







一、前言
分类是一种重要的数据挖掘算法。分类的目的是构造一个分类函数或分类模型(即分类器),通过分类器将数据对象映射到某一个给定的类别中。分类算法有很多,不同分类算法又用很多不同的变种。不同的分类算法有不同的特定,在不同的数据集上表现的效果也不同,如何评价一个分类算法的好坏,分类器的主要评价指标有准确率(Precision)、召回率(Recall)、Fb-score、ROC、AOC等。
二、评价指标
1、几个常用的术语
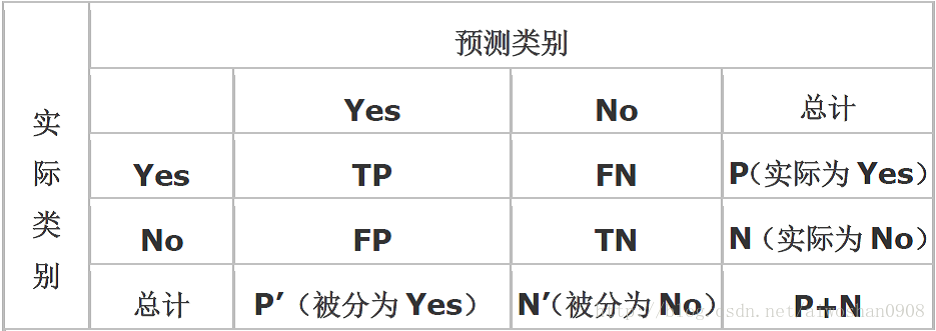
现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
1)True positives(TP):被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP):被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
2、评价指标
1)正确率(accuracy)
accuracy=(TP+TN)/(P+N),是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2)错误率(error rate)
error rate=(FP+FN)/(P+N) =1 - accuracy,与正确率相反,描述被分类器错分的比例 ;
3)灵敏度(sensitive)=真正类率(truepositive rate,TPR)
sensitive = TP/P,衡量了分类器对正例的识别能力;
负正类率(false positive rate, FPR):FPR=FP/(FP+TN),是分类器错认为正类的负实例占所有负实例的 比例
4)特效度(specificity)=真负类率(True Negative Rate,TNR)
specificity =TN/N=1-FPR,衡量了分类器对负例的识别能力;
5)精度(precision)=准确率
精度是精确性的度量,precision=TP/(TP+FP)
注:分类正确率(Accuracy),不管是哪个类别,只要预测正确,其数量都放在分子上,而分母是全部数据数量,这说明正确率是对全部数据的判断。而准确率Precision在分类中对应的是某个类别,分子是预测该类别正确的数量,分母是预测为该类别的全部数据的数量。或者说,Accuracy是对分类器整体上的正确率的评价,而Precision是分类器预测为某一个类别的正确率的评价。
6)召回率(recall)
是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive
Fb-score是准确率和召回率的调和平均:Fb=[(1+b2)*P*R]/(b2*P+R),比较常用的是F1。
7)其他评价指标
· 计算速度:分类器训练和预测需要的时间;
· 鲁棒性:处理缺失值和异常值的能力;
· 可扩展性:处理大数据集的能力;
· 可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
检测率DR detectingrate:DR=TP/(TP+FN)
虚警率FAR false alarm rate:FAR=FP/(FP+TP)
漏警概率MA(Missing Alarm):MA = FN/(TP+FN)
混淆矩阵中常用评价指标
参考网址:http://blog.sina.com.cn/s/blog_764b1e9d0100rlnh.html
漏分误差omission errors (OE)=FN/(TP+FN)
错分误差commission errors (CE)= FP/(TP+FP)
整体分类精度overall accuracy (OA)= accuracy =(TP+TN)/(P+N)
制图精度Prod.Acc=TP/(TP+FN)= sensitive
用户精度User.Acc=TP/(TP+FP)= precision
Kappa系数http://blog.sina.com.cn/s/blog_548d137e01012py1.html
它是通过把所有真实参考的像元总数(N)乘以混淆矩阵对角线(XKK)的和,再减去某一类中真实参考像元数与该类中被分类像元总数之积之后,再除以像元总数的平方减去某一类中真实参考像元总数与该类中被分类像元总数之积对所有类别求和的结果。
Kappa值的范围值应在-1~1之间。Kappa≥075两者一致性较好;0.75Kappa≥0.4两者一致性一般;Kapp.4两者一致性较差。
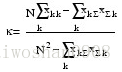
三、总结
【评价指标】
正确率(overallaccuracy,OA) OA=(TP+TN)/(P+N)
精度(precision) Precision=TP/(TP+FP)=1-FAR
检测率 (detecting rate,DR) DR=TP/(TP+FN)=1-MAR
虚警率 (false alarm rate,FAR) FAR=FP/(FP+TP)
漏警概率(MissingAlarm,MAR) MAR = FN/(TP + FN)
【参考依据】
维基百科 https://en.wikipedia.org/wiki/Precision_and_recall
所以,上述五个指标,实际上为三个指标,分别为OA、Precision和DR,另外两个指标可以由这三个推导出来。
FAR和MAR两个概率都是越小越好,但是一般来说他们两者无法同时达到任意小,基本上,在其他条件一定时虚警概率越小漏警概率就会越大;漏警概率越小虚警概率就会越大.转化为统计的语言就是一个假设检验犯第一类错误和第二类错误的概率,无法同时变小.现在一般的的做法是给定其中一个错误的概率不超过某个值(比如不超过1%)时,让另一个错误的概率尽量小。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









