






FGC----jmap -histo:live导致
线上某服务的老年代配置了CMS,但却在gc.log发现连续Full GC的问题。JVM参数配置如下:
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=68参数的意义是:在老年代到68%的时候,会触发一次CMS GC,应该是出现类似如下的日志:
T20:10:37.803+0800: 3246087.559: [CMS-concurrent-mark-start] T20:10:38.463+0800: 3246088.220: [CMS-concurrent-mark: 0.661/0.661 secs] [Times: user=3.17 sys=0.56, real=0.66 secs] T20:10:38.463+0800: 3246088.220: [CMS-concurrent-preclean-start] T20:10:38.552+0800: 3246088.309: [CMS-concurrent-preclean: 0.069/0.089 secs] [Times: user=0.14 sys=0.04, real=0.09 secs]_ T20:10:38.552+0800: 3246088.309: [CMS-concurrent-abortable-preclean-start]
但线上环境的日志却出现如下的情况:
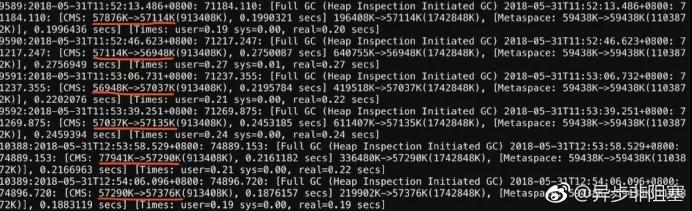
老年代配置了900M,但却在只使用了50+M的时候触发了Full GC,而且是在短暂的时间内连续触发。
配置了CMS却触发Full GC,有以下几种可能:
-
大对象分配时,年轻代不够,直接晋升到老年代,老年代空间也不够,触发 Full GC(老年代还剩800+M,显然不可能)
-
内存碎片导致(由于CMS是基于标记清除算法的,所有会导致内存碎片,但通过grep -i "cms" gc.log,JVM尚未触发过CMS回收,所以也不存在内存碎片的说法)
-
CMS GC失败导致(从gc.log并未找到concurrent mode failure的记录,排除)(promotion failed也会导致)
- 老年代、永久带空间不足
- System.gc()
-
jmap -histo(人为执行该命令)
经笔者回忆,在中午快12点的时候确实登录过线上机,执行过jmap -histo:live命令,经验证,手动执行jmap -histo:live,也确实会在gc.log出现触发 Full GC的现象,问题得到验证。














 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









