






两个多月前,Grafana 实验室宣布与 Cilium 母公司 Isovalent 建立战略合作伙伴关系[1],希望通过 Grafana 开源的可观测性全家桶组件,帮助各个基础架构团队深度探测 Kubernetes 集群工作负载的安全、性能和相互之间的连接状况。在这之前,Grafana 实验室还参与了 Isovalent 的 B 轮融资[2],并启动了相关的联合工程计划。
这两家公司都相信,在这个 API 驱动的应用时代,应用之间连接的可观测性(connectivity observability)起着至关重要的作用。为此,Isovalent 的 CEO Dan Wendlandt 专门写了一篇文章来探讨使用传统方案来观测云原生应用之间连接的健康状况与性能是多么困难,以及如何使用 eBPF 来从根本上解决这个问题。
❝划重点:connectivity observability 是个新词,如果翻译成“应用之间连接的可观测性”就太长了,后面我们统一就叫它应用连接可观测性吧。
本文会讨论 Cilium 项目(由 eBPF 驱动)是如何打造一个标准来让 Kubernetes 集群中工作负载之间的连接变得更加安全,并且可观测。本文还会深入探讨如何将 Cilium 丰富的应用连接可观测性数据与 Grafana 实验室开源的 LGTM(Loki[3] 用于日志,Grafana[4] 用于可视化,Tempo[5] 用于分布式追踪,Mimir[6] 用于监控指标)可观测性组件全家桶进行结合,帮助应用研发人员与基础架构团队更轻松且更深入地观测应用之间连接的健康状况与性能。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是正文内容的译文。
在正文开始之前,先给大家介绍下 Dan Wendlandt 这个人,他是 Isovalent 的联合创始人兼 CEO,之前在 Nicira 公司负责推动并领导社区和产品战略。Nicira 这个公司现在可能没多少人听说过,毕竟现在是云原生的时代。10 年前应该有很人听过这个公司,它是软件定义网络(SDN)的领军者之一,旗下有大名鼎鼎的开源项目 Open vSwitch (OVS),其 CTO Martin Casado 还是 OpenFlow 协议的第一份草案的撰稿人。2012 年 Nicira 被 VMware 收购后,OVS 就被拿来开刀了,VMware 基于 OVS 打造了一个网络虚拟化平台叫 Vmware NSX。
Dan Wendlandt 与另外一位大佬 Thomas Graf(Linux 内核开发者,Cilium 项目创始人) 共同创建了 Isovalent 这个公司,他坚信 eBPF 会成为后云原生时代的救星,可以给云原生时代的微服务应用之间的网络和安全带来质的飞跃。
以下真的是正文内容的译文。。
云原生应用连接可观测性
将云原生时代的应用构建为 API 驱动的服务集合有千般万般的好处,但惟独不包含监控和故障排查。因为在云原生和微服务的世界中,用户随便点一下鼠标都可能会调用几十个甚至几百个 API,底层连接中的任何故障或者延迟都会对应用的行为产生负面影响,但是我们却很难排查到根本原因并根治它。
而且 Kubernetes 会动态地将每个服务的不同副本作为容器调度到由不同 Linux 机器组成的大型集群中,这会使问题变得更加复杂。Kubernetes 这种架构很难确定遇到连接故障的工作负载在某一特定时间点的运行位置,就算能确定位置,由于容器的多租户特性,应用研发人员也不能直接使用网络调试工具(例如 netstat、tcpdump)来排查故障。
如此一来,应用研发团队与 Kubernetes 平台运维团队将会陷入两难的境地。虽然云原生时代的应用连接可观测性比以往任何时候都重要,但实现起来却比以往任何时候都困难。
全面应用连接可观测性的挑战
深度观测 Kubernetes 应用之间连接的健康状况和性能是一个巨大的挑战,主要体现在两个方面:
挑战一:连接是分层的(“互相甩锅问题”)
最常见的情景是这样的:应用研发团队收到了某个用户报告某个应用出现了故障或者响应缓慢,他们感觉是底层网络的问题,于是甩锅给平台运维团队。但是平台运维团队在基础架构相关的组件中并没有发现哪里出了问题,于是又甩锅给应用研发团队,甚至还可能甩锅给 IaaS 层或者云厂商。这就是传说中的“互相甩锅问题”。

网络连接是分层的,每一层都有不同的职责,这个分层的模型叫做 “OSI 网络模型”。虽然你可能会经常听到一些精通网络的大牛夸夸其谈数据链路层、网络层、传输层和应用层,但是这些内容在本文所探讨的挑战中都不重要,我们只需要知道每一层的根本目的是抽象出它下面各层的细节。没发生故障时万事大吉,一发生故障就傻眼了,因为这种网络分层模型会有意地将低层的故障隐藏在高层之中。
最终的结果是,无法通过观测单一网络层来实现全面应用连接可观测性,靠应用本身也无法实现(因为它只能观测到 L7)。要想实现全面应用连接可观测性,必须能观测到所有网络层,并将所有网络层关联起来。
挑战二:应用身份(“信噪比问题”)
Kubernetes 的调度能力非常强大,即便是中等规模的多租户 Kubernetes 集群也可以轻松运行数以千计的服务,每个服务都包含多个副本,这些副本都分散在数百个 Worker 节点上。想在这样的环境中观测单个应用的连接性,简直是个噩梦,因为底层连接太“嘈杂”了。
以前大家的应用都跑在物理机或虚拟机上,网络环境一般都是 VLAN 和各种子网,那时候的 IP 地址或子网可以直接用来识别特定的应用,因为应用的 IP 地址是长期有效的,不会频繁变化,因此我们可以根据特定 IP 的网络日志或计数器来分析应用的行为。云原生时代就不同了,工作负载都运行在容器中,而容器的生命周期很短,不断被销毁重建,因此不能将 IP 地址作为应用的有效标识。即使在 Kubernetes 集群之外,IP 地址也会不断变化,例如当应用研发人员使用来自云提供商(如 AWS)或其他第三方(如 Twilio)外部 API 时,每次连接的目标 IP 地址都是不同的。因此我们不能再使用基于 IP 的网络日志来分析应用的行为。
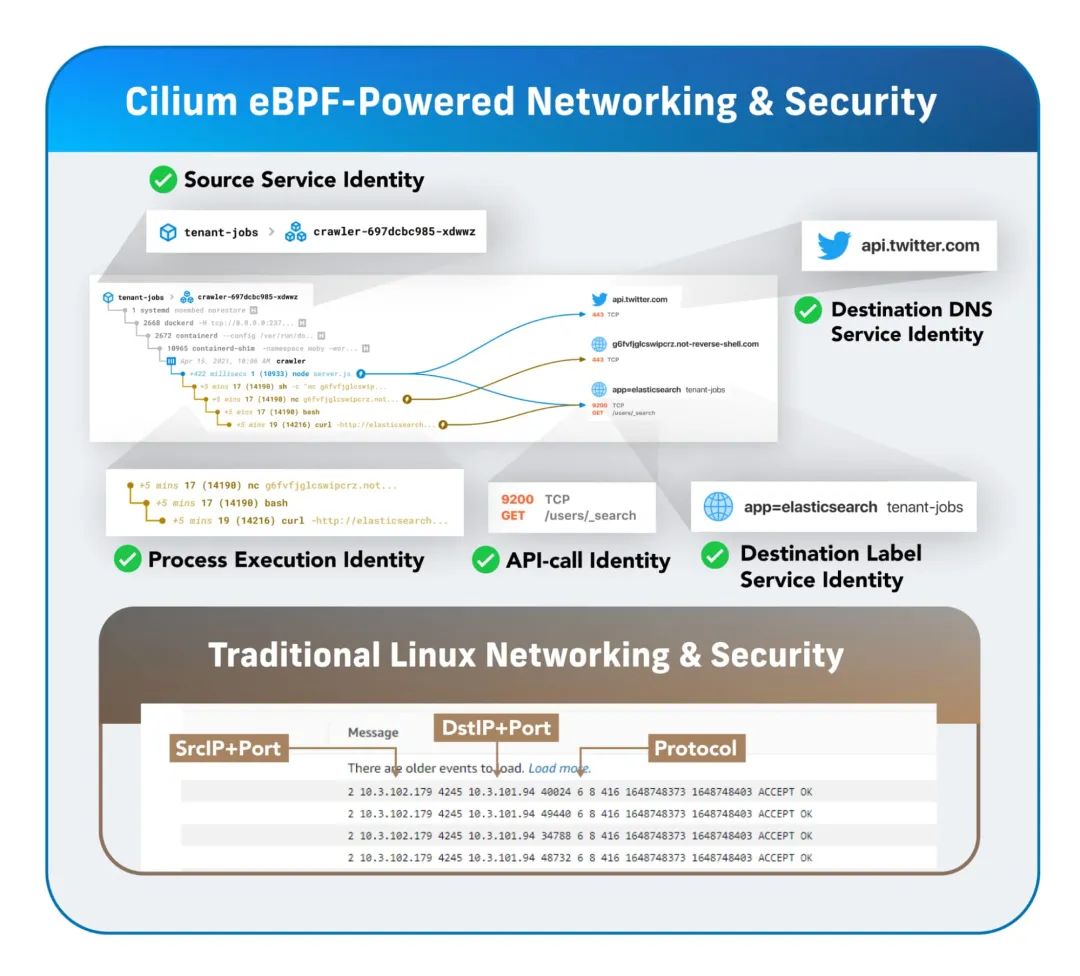
对于现代应用而言,使用 IP 地址作为连接的来源或者目标的标识不再具有任何意义,因为所有的可观测性工作都必须建立在长期有效的“服务身份”背景下。对于 Kubernetes 中运行的工作负载而言,可以使用与每个应用相关的元数据 label(例如,namespace=tenant-job, service=core-api)来作为服务的身份。对于 Kubernetes 外部的服务而言,可以使用 DNS 名称(例如,api.twilio.com 或 mybucket.s3.aws.amazon.com)来作为服务身份。
传统可观测性方案的不足
考虑到上述的“互相甩锅问题”与“信噪比问题”,我们来看看传统可观测性方案的不足之处:
传统的网络监控设备在多个方面都有限制,而且它们都是集中式设备,很容易成为瓶颈。除此之外,它们的可观测性通常都不会对连接的来源和目标赋予特定的服务身份。
云厂商的网络流量日志(例如,VPC 流量日志)倒不会成为集中的瓶颈,但仅限于网络层的可观测性,因此缺乏服务身份和 API 层的可观测性。而且它们还与底层的基础设施紧密相关,不同的云厂商之间并不兼容。
Linux 主机的统计信息包含了部分与网络故障相关的数据,但是在 Kubernetes 集群中,操作系统并不能通过“服务身份”来区分主机上运行的多个容器实例。此外,操作系统也不知道连接目标的服务身份,还缺乏 API 层的可观测性。
基于 Sidecar 的服务网格(例如 Istio)号称可以在不修改应用代码的前提下提供丰富的 API 层可观测性,但是代价很大,牺牲了更多的资源、性能和操作复杂度。除此之外,服务网格对于网格外部服务的可观测性也是能力有限,而且由于 Sidecar 代理只能操作 API 层,所以对于网络层的故障和瓶颈也无能为力。
基于 eBPF & Cilium 的可观测性方案
eBPF 是一个全新的 Linux 内核革命性技术,由 Isovalent 在上游共同维护。目前 eBPF 支持所有主流的 Linux 发行版,它提供了一种安全高效的方式来将额外的内核级功能注入到 “eBPF 程序”。无论你想在内核中执行哪些系统调用(例如网络访问、文件访问、程序执行等),eBPF 程序都可以安全且无干扰地执行。
Cilium 没有利用 iptables 等传统的内核级网络功能,而是采用了原生的 eBPF,从而实现了高效强大的网络连接,网络安全性也大大提高,除此之外 Cilium 还将可观测性作为内置的一等公民。目前全球领先的企业和电信公司都有在用 Cilium 作为网络插件,甚至连谷歌云、AWS 和微软 Azure 的 Kubernetes 产品都将 Cilium 作为默认的 CNI 插件。早在 2021 年,Isovalent 就将 Cilium 捐给了云原生计算基金会(CNCF)[7]。
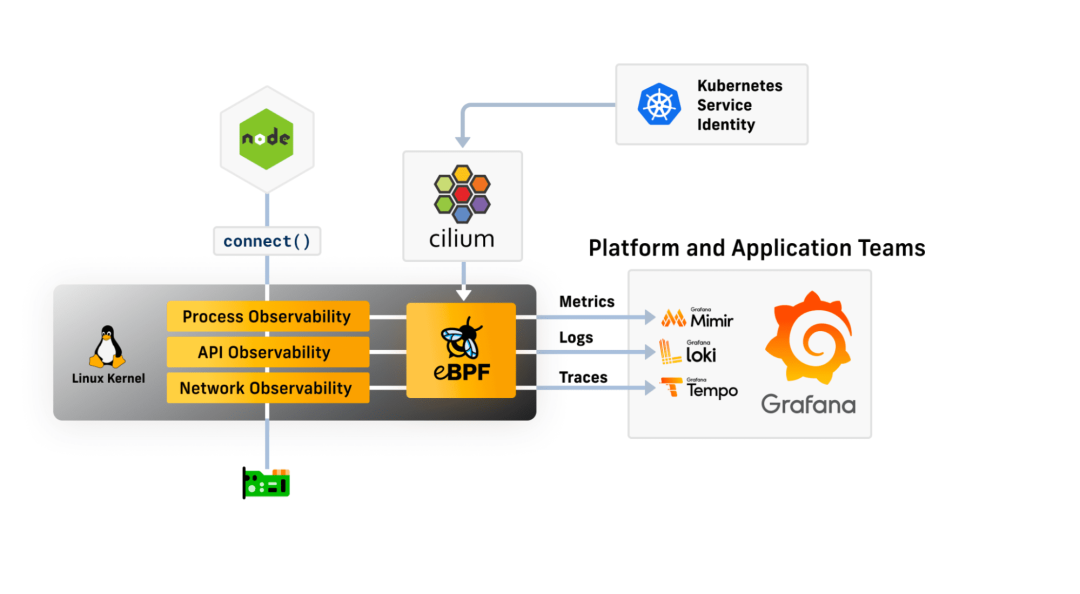
在 eBPF 的加持下,Cilium 可以确保所有的可观测性数据不仅与 IP 地址相关,而且与网络连接两端应用的更高级别服务身份相关。再加上 eBPF 程序运行在 Linux 内核中,无需对应用本身作任何修改,也无需使用更复杂的重量级服务网格,就可以实现上述的可观测性,它会将可观测性功能透明地插入到现有的工作负载下,非常便于横向扩展。
Cilium 可以收集到非常丰富的“可感知服务身份”的与连接相关的指标和事件流,再联合 Grafana LGTM 全家桶,简直是天作之合。
下面我们通过三个具体的示例来说明这两个家伙组成的 CP 如何解决 Kubernetes 平台运维团队与应用研发团队的“互相甩锅难题”。
示例 1:无需更改应用(也无需 Sidecar)观测 HTTP 黄金信号
一般大家都会使用 HTTP 黄金信号(HTTP Golden Signals)指标来作为 HTTP(即 API 层)连接健康状况的三个关键指标,这三个指标分别是:
HTTP 请求速率;
HTTP 请求延迟;
HTTP 请求响应码。
Cilium 可以在不修改应用的前提下收集这些监控数据,而且是根据长期有效的服务身份来汇总相应的指标。
回到之前的“互相甩锅问题”,如果应用研发团队发现应用连接出现了故障,他们可以根据 HTTP 黄金信号明确判断出故障的根源到底在哪里。如果是 API 层,那么这个问题需要应用研发团队自己处理;如果是网络层,那么就需要基础设施团队进行处理。
再回到之前的“信噪比问题”,由于所有的监控指标都使用有意义的服务身份来标记,不管是平台运维团队还是应用研发团队,都可以很轻松地使用 Grafana 的过滤功能来排除与当前故障无关的其他应用的监控信息,只关注标记了相应团队名称的服务即可,甚至可以锁定特定的服务,无需了解该服务的容器实例运行在哪里。
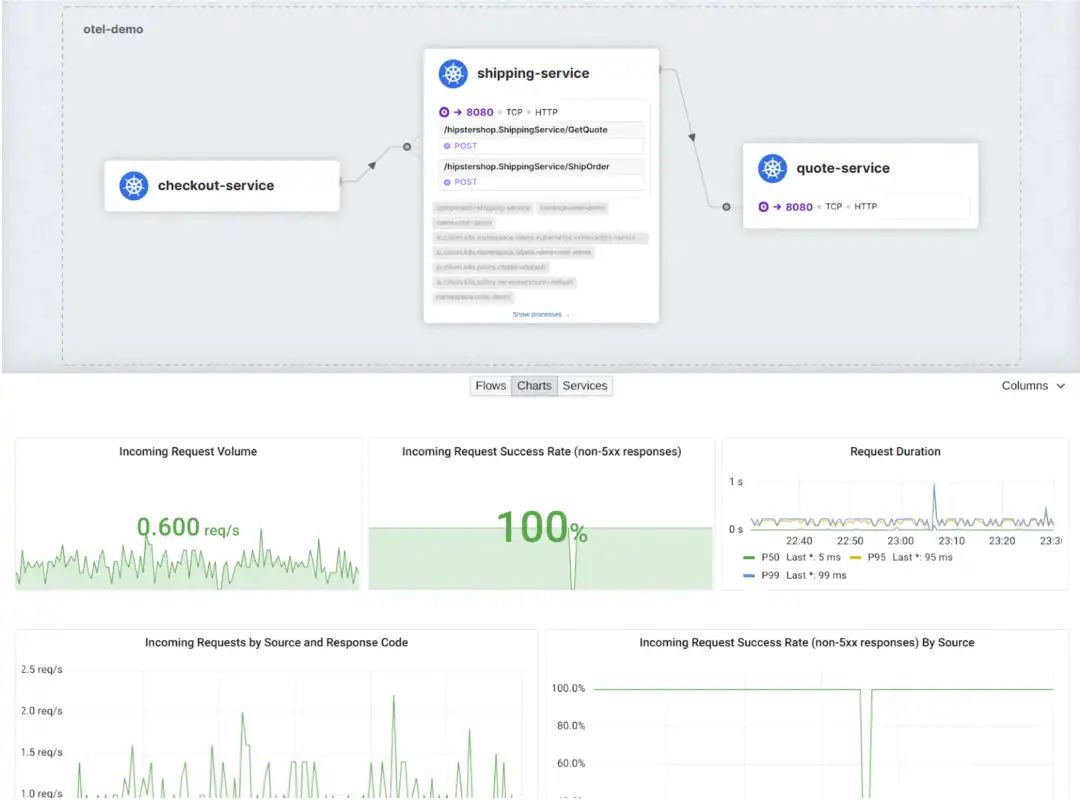
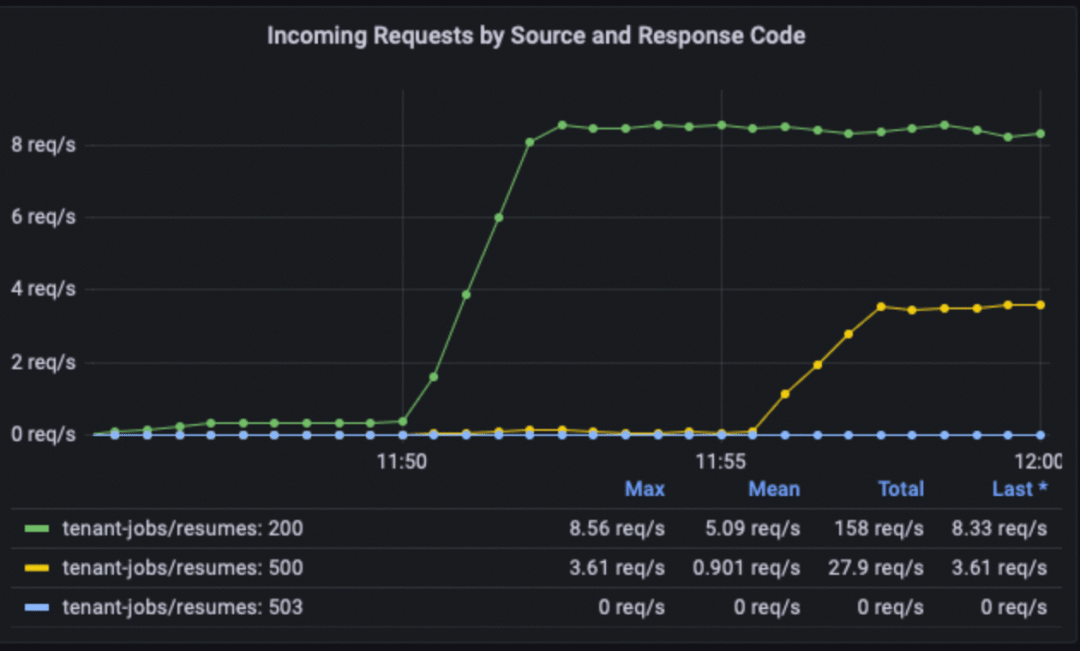
举个例子,下面的 Grafana 监控面板展示了命名空间 tenant-jobs 中的特定应用服务 core-api 所有入站连接的响应码。从监控面板可以很直观地看出 core-api 服务正在被另一个服务 resumes 访问,起初都很正常,但在 11:55 左右,500 响应码的数量开始增加,很明显这两个服务之间的连接在 API 层出现了问题,必须由负责 core-api 服务和 resumes 服务的应用研发团队来解决。
示例 2:监测瞬息万变的网络层问题
故障总是无处不在,它可能发生在 OSI 网络模型的任意一层,如果“非 API 层”的组件出现了连接故障,由于应用研发团队能力有限,所以很难发现潜在的网络问题,也不太可能清晰地说出这个问题应该找谁解决。
举个例子,假设用户反馈某个应用在几个小时前的一个非常短暂的时间窗口中出现了性能降低和应用层超时的现象,用户查看应用日志也看不出哪里有问题,而且应用的 CPU 负载也没有任何异常,这会不会是网络层的问题呢?
Isovalent 在其商业产品中对 Cilium 进行了扩展,可以直接利用内核级别的可观测性来提取 “TCP 黄金信号” 的指标数据:
发送/接收的 TCP 字节数;
TCP 重传表示网络层数据包丢失/拥塞;
TCP 往返传输时间(RTT)表示网络层的延迟。
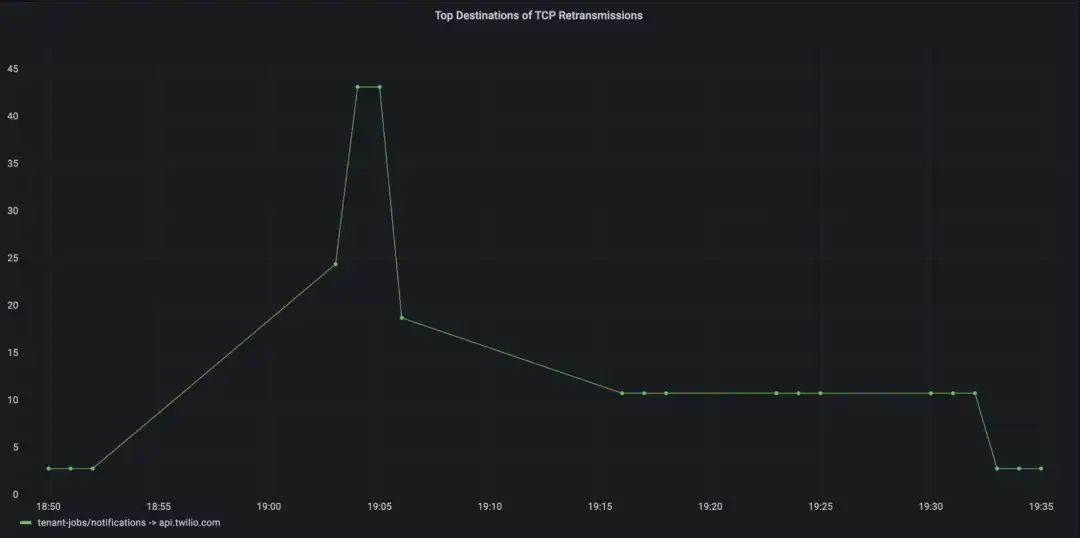
针对上述问题,我们来看看 Grafana 的监控面板,可以看到命名空间 tenant-jobs 中的某个特定服务 notifications 出现了短暂的 TCP 重传(即网络层数据包丢失),但仅仅是与外部服务 api.twilio.com 通信时才出现的 TCP 重传,而且时间窗口与用户反馈的故障时间窗口相吻合,基本可以断定这个故障与 api.twilio.com 有关。应用研发团队可以查看 Twilio 服务状态页面来确认故障发生的时间窗口中是否存在已知的服务中断,最终可以断定这个故障与应用研发团队的应用无关。
示例 3:使分布式追踪来识别异常 API 请求
Cilium & Grafana 除了可以抓取网络层与 API 层的监控数据,还可以与分布式追踪(通过 HTTP Header 传播标准追踪标识符的应用)相结合,实现多跳网络追踪。
大量的 HTTP 追踪数据本身就很容易让人不知所措,你根本就不知道这里面哪些数据可以帮助你解决问题。为了简化问题,Grafana 引入了一个非常强大的概念叫 “exemplars[8]”,当它与指标结合使用时,可以帮助你确定哪些追踪数据可以给你提供更详细的观测数据来帮助你解决问题。
回到示例 1 中的 core-api 服务,如果这个服务升级版本之后,请求延迟开始飙升,我们该怎么办?
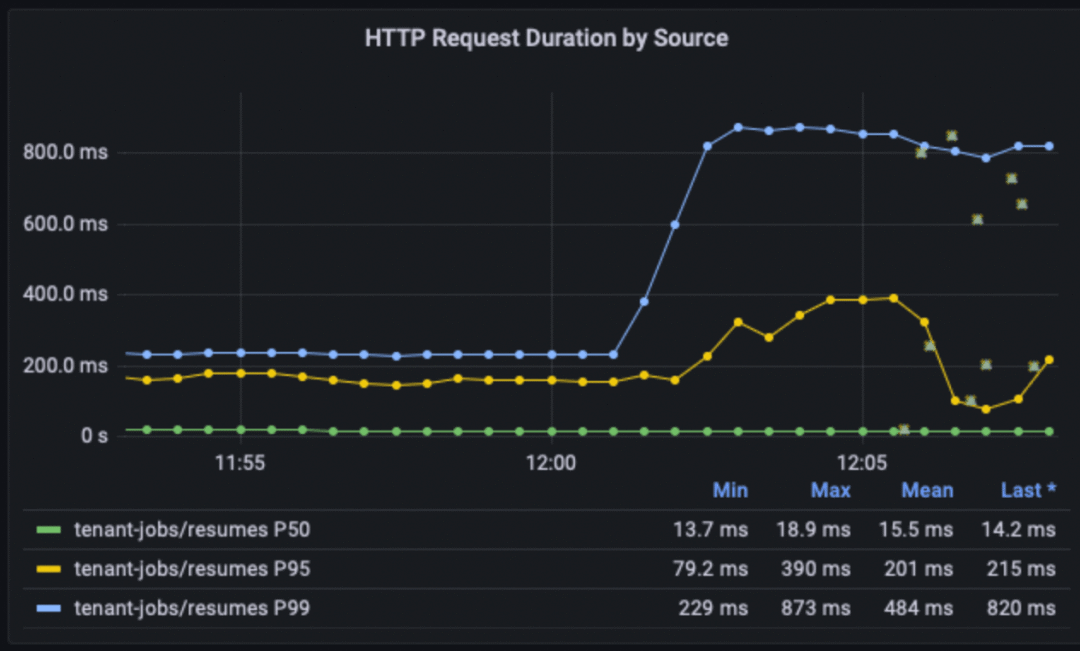
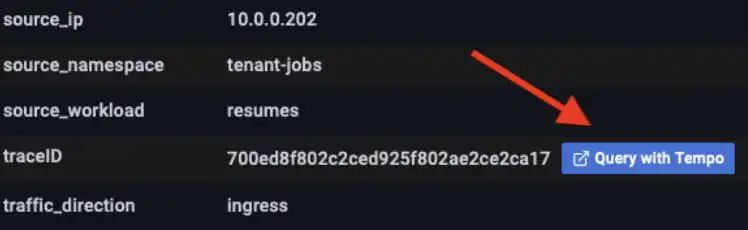
如果你足够细心,可以发现监控面板上有很多小绿框,它们是 resumes 服务和 core-api 服务之间各个 HTTP 请求的 Grafana “exemplars”。单击具有高延迟值的某个 exemplar 会出现一个窗口,该窗口提供了一个菜单选项来使用 Tempo 进行查询和可视化跟踪。
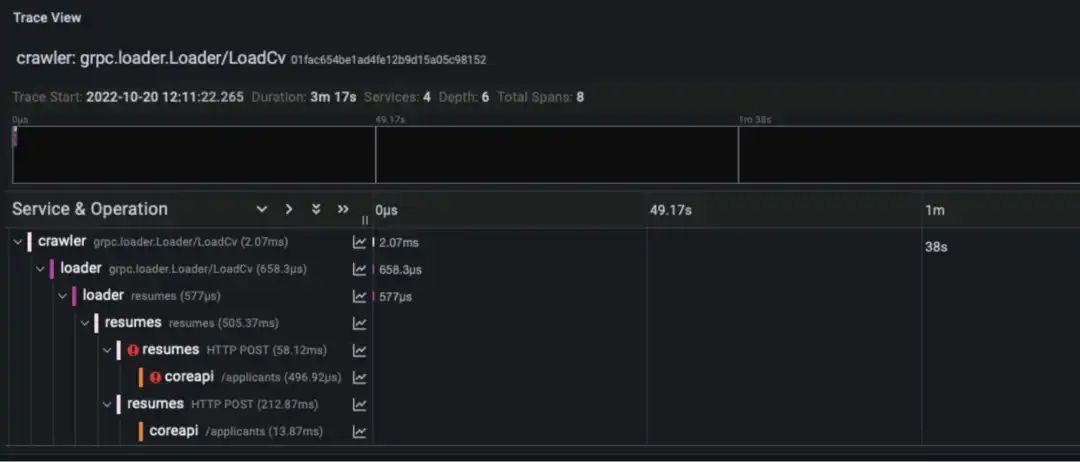
点击这个按钮,用户就可以看到 Tempo 中的全部跟踪细节,从下面的图中可以看出,可能是底层故障和重试引发了较高的延迟。
未来规划
预计在未来几周和几个月内,Grafana 实验室和 Isovalent 会联合产出更多的博客,包含更多的用例以及与 Grafana Cloud 进一步整合的消息。除了探索更多的可观测性用例之外,还会探讨 LGTM 全家桶如何与 Cilium Tetragon(Isovalent 开源的运行时安全项目)相结合,为威胁检测和合规性检测提供深度的运行时和网络安全观测能力。
上述的所有示例配置都在这个 GitHub 中:https://github.com/isovalent/cilium-grafana-observability-demo
感兴趣的同学可以自己实践一下。
引用链接
[1]
Grafana 实验室宣布与 Cilium 母公司 Isovalent 建立战略合作伙伴关系: https://grafana.com/about/press/2022/10/24/grafana-labs-partners-with-isovalent-to-bring-best-in-class-grafana-observability-to-ciliums-service-connectivity-on-kubernetes/
[2]Isovalent 的 B 轮融资: https://www.prnewswire.com/news-releases/isovalent-raises-40m-series-b-as-cilium-and-ebpf-transform-cloud-native-service-connectivity-and-security-301619134.html
[3]Loki: https://grafana.com/oss/loki/
[4]Grafana: https://grafana.com/oss/grafana
[5]Tempo: https://grafana.com/oss/tempo/
[6]Mimir: https://grafana.com/oss/mimir/
[7]早在 2021 年,Isovalent 就将 Cilium 捐给了云原生计算基金会(CNCF): https://www.cncf.io/blog/2021/10/13/cilium-joins-cncf-as-an-incubating-project/
[8]exemplars: https://grafana.com/docs/grafana/latest/fundamentals/exemplars/


你可能还喜欢
点击下方图片即可阅读
ChatGPT 帮我跑了一个完整的 DevOps 流水线,离了个大谱...



云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
















 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









