






2.3.1简单类型
简单类型的变量直接分配内存。可以通过上面的代码非常方便地取得它在内存中的地址及所占用内存的长度。
短字符串和集合类型,也使用与简单类型一致的规则。
简单类型的变量在内存中具有特定的格式,比如实数、枚举类型。有关其具体的存储格式,可以查阅参考书目中的《DELPHI技术手册》以及IEEE标准文档。
2.3.2字符串
Delphi中的字符串格式多而且混乱。
“多”是因为Delphi一方面要继承自Pascal以来的语言习惯,另一方面又要与Windows制定的内部数据结构和外部编程接口相兼容。“混乱”源自Delphi总是试图让开发人员可以直接在各种字符串之间任意交换数据,而无须了解各种字符串的内部格式——因而,这种混乱的感觉为企图深入了解每一行Delphi语句的奥秘的程序员所深受,而对于只用它来完成一个应用的开发者来说,一切都是透明的。
按照官方的资料,字符串只有短字符串、长字符串和宽字符串三种。但下面将能与它们直接赋值的“Null结束字符串”和“字符数组”也一并讲述。
■短字符串
短字符串至少分配一个字节(即便是“空”串)。这个字节的地址亦即字符串在内存中占用的首地址,用于存放字符串长度,称为计数位。自其后,开始存放字符串中的各个字符。因此,短字符串可以存放0-255个字符。
短字符串可以有两种声明方式:
var varl:String[20]; var2:ShortString;
var1的声明限定字符串长度为0-20字节;var2的声明使用默认值,因而限定为0-255字节。
Delphi总是按最大上限为短字符串分配内存。这样,最少的情况下,var1将占用20+1字节,而var2将占用255+1字节——这1字节是为var1[0]和var2[0]的计数位保留的。
由于堆栈以4字节为单位进行分配,因此,var1在堆栈中将被分配24字节,而var2将被分配256字节。源于堆栈的这种分配,在应用程序内存区中,短字符串类型化常量采用与堆栈分配一致的长度分配。
短字符串格式是从Pascal继承而来的。在Pascal中一个字符串与字符数组是数据兼容的。
这表明可以直接在字符数组与字符串之间赋值。
■字符数组
可以用声明数组的规则声明字符数组:
var varl:array[0..20]of char;
在内存长度上,字符数组使用与短字符串一致的内存分配规则。因此,数组var1将占用24字节内存。
字符数组同时遵守数组在内存使用上的规则。
■Null 结尾字符串
PChar类型是典型的使用Null结尾字符串规则的数据类型。
此外,也可以将任意的内存块视作Null结尾字符串来定义和操作。例如用GetMem()获得的一块内存。——几乎所有的内存块都满足这样的规则。因此,Null结尾字符串是一个弱类型检测的定义。在WinAPI中有大量的地方使用了Null结尾字符串,所以,很多地方随便传个指针,也可能导致无法预测的结果。
很多时候,使用PChar来定义一个普通的指针,其目的并不是要将指针处理成字符串,而是为了地址运算的方便。因为PChar是编译器支持的数据类型,编译器在必要的情况下重定义Char类型,就可以同时支持纯 WideChar或AnsiChar核心的操作系统,例如纯Unicode的操作环境。这比定义成PByte类型要更安全。
■长字符串
Ansistringl缺省以String关键字定义的,或者直接以AnsiString关键字定义的字符串变量都是长字符串。长字符串兼有短字符串和Null结尾字符串的特征,同时能够以字符数组的方式进行操作。
长字符串变量总是占用4个字节,所以绝大多数时候,可以把长字符串当成指针来操作。——在Delphi内部更是这样。在TStrings类中,几乎所有的操作都是针对于这4个字节的。这使得TStrings拥有与TList相当的速度和性能。
长字符串的内存占用相对来说要复杂些:
空值的长字符串的内存占用为0字节
非空值的长字符串的内存占用为:串长+8字节+1字节
实际上Delphi使用一个空指针来表示空值的长字符串。所以空字符串在堆中没有内存占非。
空值的情况下,除了为字符串分配应有的内存空间之外,Delphi还在负偏移的位置占用了8个字节,分别保存了串长和串引用计数,其内存布局如图2.2所示。

下面的代码用于直接操作引用计数和串长:
function GetStringRef(Const Str:AnsiString) : Integer; begin if Str = '' then Result := -1 else Result := PInteger(Integer(Str)-8)^; end; function GetStringLen(Const Str:AnsiString) : Integer; begin if Str = '' then Result := 0 else Result := PInteger(Integer(Str)-4)^; end; procedure SetStringRef(Const Str:AnsiString; Ref:Integer); begin if Str <> '' then PInteger(Integer(Str)-8)^ := Ref; end; procedure SetStringLen(Const Str:AnsiString; Len:Integer); begin if Str <> '' then PInteger(Integer(Str)-4)^ := Len; end;
直接修改引用计数是不安全的,系统对字符串有效性的管理将会因此紊乱。而直接修改字符串的长度,可能比操作SetStringRef()更为危险。SetStringLen()会导致系统对字符串的内存管理紊乱,这:要有两方面:
- 结束符#0不会自动添加,结果串在作为“Nul1结尾字符串”处理时,不会有预想的改变。
- 变量占用内存并没有实际发生变化,访问增加长度后的字符串可能会导致内存存取错误。
因此,除非能确知这样做的后果,否则不要使用函数SetStringRef()和SetStringLen()。
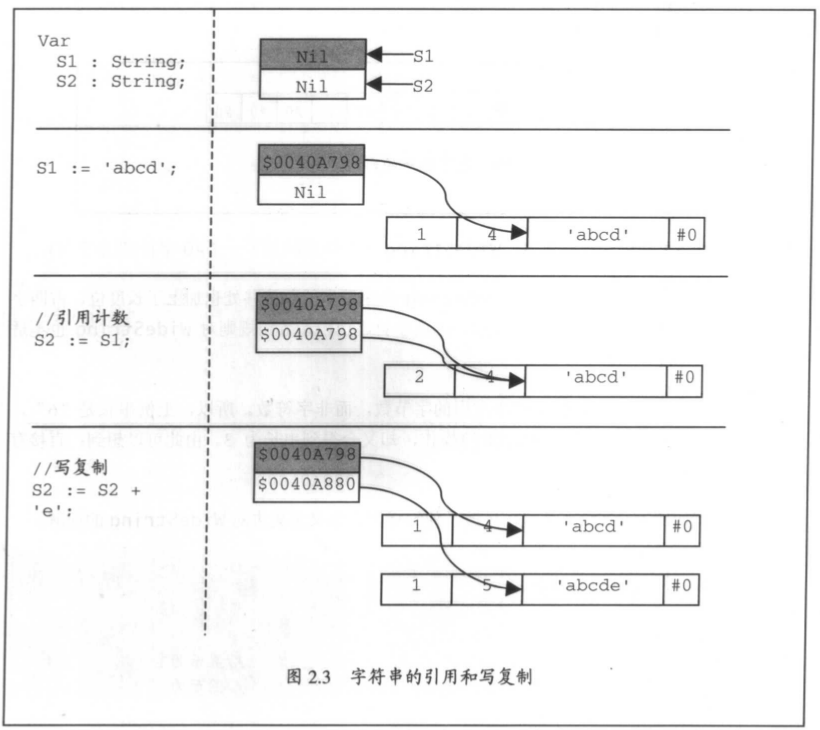
■字符串的引用计数与写复制
由于有引用计数的关系,所以,Delphi会管理两个相同的字符串,以及由赋值而得的字符串。这使得多个字符串的内存占用分析变得复杂起来(例如需要先比较两个字符串是否是同一地址的引用):
- 如果在编译期,能确知两个字符串相同,则编译器使两个字符串使用相同的内存占用。
- 赋值操作会使得两个字符串使用相同的内存占用。
- 修改字符串的操作,会导致“写复制(copy-on-write semantics)”,并且使相同内存用的两个字符串,开始使用不同的内存占用。
- 直接访问字符串中的元素(以s[i]的形式访问个字符),会导致整个字符串写复制。
图2.3展示了这种关系。
由于短字符串、Null结尾字符串和字符数组没有引用计数和与长字符串相同的专用计数位,所以,上面的关系在这些类型的字符串中并不完全存在。
■宽字符串
WideChar是一种16位Unicode,它占用两个字节内存。基于WideChar的宽字符串WideString)与AnsiString的内存结构不完全相同。但是,和大多数人预想的不同:
WideString 并非正好比AnsiString多i用一倍的内存空间。例如:
var str1:String='abc中文; str2:Widestring ='abc中文;
在这个例子中,Str1占3+4=7字节的空间,而Str2占用6+4=10字节:只有字符串“abc”占用的长度发生了变化。
Delphi6的《语言手册》中关于宽字符串的一段描述是有错误的,手册中指出“s[i]代表S中的第i个字节(而不一定是第i个字符)”。实际却正好相反,在宽字符串中,s[i]代表第i个字符,却不一定是第i个字节。
Delphi中使用基于AnsiChar的数组来操作WideString是危险的。这种情况下应该使用基于WideChar的数组。为了使与标准Pascal相同语义的代码在Delphi中完全正常地被编译,Delphi将s[i]解释成一个字符,而无论它是AnsiChar,还是WideChar—Char与Byte的对应关系被打破之后,很多麻烦都出来了,相信深入过中文操作系统的人都清楚这一点。
在内存结构上,WideString呈现出奇特的一面,举例来说:
Var str:Widestring='abc';
该定义在内存中的结构如图2.4所示。
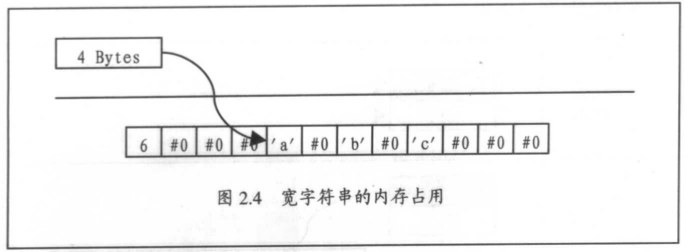
为了和Null结尾字符串兼容,WideString也在结尾添加了一个#0字符(两个字节)。为了和AnsiString兼容,WideString在字符串的负偏移处也加上了长度位,占四字节。但是,WideString 没有引用计数,因而字符串引用计数的规则对wideString也不适用。
在长度位上,保存的值是字符串占用的字节数,而非字符数。所以,上例串长是“6”,而不是“3”。但是,如果用Length()操作,却又会得到串长为3。由此可以想到:直接存取长度位是不安全的。
下面的代码用Pointer类型作过渡,使编译器在语义上失去对WideString的理解。
Var Str:WideString='abe'; //... Writeln(Str); Writeln(Length(Str)); //显示为3 writeln(Length(string(Pointer(Str))))i //显示为6
■字符串混用的代价:计数位与结束字符的维护,以及内存复制
字符串的相关类型很多,其中比较常见的是PChar。它的定义其实是这样的:
Type PChar = ^Char;
然而作为内部数据类型,Delphi对PChar的处理是很多的,其中主要包括的是在各种字符串之间的数据类型转换上。几乎每个与其他类型的字符串相关的PChar的操作中都涉及到长度计数和引用计数问题。而且为了与操作系统所理解的PChar规则一致,Delphi还要为它的PChar维护一个结束字符Null。
除了Null,PChar没有其他额外的域,这使得将一个长字符串转换成PChar是不需要任何额外代码支出的。但在开发者的具体代码中,系统内部的引用计数和写复制机制会使得整个关系变得让人捉摸不定。如果开发者需要了解每一行代码的细节,就应该回到前面的章节仔细阅读,并使用GetStringRef()和GetDataAddr()两个函数来跟踪具体的代码。
然而,在短字符串与PChar之间转换绝非易事。因为短字符串没有结束字符Null,所以不能直接在它与PChar之间转换,而必须先将ShortString转换到AnsiString。而这将导致一个复制操作。下面的代码说明了这一点:
var s1 : ShortString = 'abcd'; s2 : String = '12341'; p : pChar; //... writeln(GetStringRef(s2)); writeln(GetDataAddr(s2)); writeln('---'); //赋值操作将不会导致引用计数的增加,p指向地址与S2的内存占用地址一致,表明没有 //复制操作发生 p := pchar(s2); writeln(GetStringRef(s2)); writeln(GetDataAddr(P)); writeln('---'); //通过string()转换将导致写复制操作发生:S[1]的地址与p指向地址并不相同 //p := pChar(s1)<--这样的语句是不会被编译通过的 p := pChar(String(s1)); writeln(GetAddr(sl[1])); writeln(GetDataAddr(P));
更多的麻烦表现在WideString与AnsiString的转换上。这主要涉及到字符串长的重新修正与内存重新分配。由于没有引用计数,所以无论是否有类型转换操作,WideString的赋值总是将导致新的内存占用。只不过WideString之间的赋值不会导致字符串长的重新修正,而将WideString类型的变量赋给AnsiString类型的变量时,必须重新计算字符串长。
因此,使用WideString的系统的效率会低于AnsiString。这一切都源自于没有引用计数机制。同时,混合使用AnsiString与wideString的系统的效率将会更差——因为系统必须为重新计算字符串长而付出额外的代价。
内存复制的情况表现在:
- AnsiString与ShortString之间赋值和强制类型转换。
- rWideString与任何类型的字符串赋值和强制类型转换。
- 将字符串指针赋给字符串。
以下操作不会导致内存复制:
- 将字符串赋给指针(包括无类型指针和各种字符串指针)。
- 对上面操作的目标指针的任意操作,不会导致源字符串的内存复制或引用计数变化。
■由引用计数导致的问题
由于编译器通常只能理解直接赋值和类型转换中的字符串引用,并据此来修正引用计数。所以在直接内存操作的情况下,常常会使长字符串的引用计数失去维护。
一个极其典型的例子源自于对记录Move()操作,如下:
type TRec=Record Index: Integer; str: String; end; var R1,R2: TRec; //... R1. Index:=1; R1. Str:=' Test'; Writeln(' Ref for Rl. Str:', GetstringRef(R1. Str)); //R2:=R1; move(R1,R2, SizeOf(R2)); Writeln('Ref for R1. Str:', GetStringRef(R1. Str)); Writeln(' Addr : ', GetDataAddr(R1. Str), ' = ', GetDataAddr(R1. Str)); R2. Str := 'Now, Error!';
根据Delphi的语法,调用move()的这一行代码意味着两个数据结构(记录)完全被复制。
但这并不等于“R2.Str:=R1.Str”这样的操作同时发生,因此,R1.Str的引用计数并没有发生变化,而R2.Str却成了一个有效的字符串。
接下来的一行代码:
R2. Str := 'Now, Error!';
用于“破坏”引用计数。由于R2.Str是Delphi认可的有效字符串,所以在执行这行代码的同时,引用计数将减1,从而变成0。按照字符串的处理规则,引用计数为0的字符串将被释放内存(清除)。这时,R1.Str指向了一个不能被访问的内存块。
图2.5进一步地描述这种现象。
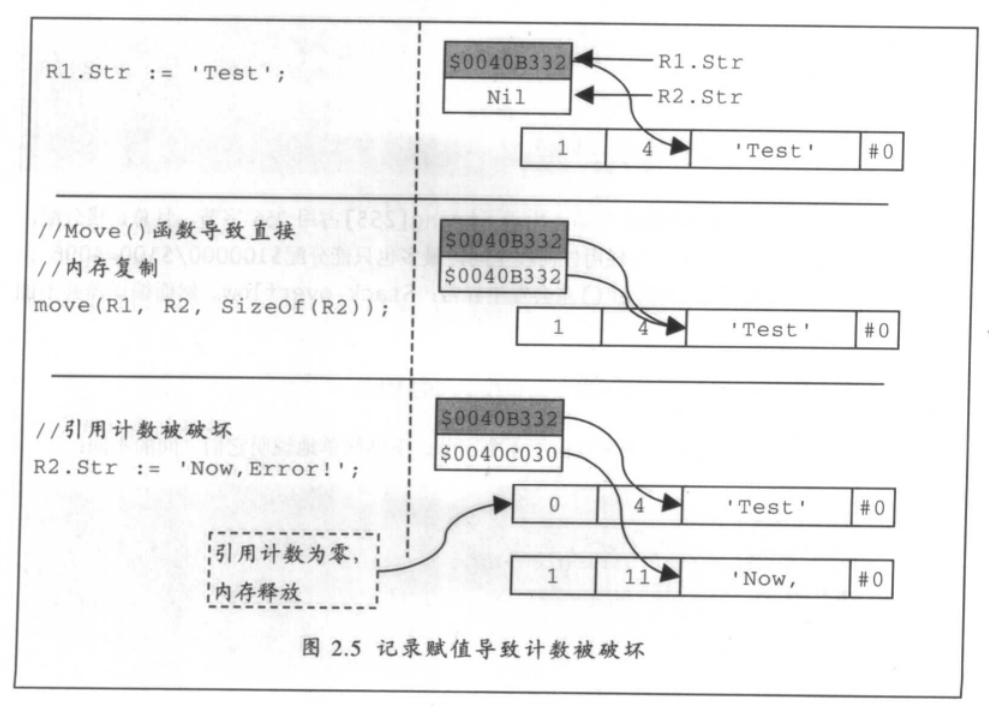
替代move()的安全方法是直接使用记录赋值“R2:=R1;”。在编译期,Delphi将会为记录赋值操作加入修正引用计数的代码。
2.3.3构道类型
■集合类型
集合类型与简单类型一样,没有动态分配的内存。集合的每个元素占一个位,因为Delphi最大支持256个元素的集合,所以使用1~32字节来存放各个位数据。
集合类型的局部变量总在栈上分配。
■数组类型
不论数组元素是什么类型,静态数组的局部变量总会在栈上分配。如果堆栈大小不够,将会导致异常。Delphi在编译期不会计算栈的耗用。下例暗藏着一个危险的BUG:
procedure StackOver; var s:array [0..4100] of String[255]; begin end;
Delphi默认栈最大为$100000字节,由于String[255]占用256字节,且总是栈分配,则可以计算得知,即使应用程序不耗用任何栈空间,最多也只能分配$100000/$100=4096元素。因此,上例中调用StackOver()总会发生异常:Stack overflow。然而编译器并不能检测到这个错误。
可以使用SMaxStackSize编译指令调整栈空间的大小。
与静态数组不同,动态数组变量只占用4个字节。下例简单地说明它们之间的不同:
procedure ArrayTest; var S : array[0..1000] of String[255]; S1:array of String[255]; begin SetLength(S1, 1001); Writeln(Sizeof(S)); //输出:256256 Writeln(SizeOf(S1));//输出:4 end;
动态数组在堆中动态分配内存,并且采用与长字符串完全一致的内存结构:在负偏移处保存着8字节的引用计数和长度计数。SetLength()隐含地调用了ReallocMem()。
■记录类型
缺省情况下,记录会以对齐方式存储。在编译期,Delphi用一套复杂的方法来计算对齐格式记录的内存占用情况。Packed关键字和{$A1ign}编译指令会对Delphi的这种行为造成影响。
记录总是直接分配内存。因此,与静态数组一样,在例程中定义过大的记录类型的局部变量时,也可能导致栈溢出一—如果需要定义复杂到$100000(或更多)字节的记录的话。变体记录(有可变部分的记录类型)使用能够容纳可变部分最大长度的空间来存储。Delphi约定变体部分必须出现在记录定义的最末部分,这使得在计算和分配空间时,可以通过直接在记录后面附加空间的方式来实现。如果要在记录的中间部分声明变体,则须单独声明一个变体记录类型,例如:
TIIDUnion=record case Integer of 0 : (Characteristics:DWORD); 1 : (OriginalFirstThunk:DWORD); end;
TImageImportDecriptor = record Union : TIIDUnion; TimeDateStamp : DWORD; ForwarderChain : DWORD; Name : DWORD; FirstThunk : DWORD; end;
变体记录使得编译器可以将一个内存空间解释为多种类型,这意味着它可以用于隐含地实现数据类型转换。
■文件类型
文件类型是基于压缩(Packed)的记录类型来实现的。类型文件和无类型文件都采用同一记录类型,在$(RTL)ISystem.pas中,可以查阅到它的定义:TFileRec。文本文件采用专用的记录类型,在$(RTL)NSystem.pas中定义为TTextRec。
文件类型的内存分配规则可以参见记录类型。
文件类型的详细实现和内部例程在第5章的“32位的DOS:控制台应用程序”中讲述。
2.3.4指针类型
指针总是占用4字节的内存。任何时候都可以将指针作为整型使用,并用整型运算做地址运算。有类型指针可以使用内部例程Inc()和Dec()进行地址运算。
2.3.5过程类型
过程变量只占用4字节的内存,它实际上是以指针形式存在的。过程变量只存储例程代码地址的入口地址,真实的例程代码只存在于应用程序的代码段中。尽管如此,Delphi采用一种与指针不同的语义来理解过程——因此,不能在指针与过程变量之间做强制转换。下例说明过程是采用指针的形式存储的:
{$APPTYPE CONSOLE} uses SysUtils; procedure TestProc; type TRec = packed record Int : Integer; Proc : Procedure; end; var Rec : TRec; PInt : PInteger; begin Rec.Int := $1234FFFE; Rec.Proc := TestProc; PInt := @Rec; Writeln('Rec.Int : ', IntToHex(PInt^, 8)); //不能直接做强制转换,下一行代码出错 //PInt := PInteger(Rec.Proc); Inc(PInt); Writeln('Rec.Proc : ', IntToHex(PInt^, 8)); end; begin TestProc; readln; end.
应用程序代码段既不是栈访问,也不是堆访问。所以,过程类型较其他变量类型更为特殊,通常情况下,没有办法分配过程类型变量的“动态内存”。
应用程序的代码通常是在编译期由编译程序生成的,并且在程序文件内部组织完成。这样一旦编译过程结束,例程代码也就确定了。在应用程序调入时,系统会将包含这些例程代码的文件映像部分定义为代码段,代码段是只读的。
因此,在代码中,可以简单地将过程赋给一个过程变量,但如果要真的将过程变量作为指针用来修改目标内存的数据,就会出错。修改上例中的代码来示范这种现象:
procedure TestFixPro; type TRec = packed record proc : procedure; end; var Rec : TRec; PInt : PInteger; PPtr : PPointer; begin Rec.proc := TestFixPro; PPtr := @Rec; PInt := PPtr^; //直接修改代码段导致出错 try PInt^ := 1; except on e:Exception do Writeln(e.message); end; end;















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









