)。
-
学习能力:模型学会理解指令并生成符合要求的答案。
-
结果:模型能执行特定任务(如客服对话、法律文书生成)。
这个阶段就像是我们读大学,选择一个专业精修,大学毕业之后,我们就具备了某一个领域的专业能力。
2.3 基于人类反馈的强化学习(RLHF)
基于人类反馈的强化学习是指通过人类对答案的评分,让模型学会生成更符合人类偏好的回答(如更安全、更礼貌)。
RLHF 的流程一般是这样:
-
训练奖励模型:人类对多个答案排序(如 A 比 B 更好),模型学会预测哪些回答更受欢迎。
-
强化学习优化:模型生成答案后,根据奖励模型的评分调整策略,类似“试错学习”。
-
结果:模型输出更人性化(如避免偏见、减少错误)。
这个就像是我们工作之后,搬砖的过程中,可能受到领导的表扬,也可能受到领导的批评,这些就是反馈,在这个过程中我们学会总结经验,知道了如何让自己的工作更出色,得到更多表扬。
总结一下,这三个阶段的关系就是这样的:
最后再举个简单的例子,比如我们想利用大模型训练一个客服,那么我们的流程可能是这样:
-
预训练:模型读遍互联网,学会中文语法和常见问题(如“如何退款”)。
-
SFT:用标注数据训练它回答:“退款流程是:1.登录账号→2.提交申请…”。
-
RLHF:用户给回答打分,模型学会把“请联系管理员”优化为“我帮您转接人工服务”。
通过这三个阶段,大模型从“书呆子”成长为“专业助手”,既能理解需求,又能用人类喜欢的方式回应。
三 大模型特点与分类
3.1 大模型的特点
参数规模庞大
大模型通常包含数十亿至数万亿参数(如GPT-4参数达1.8万亿),远超传统模型。这种规模使其具备强大的表征能力,能够捕捉语言、图像等数据中的复杂模式。例如,GPT-3通过 1750 亿参数实现对自然语言的深度理解。
海量数据训练
训练数据量通常达 TB 甚至 PB 级别,涵盖多语言文本、图像、音频等多模态信息。例如,GPT-3 使用 45TB 原始数据(清洗后 570 GB),通过自监督学习从海量数据中提炼通用知识。
高算力需求
训练需数百至上千 GPU 集群,耗时数周至数月。以 GPT-3 为例,需 3640 PFLOP·天的算力,相当于 512 张 A100 GPU 连续运行 1 个月。
涌现能力
当模型规模突破临界值(如千亿参数)时,会突然展现小模型不具备的复杂能力,例如逻辑推理、跨领域知识融合。例如,DeepSeek 模型在参数规模扩展后,意外展现出对数学难题的求解能力。
多任务泛化
单一模型可同时处理翻译、摘要、问答等任务,无需针对每项任务单独设计架构。例如,Gemini 模型能同时处理文本、图像、音频输入并生成代码。
3.2 大模型的分类
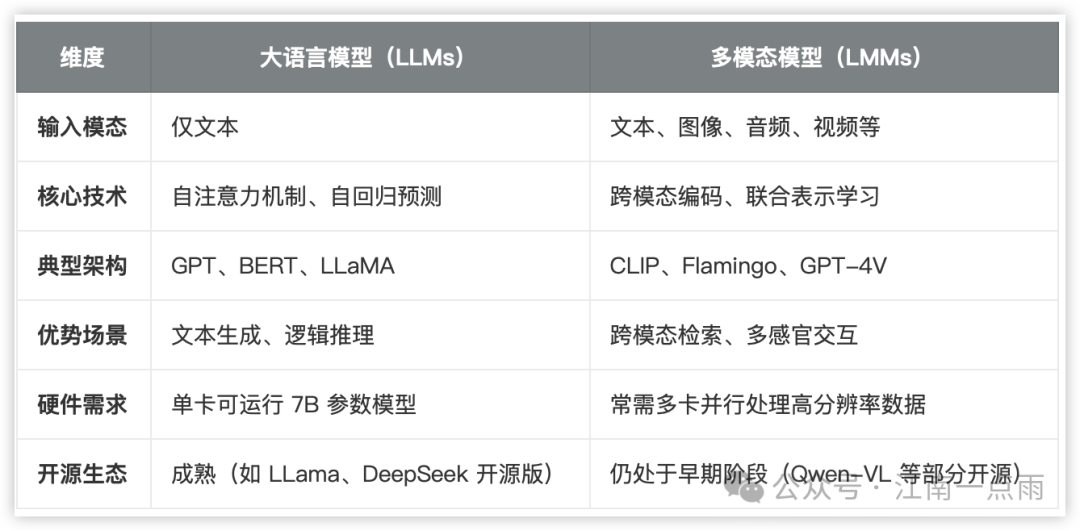
3.2.1 大语言模型(Large Language Models, LLMs)
大语言模型是专注于文本模态的深度学习系统,通过海量文本数据预训练掌握语言规律,具备文本生成、理解、推理三大核心能力。典型代表包括 GPT 系列、DeepSeek R1、文心一言等。
大语言模型常见的应用场景如下:
-
内容生成:新闻写作、营销文案、代码自动生成(如 GitHub Copilot);
-
智能交互:客服对话、虚拟助手(如 Siri、小爱同学);
-
知识服务:知识问答、文献摘要、舆情分析。
由于模态单一,LLM 仅处理文本数据,无法直接理解图像、音频等信息;同时,因为 LLM 依赖训练数据时效,所以通常需结合 RAG(检索增强生成)更新知识。
3.2.2 多模态模型(Large Multimodal Models, LMMs)
多模态模型是能同时处理文本、图像、音频、视频等多种数据模态的 AI 系统,通过跨模态对齐实现信息融合与协同推理。代表模型包括 GPT-4V、Gemini、Qwen-VL 等。
LMM 一些常见的应用场景如下:
-
医疗诊断:融合 CT 影像(视觉)、病理报告(文本)、患者语音(听觉)进行综合判断;
-
智能驾驶:同步处理摄像头画面、雷达点云、导航指令;
-
内容创作:图文混排广告设计、短视频脚本生成(如字节跳动豆包)。
总结下,LLM 和 LMM 对比如下:
四 大模型工作流程
这块我们简单看下大模型分词化和文本生成过程。
4.1 分词化(Tokenization)
分词化是将原始文本拆解为模型可处理的**最小语义单元(Token)**的过程,其核心作用包括:
-
降维处理:将无限可能的文本组合映射到有限词表(如 GPT-4 词表约 10 万 Token);
-
语义保留:通过子词拆分处理未登录词(如“量子计算”拆为“量子”+“计算”);
-
跨语言统一:中英文混合句如“给我一个 iPhone15 的测评”可拆为[“给”, “我”, “一个”, “iPhone”, “15”, “的”, “测”, “评”]。
4.1.1 主流分词方法

4.1.2 中文分词方法
中文分词就像给句子"拆积木",让电脑看懂汉字组合。常见的方法有这几种:
-
基于词典的分词:这是最常见的分词方法,就是根据一个预先定义好的词典来切分句子。比如"我爱北京天安门",系统会先找字典里有的词:“我”、“爱”、“北京”、“天安门”,咔咔拆成四个词。
-
基于统计的分词:这种方法会考虑词频,即某个词在大量文本中出现的频率。如果网上"北京天安门"总是连在一起出现,就算字典里没这个词,系统也会当它是个整体,拆成"北京天安门"一个词。
-
基于规则的分词:这种方法会根据一些特定的规则来分词,比如人名、地名、机构名等的识别规则。比如遇到人名会自动识别"张伟"是名字,地名就认"北京市"这种固定格式,遇到"北京天安门"可能直接当地名处理。
-
混合分词方法:实际应用中会把上面几种方法混着用。先基于词典的分词,剩下的用基于统计的分词,遇到人名地名再用基于规则的分词补刀,就跟做菜加各种调料似的。
-
子词粒度分词:遇到完全不认识的新词(比如网络热词"栓Q"),系统可能会硬拆成"栓"和"Q"。就像修东西时拆零件,虽然不知道整体是啥,先拆开再说。
最后不管怎么拆,系统都会把每个词换成数字编码(就像快递单号),电脑拿着这些号码就能处理文本了。不过要注意,不同分词工具就像不同的厨师,切出来的词块可能不太一样,没有绝对正确的切法,主要看用在哪里。反正核心目标就是帮电脑理解我们说的话!
4.1.3 分词的挑战与优化
-
拆分歧义:如“美国会通过法案”可能误拆为“美/国会”;
-
解决方案:预定义规则合并专有名词(如“美国会”整体保留)。
-
多语言混合:日语“今日の天气很好”需切换分词器;
-
优化策略:多语言词表或动态分词器切换。
-
专业术语处理:医学名词“α-突触核蛋白”需定制词表。
4.2 词表映射(Vocabulary Mapping)
4.2.1 为什么要词表映射
-
计算机只能计算数字,Token ID 就像快递单号,告诉系统每个词块的位置和含义。
-
模型会根据这些 ID,把词块转成向量(数学里的多维数组),再做后续分析。
4.2.2 映射流程
-
Token→ID 转换:
每个 Token 被映射为唯一整数 ID(如“咖”→12768,“啡”→23579); -
词向量嵌入:
通过 Embedding 矩阵将 ID 转换为稠密向量(如维度 768)。
4.2.3 词向量技术演进

4.2.4 映射中的关键问题
-
语义对齐:需确保相似 Token 在向量空间邻近(如“猫”与“犬”距离小于“猫”与“汽车”);
-
多模态扩展:图文混合输入时,词向量需与视觉特征对齐(如“黑猫”文本+图像置信度加权);
-
动态更新:OpenAI O1 专业版实时扫描新词出现频率,自动更新词表(如“量子奶茶”超阈值即保留)。
4.2.5 注意事项
-
同一个词,不同模型编号不同:比如 BERT 和 GPT 的词表不同,"我"的 ID 可能分别是 101 和 502。
-
未知词(OOV):如果遇到词表里没有的词(比如网络新词),可能会拆成子词(Subword)或标为 [UNK](未知符号)。
4.3 大模型文本生成过程
你可以把大语言模型想象成一个玩文字接龙的AI老司机,它的操作流程是这样的:
举个栗子🌰:
-
你开头说:“松哥的 Java 图书是”
-
AI 老司机立刻接话:“程序员必备的”(它觉得这词最可能跟上)
-
接着你把新句子拼成:“松哥的 Java 图书是程序员必备的”
-
AI 继续接龙:“实战宝典”(现在句子变成“…程序员必备的实战宝典”)
-
再接着它可能接:“从入门到精通全覆盖”(甚至可能自动优化成更顺溜的表达)


老司机的接龙秘籍:
-
看菜下饭:每次只盯着当前完整的句子(比如“松哥的 Java 图书是 XXX”),专注猜下一个最可能蹦出来的词。
-
越写越长:把新猜到的词粘到句子屁股后面,组成更长的句子,接着继续猜下下个词。
-
刹车条件:直到出现三种情况才会停:
-
憋出句号/感叹号(自然结束)
-
遇到暗号“”(相当于喊“停!”)
-
字数刷满(比如最多接 20 个词)
为什么说它像老司机?
-
经验值拉满:它读过全网海量技术文档,知道“程序员必备”后面接“实战宝典”比接“菜谱大全”更合理。
-
会自我修正:如果前面写“松哥的Java图书是程序员必备的的”,后面可能默默删掉多余“的的”。
-
可盐可甜:你说“写技术推荐”它就列知识点,你说“吹彩虹屁”它能夸“行业标杆级著作”,全看开头给的提示。
说白了:整个过程就像 AI 在玩超级加长版文字接龙,一边接词一边改稿,直到凑出一篇人模人样的推荐文案,这就是所谓的自回归。
好啦,先说这些吧,后面有空了我们继续聊。

















 7883
7883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









