







先前的博客中介绍了我们对 K8s 定时的使用[1]以及K8s 中定时任务的源码实现[2], 但是实际使用过后, 发现在使用时会遇到一些问题, 我就这些问题分别探讨下解决方案, 希望能对大家有所帮助, 最后会附上建议。
Kubernetes 中 Cron 任务的一些使用[3]Kubernetes 中 CronJob 源码阅读[4]
遇到的几个问题
1、机器上大量定时任务的存在, 导致 docker 的负担很重, 严重时甚至影响内核速度, 具体现象请看记一次 Kubernetes 机器内核问题排查[5]
我认为这一点并不是 K8s 的设计有问题, 设计之初没有考虑到 docker 在机器上的性能不够, 无法批量快速的创建容器, 并且会拖慢整个系统. 此问题的我们是通过物理隔离来解决的, 将定时任务限制在固定的几台机器, 能有效降低集群中其他机器的内核问题的出现概率.
2、定时任务运行时间非常不准确, 有些任务的执行时间会被拖到延迟几分钟,
延迟问题的出现并不是单一的原因, 有以下几种类型:
K8s 本身调度延迟, 本应该按时启动的任务拖了很久
与上面的原因一致, 机器中 docker 的负担太重, 几秒可以启动的容器慢了半分钟, 我不太清楚这个问题在读者的集群中是否有出现, 但是我们的集群中特别明显, Pod 处于 ContainerCreating 的状态会很久
K8s 对于定时任务的改进
在 2021 年的时候, CronJob API 到了 GA 阶段, 一个重要的变动就是将定时任务控制器换成了 v2. 原文在这里.
https://kubernetes.io/blog/2021/04/09/kubernetes-release-1.21-cronjob-ga/
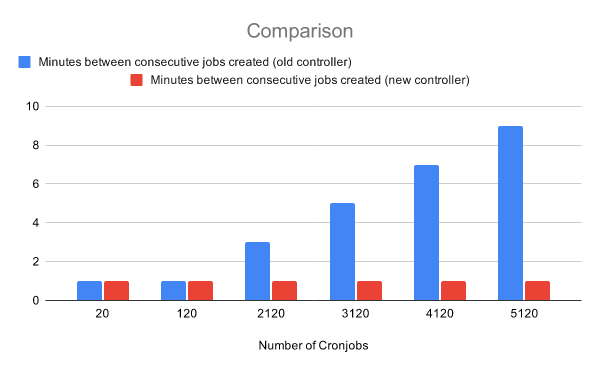
原始的控制器, 每 10 秒检查所有的定时任务是否需要执行, 这个操作只能由单个 worker 来实现, 具有 O(n)的线性复杂度, 当定时任务过多的时候, 性能会变得糟糕. K8s 在 1.19 引入了新的定时任务控制器, 转变了实现的策略.
相关代码实现
// pkg/controller/cronjob/cronjob_controllerv2.go
// NewControllerV2 creates and initializes a new Controller.
func NewControllerV2(jobInformer batchv1informers.JobInformer, cronJobsInformer batchv1informers.CronJobInformer, kubeClient clientset.Interface) (*ControllerV2, error) {
jm := &ControllerV2{
// 这个队列为延迟型队列, 可以在给定的时间后延迟入队
// t := nextScheduledTimeDuration(sched, now)
// jm.enqueueControllerAfter(curr, *t)
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "cronjob"),
recorder: eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: "cronjob-controller"}),
jobControl: realJobControl{KubeClient: kubeClient},
cronJobControl: &realCJControl{KubeClient: kubeClient},
jobLister: jobInformer.Lister(),
cronJobLister: cronJobsInformer.Lister(),
jobListerSynced: jobInformer.Informer().HasSynced,
cronJobListerSynced: cronJobsInformer.Informer().HasSynced,
now: time.Now,
}
// 添加hook, 定时任务的变动会触发通知, 允许控制器对任务进行处理
cronJobsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueController(obj)
},
UpdateFunc: jm.updateCronJob,
DeleteFunc: func(obj interface{}) {
jm.enqueueController(obj)
},
})
return jm, nil
}
// Run starts the main goroutine responsible for watching and syncing jobs.
func (jm *ControllerV2) Run(ctx context.Context, workers int) {
// 可以启动多个worker并行处理
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, jm.worker, time.Second)
}
}
func (jm *ControllerV2) worker(ctx context.Context) {
for jm.processNextWorkItem(ctx) {
}
}
func (jm *ControllerV2) processNextWorkItem(ctx context.Context) bool {
// 由于延迟入队的机制, 我们从队列中取到的数据, 一定是当前需要执行的定时任务
key, quit := jm.queue.Get()
if quit {
return false
}
defer jm.queue.Done(key)
requeueAfter, err := jm.sync(ctx, key.(string))
switch {
case err != nil:
utilruntime.HandleError(fmt.Errorf("error syncing CronJobController %v, requeuing: %v", key.(string), err))
jm.queue.AddRateLimited(key)
case requeueAfter != nil:
jm.queue.Forget(key)
// 入队时间推迟到下次任务执行
jm.queue.AddAfter(key, *requeueAfter)
}
return true
}CronJob v2 的实现利用了 K8s api server 的订阅通知类型的实现方式:
将 etcd 数据中定时任务的状态类型进行分类, 分成了正在改动的定时任务以及稳定运行的定时任务. 通过这个分类, 定时任务执行时不需要轮询整个列表, 而仅仅是从队列中取到需要执行的任务.
将定时任务的执行权功能, 利用队列分发给了多个协程, 能有效应对定时任务高并发的问题.
更新之后的性能优化看起来很明显
我们对于定时任务的改进
背景
上述 K8s 对于定时任务的优化, 我们集群时用不上的, 因为集群比较旧, 还没有这种支持. 另外一点就是, 上面的方案仅仅降低了任务调度时的时间, docker 负担太重的问题仍然没有解决. 鉴于机器负担过重, 以及定时任务执行时间不准确的问题, 我们提出了一个解决方案, 将高频运行定时任务的 Jod 生命周期延长.
方案设计
举例来说, 用户期望
/bin/my_script要每分钟运行一次. 针对我们的方案, 启动 Pod 后, 人为使 Pod 存在 1 小时或是更久的时间, 在 Pod 内部添加 cronjob 调度, 每分钟执行一次/bin/my_script. 当然 Pod 存在的时间是可以调整的, 我们人为的设定是一小时, 为了使任务能够分散的到各个运行机器中.
原始的 CronJob 如下
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure改造后的 CronJob 如下
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
# 降低运行频率
schedule: "0 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/do-cron # 通过自己的脚本, 创建cronjob, 开启crond
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
env:
- name: CRON_SCHEDULE # 通过环境变量, 将原始的cron传入容器中
value: "* * * * *"
restartPolicy: OnFailure方案存在的问题以及如何解决
方案的好处:
机器的负担大大降低, 1 小时创建 60 个 Pod, 变成了 1 小时 1 个 Pod
定时任务的运行时机更加准确, 单机的任务每分钟运行基本不存在误差, 对于比较需要精细控制的定时任务十分友好
这样会带来的一些问题:
将 Pod 生命周期延长, 每次 Pod 启动, 上一个 Pod 可能已经关闭, 或是还未关闭, 会造成任务丢失或是任务重复
将 Pod 生命周期延长, 每个 Pod 可能会并行执行多个任务, 会使得资源控制不够精确
针对第一个问题, 我们可以通过一定机制避免其发生, 但是针对第二个问题, 由于设计本身的问题, 没有什么比较好的解决方案. 在实际使用上, 我们遇到的高频定时任务对资源不是很敏感.
如何确保定时任务的可用性及稳定性
这个部分涉及到实现的细节部分, 我只是介绍下一些逻辑, 不涉及到具体代码, 需要考虑的方面有以下两个:
如何能够无缝的衔接定时任务的执行, 确保不会丢失或是重复
在用户修改任务或是部署新版本后,如何能够尽快的刷新更新定时任务
容器冗余
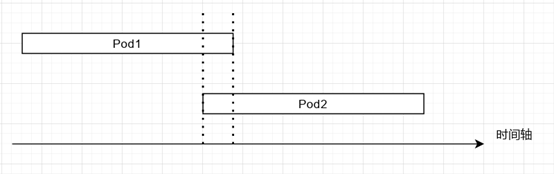
不丢失任务:
在启动新的 Pod 之后, 旧的 Pod 并不会马上下线, 我们为其提供了一小段缓存区间, 如图所示, 时间轴上的虚线区域, 两个 Pod 同时在运行. 如此设计, 我们可以保证不会丢失任务
不重复任务:
我们的每个容器有容器令牌的概念. Pod1 运行时, 拥有令牌, 当我们启动 Pod2 后, Pod1 会在合适的时机释放令牌, Pod2 只有获得到令牌之后才可以执行定时任务. 释放以及获取令牌的时机也很重要, 对于 Pod1 我们会在某一分钟开始后第 10s 开始释放, 也就是在一分钟的前半段释放令牌, Pod2 就可以拥有 50s 左右的时间获取该令牌, 这个时间很充足, 足够 Pod2 获取应用令牌, 开始执行下一次任务.
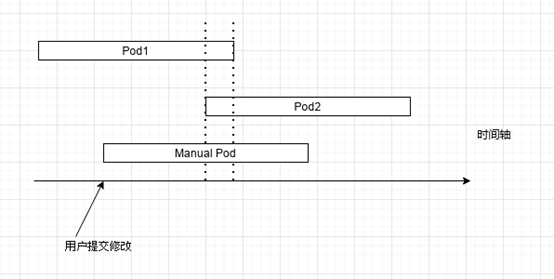
分离执行
定时任务的执行中, 用户很有可能在非整点的时候切换版本或是修改定时任务. 一旦发生, 上述的容器冗余能保证我们在下个调度周期更新, 但是用户修改任务或是上线版本时, 希望它能够马上生效, 而不是等待(有可能一个小时后才生效). 基于此设想, 我们考虑了一种分离普通定时任务与手动改变任务的方式, 下面就是具体的逻辑图:
这里的实现主要使用了 K8s 的定时任务的一个功能:
kubectl create job --from=cronjob/<cronjob-name> <job-name>手动创建的脚本也同样会获取令牌, Pod1 会提前结束, 一直到 Pod2 开始运行前, Manual Pod 都承担运行脚本的任务. 这里的思路就是分离日常行为以及突发行为.
使用定时任务的建议
确定定时任务量级, 是每小时一次还是每分钟分钟一次
确定定时任务运行延迟的容忍度, 是否能接受定时任务慢几分钟
物理隔离定时任务机器, 即使使用了我们自己的策略, 每个定时任务的 Pod 生命周期增加了, 我们也发现定时机器 io 使用率很高, 建议这类机器直接加 SSD.
注意做好日志记录, 以及相关报警
总结
我只是粗浅的介绍下我们对于定时任务的优化, 具体的细节有很多, 特别是对定时任务的监控代码比它的实现代码还要多. 我们的策略已经在线上运行了超过一年, 应该是比较稳定的功能了, 所以把设计策略分享出来给大家参考下.
有些时候我们使用某些框架可能正好是顺手就用, 但是随着业务的发展, 需要逐步对框架进行定制以及优化来适应业务需求. 可持续的解决业务开发需求, 才能有效推进 K8s 组件的落地.
用了开源的组件就要有觉悟, 你需要自己去定制某些策略来解决问题, 你的任何行为也也不会有人对你负责. 可以看下这篇帖子自己搭的 Gitlab 开放到公网被黑了[6].
引用链接
[1]
对 K8s 定时的使用: https://corvo.myseu.cn/2020/01/07/2020-01-07-Kubernetes中Cron任务的一些使用/
[2]K8s 中定时任务的源码实现: https://corvo.myseu.cn/2020/01/08/2020-01-08-Kubernetes中CronJob源码阅读/
[3]Kubernetes 中 Cron 任务的一些使用: https://corvo.myseu.cn/2020/01/07/2020-01-07-Kubernetes中Cron任务的一些使用/
[4]Kubernetes 中 CronJob 源码阅读: https://corvo.myseu.cn/2020/01/08/2020-01-08-Kubernetes中CronJob源码阅读/
[5]记一次 Kubernetes 机器内核问题排查: https://corvo.myseu.cn/2021/03/21/2021-03-21-记一次kubernetes机器内核问题的排查/
[6]自己搭的 Gitlab 开放到公网被黑了: https://v2ex.com/t/836253?p=1
原文链接:https://corvo.myseu.cn/2022/02/27/2023-02-27-Kubernetes%E4%B8%ADCronJob%E7%9A%84%E6%94%B9%E8%BF%9B%E4%BB%A5%E5%8F%8A%E6%88%91%E4%BB%AC%E7%9A%84%E5%AE%9A%E5%88%B6%E5%8C%96%E9%9C%80%E6%B1%82/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









