







CNN
RNN
递归神经网络(RNN)是一类包含内部状态的神经网络。 RNN能够编码动态时间行为,因为其在单元之间的连接形成有向循环。 RNN的内部状态可以被视为存储器状态,其包含当前输入和先前存储器的信息。 因此,RNN具有“记住”先前输入和输出的历史的能力。 RNN广泛应用于依赖于上下文的预测框架,例如机器翻译.
LSTM
LSTM算法全称为Long short-term memory,最早由 Sepp Hochreiter和Jürgen Schmidhuber于1997年提出[6],是一种特定形式的RNN(Recurrent neural network,循环神经网络),而RNN是一系列能够处理序列数据的神经网络的总称。这里要注意循环神经网络和递归神经网络(Recursive neural network)的区别。
一般地,RNN包含如下三个特性:
-
循环神经网络能够在每个时间节点产生一个输出,且隐单元间的连接是循环的;
-
循环神经网络能够在每个时间节点产生一个输出,且该时间节点上的输出仅与下一时间节点的隐单元有循环连接;
-
循环神经网络包含带有循环连接的隐单元,且能够处理序列数据并输出单一的预测。
RNN还有许多变形,例如双向RNN(Bidirectional RNN)等。然而,RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间的联系时会涉及雅可比矩阵的多次相乘,这会带来梯度消失(i.e. gradient vanishing .经常发生)或者梯度膨胀(较少发生)的问题,这样的现象被许多学者观察到并独立研究。为了解决该问题,研究人员提出了许多解决办法,例如ESN(Echo State Network),增加有漏单元(Leaky Units)等等。其中最成功应用最广泛的就是门限RNN(Gated RNN),而LSTM就是门限RNN中最著名的一种。有漏单元通过设计连接间的权重系数,从而允许RNN累积距离较远节点间的长期联系;而门限RNN则泛化了这样的思想,允许在不同时刻改变该系数,且允许网络忘记当前已经累积的信息。
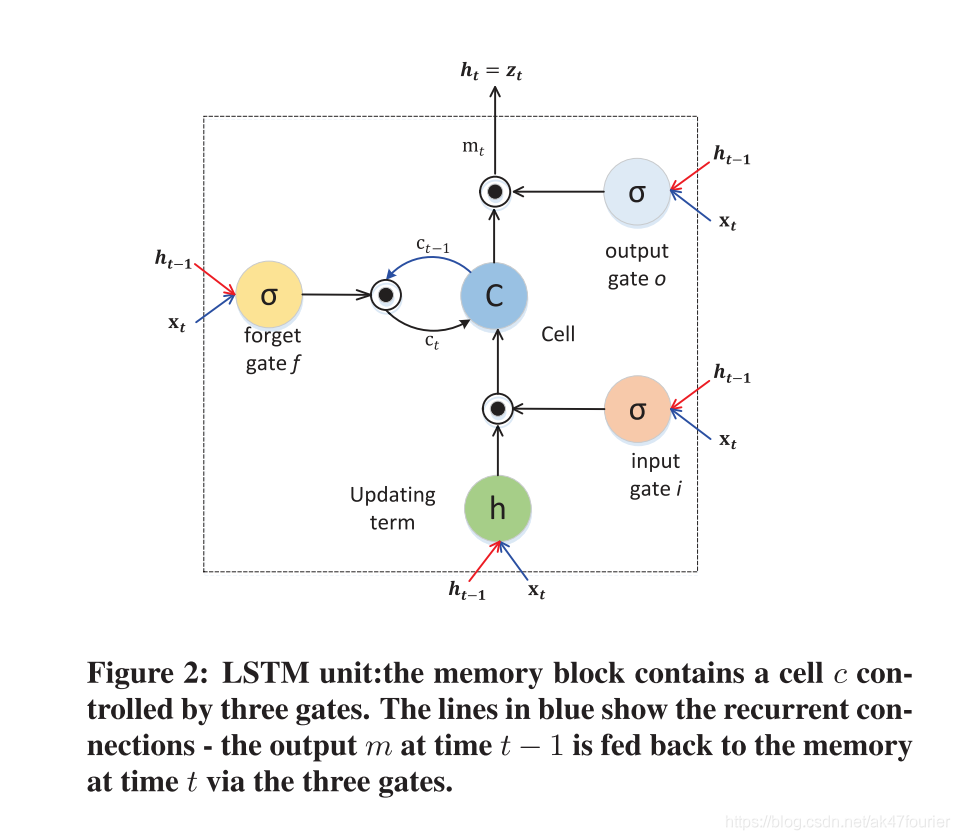
LSTM就是这样的门限RNN,其单一节点的结构如下图所示。LSTM的巧妙之处在于通过增加输入门限,遗忘门限和输出门限,使得自循环的权重是变化的,这样一来在模型参数固定的情况下,不同时刻的积分尺度可以动态改变,从而避免了梯度消失或者梯度膨胀的问题。
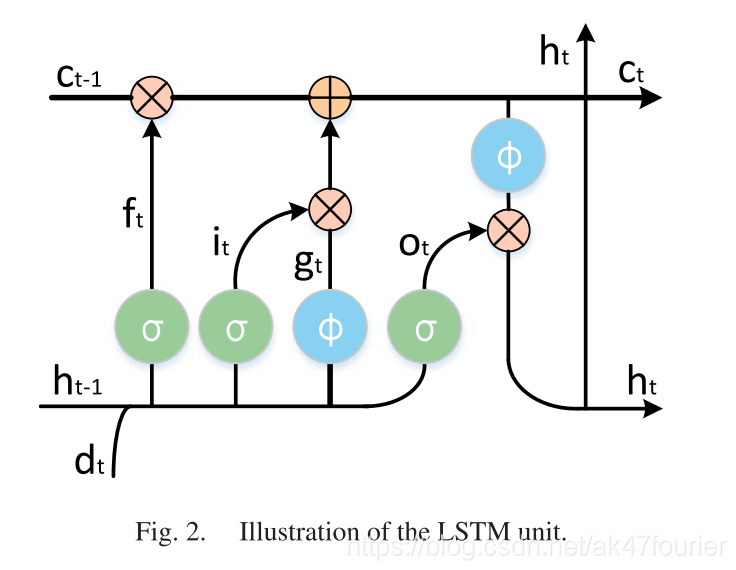
一个基本的LSTM 单元包括: -
a single memory cell
-
an input activation function
-
three gates(input gate it、forget gate ft、output gate ot)
其中:
it决定是否考虑当前输入xt对存储器状态施加影响
(“it allows incoming signals to alter the state of the memory cell or block it.”)
ft允许cell忘记以前的记忆ct-1
(ft controls what to be remembered or be forgotten by the cell, and somehow can avoid the gradient from vanishing or exploding when back propagating through time. )
ot决定多少记忆被转移到下一个隐藏状态ht
(it allows the state of the memory cell to have an effect on other neurons or prevent it.)
这样的乘法门使得可以稳健地训练LSTM,因为这些门很好地处理爆炸和消失的梯度(exploding and vanishing gradients)
LSTM块中的memory cell和gates定义如下:
(1)第一种写法:
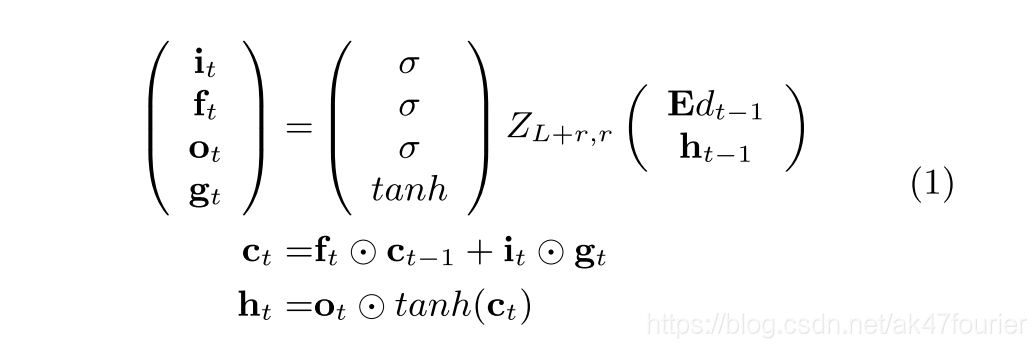 其中tanh是双曲正切函数
其中tanh是双曲正切函数
E表示嵌入矩阵,
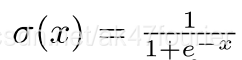
表示logistic sigmoid 非线性激活函数,把所有的实数map到(0,1)上。

表示和gate 值的与操作
ZL+r,r表示LSTM的参数。让L和r分别表示嵌入和LSTM维度。
(2)第二种写法:
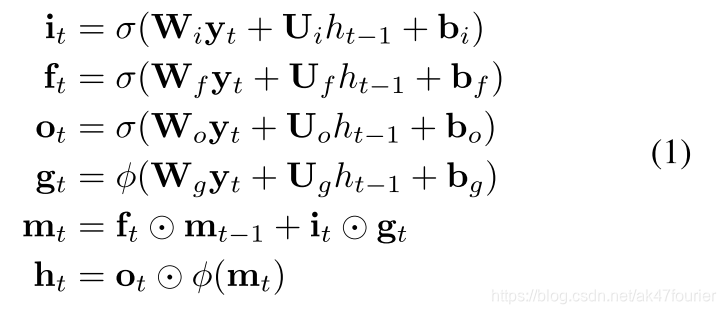
其中权重矩阵W,U和b是要学习的参数,yt表示在每个时间t,LSTM单元的输入向量。
接下来的内容来自论文:
同上,它被认为是LSTM学会有选择地忘记其记忆或者接受当前输入的旋钮。
与图像相比,视频包含更多复杂的时间注意力信息,需要和语言数据对齐。所以,我们把注意力机制扩展进LSTM中。LSTM就变成:
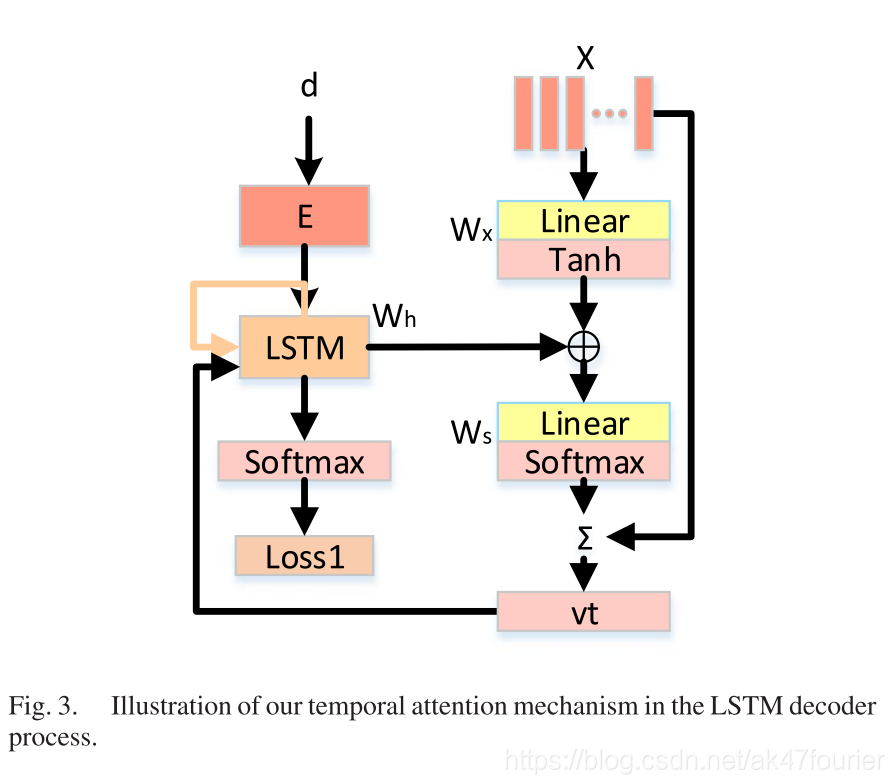
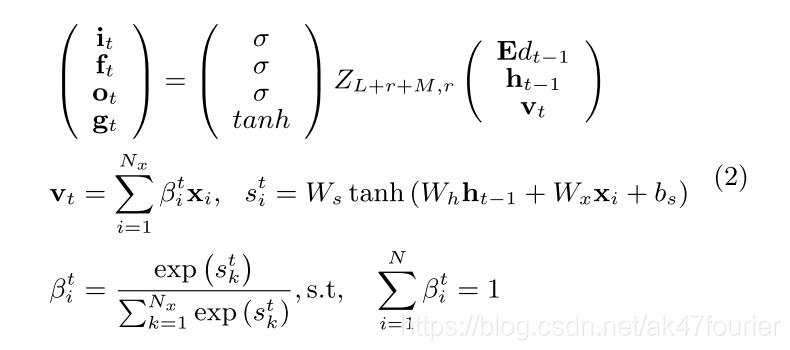
其中vt表示文本向量。M是它的维度。
Bit表示一个注意力权重(在时间t时,描述输入视频第i帧的相关性)
给出了LSTM的隐藏状态ht-1和第i个视频特征,就能返回未归一化的相关得分sit.一旦所有帧的相关得分计算完以后,LSTM就可以获得t时刻的Bit,Ws,Wh,Wx,bs是等待估计的参数。
此外,为了获取丰富的时间信息,还介绍了一个一层的LSTM视觉编码器。在本文中,集成了升级的GoogleNet和一层的LSTM视觉编码器来对视频的时间信息进行编码。具体来说,就是LSTM视觉编码器的最后输出被用来初始化我们基于注意力的LSTM网络的第一个LSTM单元。
(3)第三种写法:
来自论文:
Summarization-based Video Caption via Deep Neural Networks
公式如下:















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









