







欢迎关注: 阿里妈妈技术公众号
本文作者:石士、书浅 阿里妈妈技术团队
▐ 前言
随着号称“地表最强”的千亿参数规模GPT-3模型在 NLP 领域横扫各大数据榜单,大力出奇迹的暴力美学似乎成为了大数据场景建模的不二法门。搜索、推荐和广告场景的 CTR 模型也不例外,同样动辄千亿参数规模、上T体积大小的 CTR 模型成为了同行争相追逐的建模标配。但是无论面对生产运维环境,还是实验迭代环境,它对存储规模和计算性能的要求都是巨大的挑战。而且随着存量算力的逐渐耗尽和增量算力的趋势放缓,它的“大力暴力”成为了业务算法迭代的沉重负担。阿里妈妈搜索广告模型团队通过系统性的算法实践让原本庞大笨重的 CTR 模型轻盈转身,摇身一变“小巧且精悍”,数T模型压缩成几十G规模且预估精度无损,开辟了一条“小而美”的崭新的优化方向。
▐ 1. 超大规模模型演进之路的辩证思考
阿里妈妈搜索广告的 CTR 模型伴随直通车业务的发展持续迭代多年,主要包括两个优化路径,分别是特征优化和模型结构优化。特征优化主要包括多模态特征的丰富、高阶特征的升级和动态特征的引入等;模型结构优化主要包括围绕搜索意图挖掘的序列建模 Transformer 系列和图建模 GNN 系列的改造等。因为同时期享受到硬件算力的增长红利,所以算法迭代显得非常阔绰,结合工程基建的迅猛发展,CTR 模型逐年变得既宽又深。直通车的日常 CTR 模型已经到了数T规模,暗合了“模型越大、预估能力越强”暴力美学的发展路径。
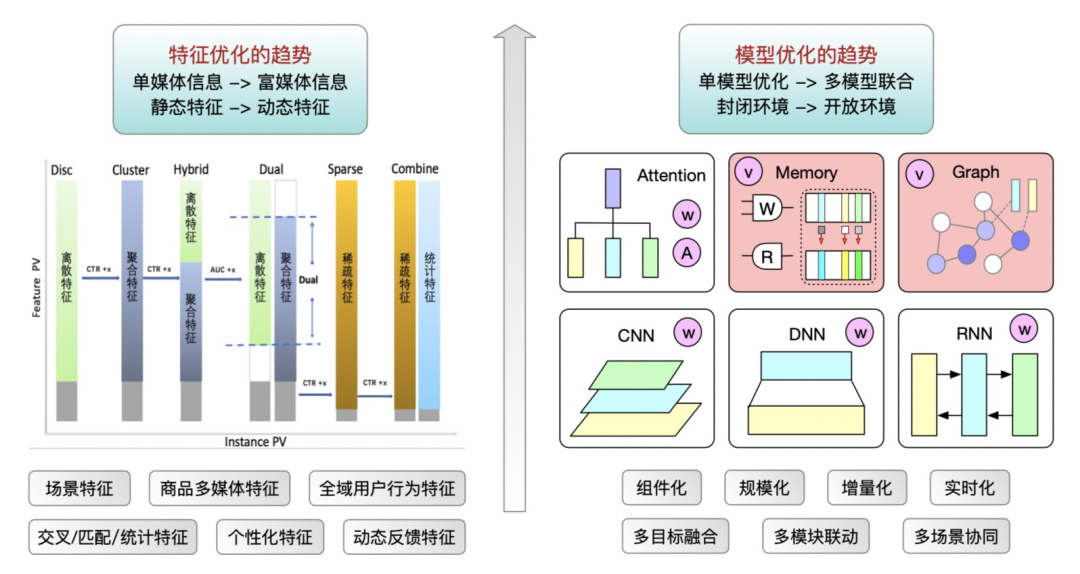
但是日益臃肿的 CTR 模型不仅给工程实现带来艰巨的挑战,也开始制约算法创新的迭代效率。单套模型所依赖的存储和计算资源开销不菲,考虑到多人迭代的实验场景,多套并行对系统压力更大。另外,真实的迭代环境是存量算力逐渐耗尽、增量算力又显著放缓。因此,我们不得不重新审视算法迭代的资源利用率问题,开始重视投入产出比对模型迭代效率的影响;而且重新思考超大规模的 CTR 模型是否具有普世价值,毕竟还有诸多中小场景的业务依赖模型提效,但能够配备如此规模的机器资源和工程能力是一种奢望。
于是,为了在有限资源的约束下,模型仍然能够高效迭代支撑业务快速发展,直通车 CTR 模型开始走上了“减肥瘦身”之路。考虑到广告场景的特殊性,模型预估能力的微小下降会使得线上产生营收的真实损失,所以直通车 CTR 模型在瘦身的同时要求保持预估精度不降,这对模型精简来说是个不小的挑战。我们认为在庞大冗余的模型结构中应该存在不必要的信息编码,且实践证明类似 dropout 相关的操作还能使得模型的鲁棒性和泛化性得以提升,这中间应该存在着“预估精度保持不变,模型规模显著降低”的优化空间。
搜索、推荐和广告场景的 CTR 模型的特点是高维、稀疏且离散,模型的绝大部分参数主要集中在特征的 Embedding 层,所以如何经济有效地压缩 Embedding 层的参数规模是 CTR 模型瘦身的关键。Embedding 层的压缩主要有3个方向&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









