







转载:http://blog.csdn.net/vellin/article/details/53897827#comments
NoSQL的产生就是为了解决大数据量、高扩展性、高性能、灵活数据模型、高可用性。但是光通过主从模式的架构远远达不到上面几点,由此MongoDB设计了副本集和分片的功能。
mongoDB官方已经不建议使用主从模式了,替代方案是采用副本集的模式:

那什么是副本集呢?
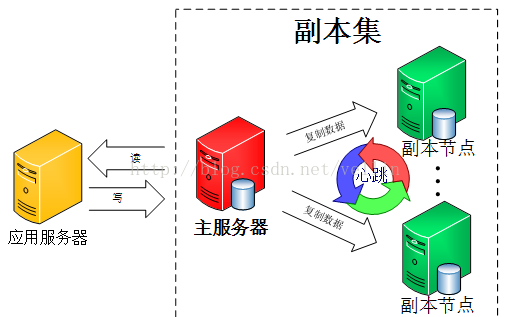
由图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一但主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。我们看一下主服务器挂掉后的架构:
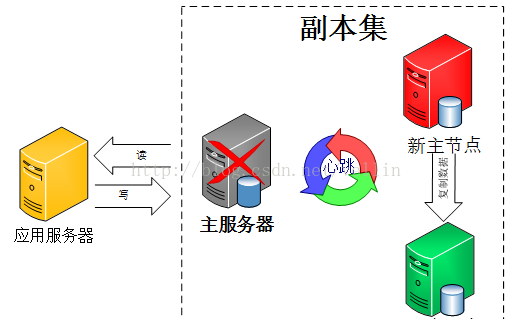
官方推荐的副本集机器数量为至少3个,如果已经有挂掉一个节点,再挂掉一个,剩下的最后一个不会自动成为新的主节点。
1、准备3个虚拟机:192.168.4.198,192.168.4.199,192.168.4.200,都下载并解压好Mongo包。并分别在三个虚拟机上创建数据库存放文件夹。 /home/weixla/dada/db
2、分别以副本集模式启动三个虚拟器的MongoDB服务,
/home/weixla/mongodb-3.4.0/bin/mongod -dbpath /home/weixla/data/ --replSet TestReplicaSet

可以看到控制台上显示副本集还没有配置初始化信息。
3、初始化副本集
登录任意一台客户端(这里登录198那台的客户端),切换到admin数据库
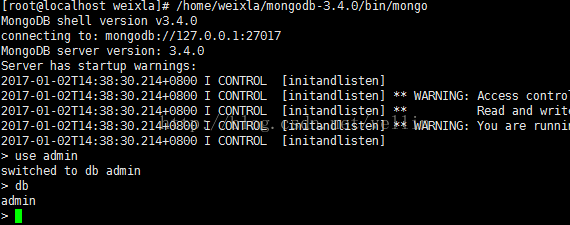
定义副本集配置变量,其中_id为上面定义的副本集名称
config={_id:"TestReplicaSet",members:[{_id:0,host:"192.168.10.101:27017"},{_id:1,host:"192.168.10.102:27017"},{_id:2,host:"192.168.10.103:27017"}]}
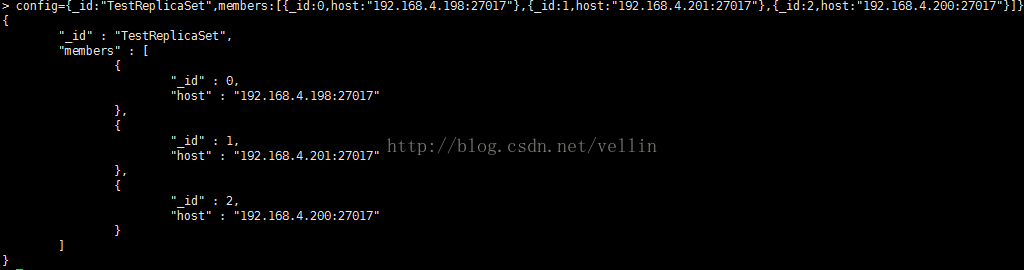
初始化副本集 rs.initiate(config)
服务端打印大量日志,目的就是通过选举策略选出主节点和副节点
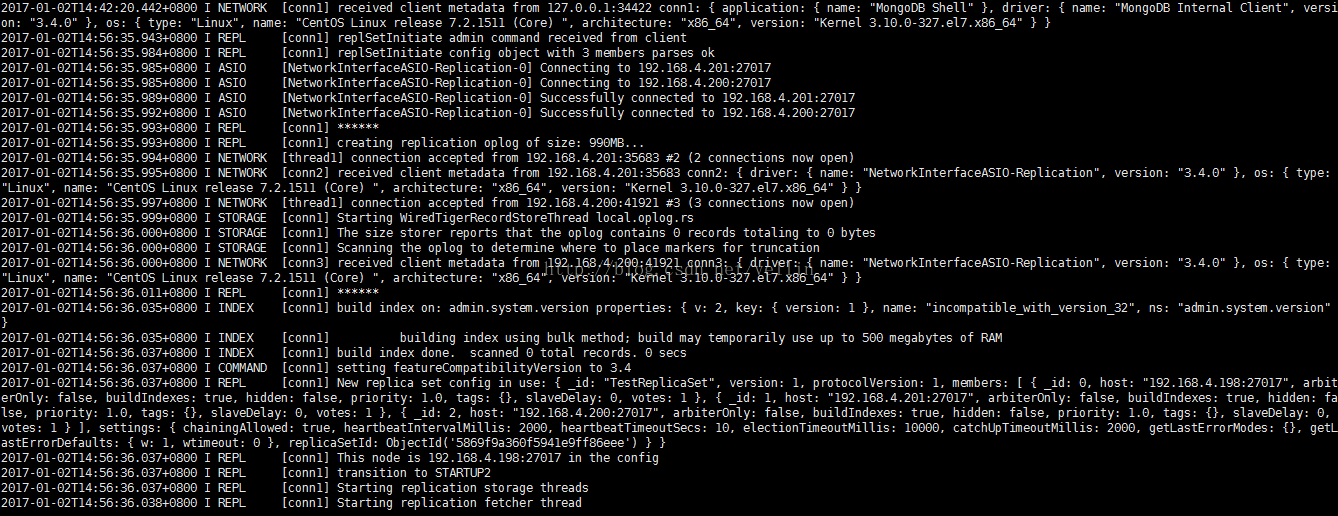
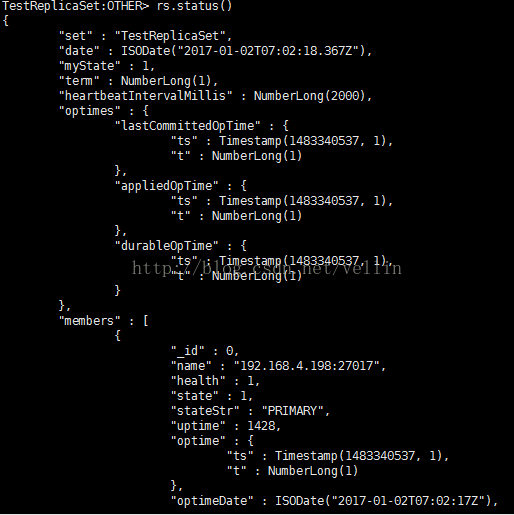
在客户端查看副本集状态 rs.status()
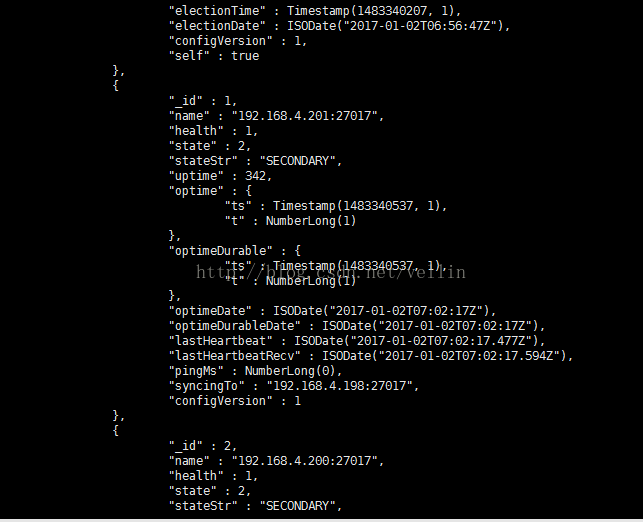
4、测试数据复制
在主节点插入一条数据
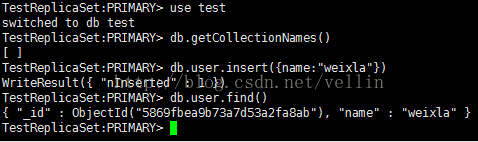
连接副节点进行查询
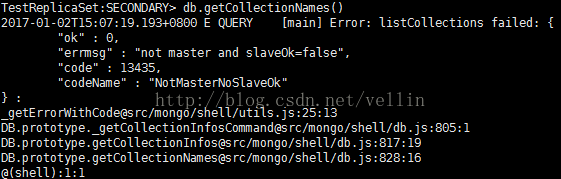
mongodb默认是从主节点读写数据的,副本节点上不允许读(更不能写入),需要设置副本节点可以读

这里测试结果达到预期一样,在副本节点数据进行了同步。
5、测试故障转移
首先停掉主节点,这里会打印大量日志,大概是重新选举相关操作。
查看副本集节点
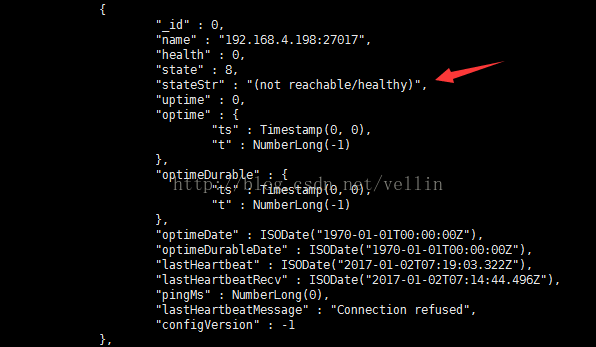
再查看其它两个节点,这里201(就是199,IP被占用了)保持为副节点,200却成为了主节点。
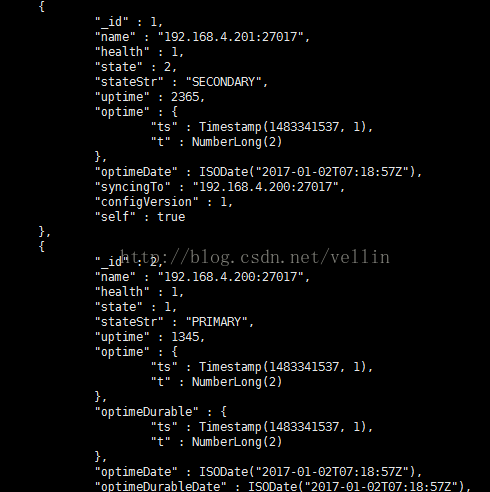
目前看起来支持完美的故障转移了
参考:https://docs.mongodb.com/manual/replication/















 5234
5234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









