









分布式环境中大多数服务是允许部分失败,也允许数据不一致,但有些最基础的服务是需要高可靠性,高一致性的,这些服务是其他分布式服务运转的基础,比如naming service、分布式lock等,这些分布式的基础服务有以下要求:
- 高可用性
- 高一致性
- 高性能
对于这种有些挑战CAP原则的服务该如何设计,是一个挑战,也是一个不错的研究课题,Apache的ZooKeeper也许给了我们一个不错的答案。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它暴露了一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。关于ZooKeeper更多信息可以参见官方文档
ZooKeeper的基本使用
搭一个分布式的ZooKeeper环境比较简单,基本步骤如下:
1)在各服务器安装ZooKeeper
下载ZooKeeper后在各服务器上进行解压即可
tar -xzf zookeeper-3.2.2.tar.gz
2)配置集群环境
分别各服务器的zookeeper安装目录下创建名为zoo.cfg的配置文件,内容填写如下:
- # The number of milliseconds of each tick
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- initLimit=10
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- syncLimit=5
- # the directory where the snapshot is stored.
- dataDir=/home/admin/zookeeper-3.2.2/data
- # the port at which the clients will connect
- clientPort=2181
- server.1=zoo1:2888:3888
- server.2=zoo2:2888:3888
其中zoo1和zoo2分别对应集群中各服务器的机器名或ip,server.1和server.2中1和2分别对应各服务器的zookeeper id,id的设置方法为在dataDir配置的目录下创建名为myid的文件,并把id作为其文件内容即可,在本例中就分为设置为1和2。其他配置具体含义可见官方文档。
3)启动集群环境
分别在各服务器下运行zookeeper启动脚本
/home/admin/zookeeper-3.2.2/bin/zkServer.sh start
4)应用zookeeper
应用zookeeper可以在是shell中执行命令,也可以在java或c中调用程序接口。
在shell中执行命令,可运行以下命令:
bin/zkCli.sh -server 10.20.147.35:2181
其中10.20.147.35为集群中任一台机器的ip或机器名。执行后可进入zookeeper的操作面板,具体如何操作可见官方文档
在java中通过调用程序接口来应用zookeeper较为复杂一点,需要了解watch和callback等概念,不过试验最简单的CURD倒不需要这些,只需要使用ZooKeeper这个类即可,具体测试代码如下:
- public static void main(String[] args) {
- try {
- ZooKeeper zk = new ZooKeeper("10.20.147.35:2181", 30000, null);
- String name = zk.create("/company", "alibaba".getBytes(),
- Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
- Stat stat = new Stat();
- System.out.println(new String(zk.getData(name, null, stat)));
- zk.setData(name, "taobao".getBytes(), stat.getVersion(), null, null);
- System.out.println(new String(zk.getData(name, null, stat)));
- stat = zk.exists(name, null);
- zk.delete(name, stat.getVersion(), null, null);
- System.out.println(new String(zk.getData(name, null, stat)));
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
以上代码比较简单,查看一下zooKeeper的api doc就知道如何使用了
ZooKeeper的实现机理
ZooKeeper的实现机理是我看过的开源框架中最复杂的,它的解决是分布式环境中的一致性问题,这个场景也决定了其实现的复杂性。看了两三天的源码还是有些摸不着头脑,有些超出了我的能力,不过通过看文档和其他高人写的文章大致清楚它的原理和基本结构。
1)ZooKeeper的基本原理
ZooKeeper是以Fast Paxos算法为基础的,在前一篇blog中大致介绍了一下paxos,而没有提到的是paxos存在活锁的问题,也就是当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader,只有leader才能提交propose,具体算法可见Fast Paxos。因此,要想弄得ZooKeeper首先得对Fast Paxos有所了解。
2)ZooKeeper的基本运转流程
ZooKeeper主要存在以下两个流程:
- 选举Leader
- 同步数据
选举Leader过程中算法有很多,但要达到的选举标准是一致的:
- Leader要具有最高的zxid
- 集群中大多数的机器得到响应并follow选出的Leader
同步数据这个流程是ZooKeeper的精髓所在,并且就是Fast Paxos算法的具体实现。一个牛人画了一个ZooKeeper数据流动图,比较直观地描述了ZooKeeper是如何同步数据的。
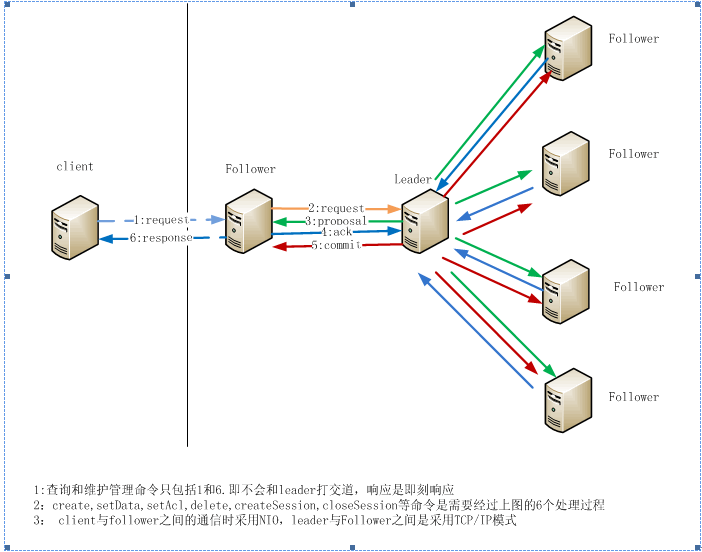
以上两个核心流程我暂时还不能悟透其中的精髓,这也和我还没有完全理解Fast Paxos算法有关,有待后续深入学习
ZooKeeper的应用领域
Tim在blog中提到了Paxos所能应用的几个主要场景,包括database replication、naming service、config配置管理、access control list等等,这也是ZooKeeper可以应用的几个主要场景。此外,ZooKeeper官方文档中提到了几个更为基础的分布式应用,这也算是ZooKeeper的妙用吧
1)分布式Barrier
Barrier是一种控制和协调多个任务触发次序的机制,简单说来就是搞个闸门把欲执行的任务给拦住,等所有任务都处于可以执行的状态时,才放开闸门。它的机理可以见下图所示:
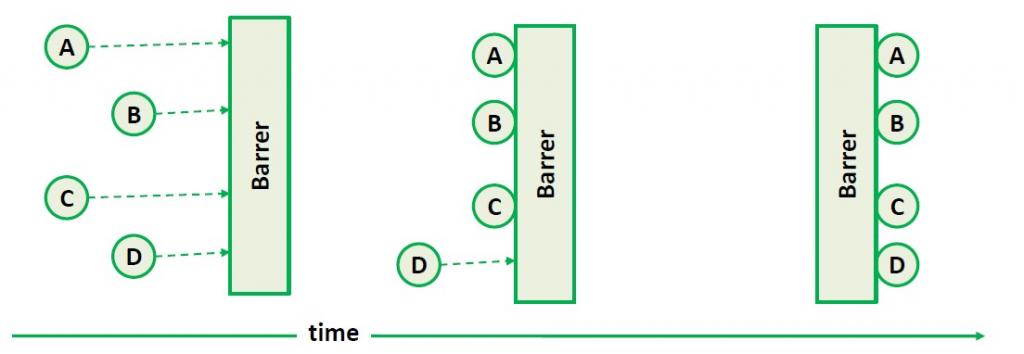
在单机上JDK提供了CyclicBarrier这个类来实现这个机制,但在分布式环境中JDK就无能为力了。在分布式里实现Barrer需要高一致性做保障,因此ZooKeeper可以派上用场,所采取的方案就是用一个Node作为Barrer的实体,需要被Barrer的任务通过调用exists()检测这个Node的存在,当需要打开Barrier的时候,删掉这个Node,ZooKeeper的watch机制会通知到各个任务可以开始执行。
2)分布式Queue
与Barrier类似分布式环境中实现Queue也需要高一致性做保障,ZooKeeper提供了一个种简单的方式,ZooKeeper通过一个Node来维护Queue的实体,用其children来存储Queue的内容,并且ZooKeeper的create方法中提供了顺序递增的模式,会自动地在name后面加上一个递增的数字来插入新元素。可以用其children来构建一个queue的数据结构,offer的时候使用create,take的时候按照children的顺序删除第一个即可。ZooKeeper保障了各个server上数据是一致的,因此也就实现了一个分布式Queue。take和offer的实例代码如下所示:
- /**
- * Removes the head of the queue and returns it, blocks until it succeeds.
- * @return The former head of the queue
- * @throws NoSuchElementException
- * @throws KeeperException
- * @throws InterruptedException
- */
- public byte[] take() throws KeeperException, InterruptedException {
- TreeMap<Long,String> orderedChildren;
- // Same as for element. Should refactor this.
- while(true){
- LatchChildWatcher childWatcher = new LatchChildWatcher();
- try{
- orderedChildren = orderedChildren(childWatcher);
- }catch(KeeperException.NoNodeException e){
- zookeeper.create(dir, new byte[0], acl, CreateMode.PERSISTENT);
- continue;
- }
- if(orderedChildren.size() == 0){
- childWatcher.await();
- continue;
- }
- for(String headNode : orderedChildren.values()){
- String path = dir +"/"+headNode;
- try{
- byte[] data = zookeeper.getData(path, false, null);
- zookeeper.delete(path, -1);
- return data;
- }catch(KeeperException.NoNodeException e){
- // Another client deleted the node first.
- }
- }
- }
- }
- /**
- * Inserts data into queue.
- * @param data
- * @return true if data was successfully added
- */
- public boolean offer(byte[] data) throws KeeperException, InterruptedException{
- for(;;){
- try{
- zookeeper.create(dir+"/"+prefix, data, acl, CreateMode.PERSISTENT_SEQUENTIAL);
- return true;
- }catch(KeeperException.NoNodeException e){
- zookeeper.create(dir, new byte[0], acl, CreateMode.PERSISTENT);
- }
- }
- }
3)分布式lock
利用ZooKeeper实现分布式lock,主要是通过一个Node来代表一个Lock,当一个client去拿锁的时候,会在这个Node下创建一个自增序列的child,然后通过getChildren()方式来check创建的child是不是最靠前的,如果是则拿到锁,否则就调用exist()来check第二靠前的child,并加上watch来监视。当拿到锁的child执行完后归还锁,归还锁仅仅需要删除自己创建的child,这时watch机制会通知到所有没有拿到锁的client,这些child就会根据前面所讲的拿锁规则来竞争锁。















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









