







堆和栈:
栈主要用来存放局部变量, 传递参数, 存放函数的返回地址.esp 始终指向栈顶, 栈中的数据越多, esp的值越小.
堆用于存放动态分配的对象, 当你使用 malloc , new 等进行分配时,所得到的空间就在堆中. 动态分配得到的内存附带有分配信息, 所以你能够 realloc 和 free调它们.
全局,静态和常量是分配在数据区中的。数据区包括bss和初始化区。
堆向高内存地址生长
栈向低内存地址生长
堆和栈相向而生,堆和栈之间有个临界点,称为stkbrk

内存分配:
Linux 的虚拟内存管理有几个关键概念:
1、每个进程都有独立的虚拟地址空间,进程访问的虚拟地址并不是真正的物理地址;
2、虚拟地址可通过每个进程上的页表(在每个进程的内核虚拟地址空间)与物理地址进行映射,获得真正物理地址;
3、如果虚拟地址对应物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
一、Linux 虚拟地址空间如何分布?
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别为:
1、只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
2、数据段:保存全局变量、静态变量的空间;
3、堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
4、文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
5、栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
6、内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
下图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。
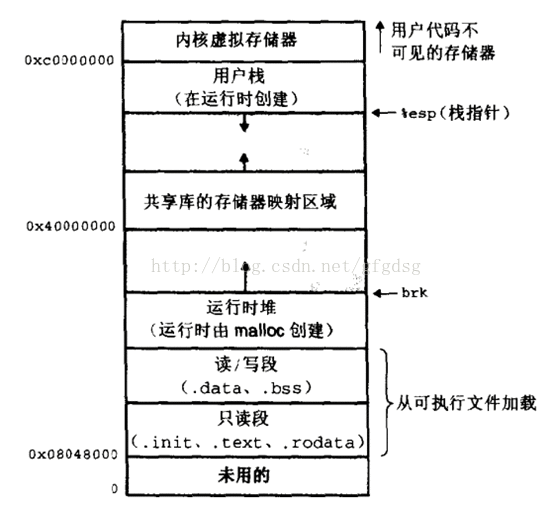
32 位系统有4G 的地址空间::
其中 0x08048000~0xbfffffff 是用户空间,0xc0000000~0xffffffff 是内核空间,包括内核代码和数据、与进程相关的数据结构(如页表、内核栈)等。另外,%esp 执行栈顶,往低地址方向变化;brk/sbrk 函数控制堆顶_edata往高地址方向变化。
二、malloc和free是如何分配和释放内存?
内存分配的原理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
下面以一个例子来说明内存分配的原理:
情况一、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
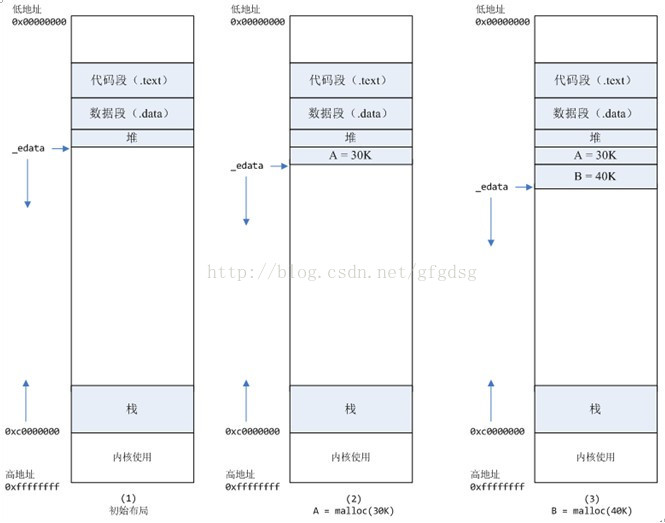
1、进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。
其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。
_edata指针(glibc里面定义)指向数据段的最高地址。
2、进程调用A=malloc(30K)以后,内存空间如图2:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
你可能会问:只要把_edata+30K就完成内存分配了?
事实是这样的,_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3、进程调用B=malloc(40K)以后,内存空间如图3。
情况二、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:
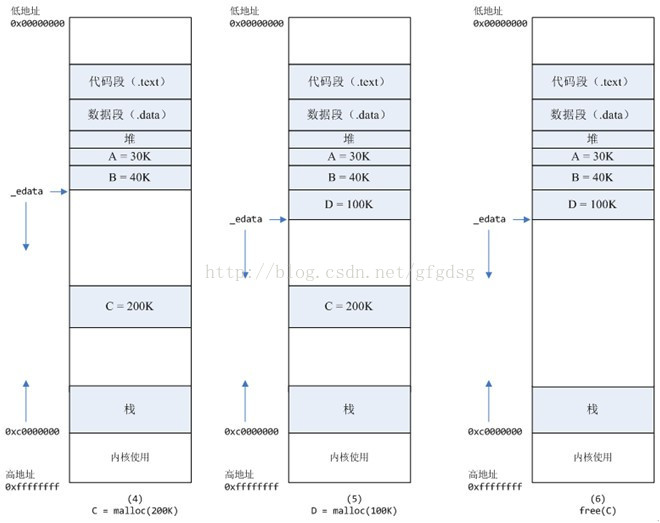
4、进程调用C=malloc(200K)以后,内存空间如图4:
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为::
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5、进程调用D=malloc(100K)以后,内存空间如图5;
6、进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。
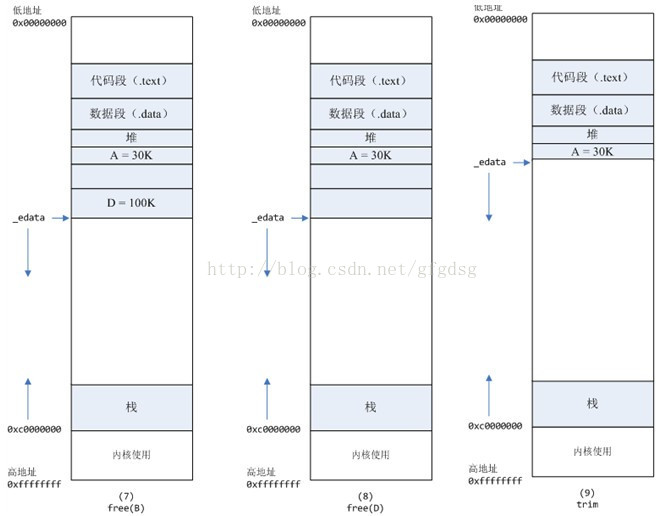
7、进程调用free(B)以后,如图7所示:
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8、进程调用free(D)以后,如图8所示:
B和D连接起来,变成一块140K的空闲内存。
9、默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
三、既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢?
既然堆内碎片不能直接释放,导致疑似“内存泄露”问题,为什么 malloc 不全部使用 mmap 来实现呢(mmap分配的内存可以会通过 munmap 进行 free ,实现真正释放)?而是仅仅对于大于 128k 的大块内存才使用 mmap ?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。 因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, <SIZE>) 来修改这个临界值。
因为要了解多线程,自然少不了一些硬件知识的科普,我没有系统学习过硬件知识,仅仅是从书上以及网络上看来的,如果有错误请指出来。
寄存器:
CPU,全名Central Processing Unit(中央处理器)。这是一块超大规模的集成电路,包含上亿的晶体管,是一台计算机的运算核心(Core)和控制核心(ControlUnit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
它的主要构成是:运算器、控制器、寄存器
运算器:可以执行定点或浮点算术运算操作、移位操作以及逻辑操作,也可执行地址运算和转换。
控制器:主要是负责对指令译码,并且发出为完成每条指令所要执行的各个操作的控制信号。其结构有两种:一种是以微存储为核心的微程序控制方式;一种是以逻辑硬布线结构为主的控制方式。
寄存器:寄存器部件,包括寄存器、专用寄存器和控制寄存器。通用寄存器又可分定点数和浮点数两类,它们用来保存指令执行过程中临时存放的寄存器操作数和中间(或最终)的操作结果。 通用寄存器是中央处理器的重要部件之一。
工作过程:
第一阶段,提取,从存储器或高速缓冲存储器中检索指令(为数值或一系列数值)。由程序计数器(Program Counter)指定存储器的位置。(程序计数器保存供识别程序位置的数值。换言之,程序计数器记录了CPU在程序里的踪迹。)
第二阶段:解码(控制器)
第三阶段:执行,算术逻辑单元(ALU,Arithmetic Logic Unit)将会连接到一组输入和一组输出。输入提供了要相加的数值,而输出将含有总和的结果。ALU内含电路系统,易于输出端完成简单的普通运算和逻辑运算(比如加法和位元运算)。如果加法运算产生一个对该CPU处理而言过大的结果,在标志暂存器里可能会设置运算溢出(Arithmetic Overflow)标志。
第四阶段:回写,缓冲Cache或者更大更廉价的低俗存储器(内存、硬盘等等)
寄存器:是集成电路中非常重要的一种存储单元,通常由触发器组成。在集成电路设计中,寄存器可分为电路内部使用的寄存器和充当内外部接口的寄存器这两类。内部寄存器不能被外部电路或软件访问,只是为内部电路的实现存储功能或满足电路的时序要求。而接口寄存器可以同时被内部电路和外部电路或软件访问,CPU中的寄存器就是其中一种,作为软硬件的接口,为广泛的通用编程用户所熟知。
常见类型
1)数据寄存器- 用来储存整数数字(参考以下的浮点寄存器)。在某些简单/旧的CPU,特别的数据寄存
2)寄存器
3)寄存器
4)器是累加器,作为数学计算之用。
5)地址寄存器- 持有存储器地址,用来访问存储器。在某些简单/旧的CPU里,特别的地址寄存器是索引寄存器(可能出现一个或多个)。
6)通用目的寄存器(GPRs) - 可以保存数据或地址两者,也就是说它们是结合数据/地址 寄存器的功用。
7)浮点寄存器(FPRs) - 用来储存浮点数字。
8)常数寄存器- 用来持有只读的数值(例如0、1、圆周率等等)。
9)向量寄存器- 用来储存由向量处理器运行SIMD(Single Instruction, Multiple Data)指令所得到的数据。
10)特殊目的寄存器- 储存CPU内部的数据,像是程序计数器(或称为指令指针),堆栈寄存器,以及状态寄存器(或称微处理器状态字组)。
11)指令寄存器(instruction register)- 储存现在正在被运行的指令。
12)索引寄存器(index register)- 是在程序运行时用来更改运算对象地址之用。
特点
寄存器又分为内部寄存器与外部寄存器,所谓内部寄存器,其实也是一些小的存储单元,也能存储数据。但同存储器相比,寄存器又有自己独有的特点:
①寄存器位于CPU内部,数量很少,仅十四个
②寄存器所能存储的数据不一定是8bit,有一些寄存器可以存储16bit数据,对于386/486处理器中的一些寄存器则能存储32bit数据
③每个内部寄存器都有一个名字,而没有类似存储器的地址编号。
作用
1.可将寄存器内的数据执行算术及逻辑运算
2.存于寄存器内的地址可用来指向内存的某个位置,即寻址
3.可以用来读写数据到电脑的周边设备。
简单的说:指令解析 - 数据/操作(寄存器)- 回写(cache/memory/disk)
计算机的存储层次(memory hierarchy)之中,寄存器最快,内存其次,最慢的是硬盘。同样都是晶体管存储设备,为什么寄存器比内存快呢?Mike Ash写了一篇很好的解释,非常通俗地回答了这个问题,有助于加深对硬件的理解。
原因一:距离不同
距离不是主要因素,但是最好懂,所以放在最前面说。内存离CPU比较远,所以要耗费更长的时间读取。
以3GHz的CPU为例,电流每秒钟可以振荡30亿次,每次耗时大约为0.33纳秒。光在1纳秒的时间内,可以前进30厘米。也就是说,在CPU的一个时钟周期内,光可以前进10厘米。因此,如果内存距离CPU超过5厘米,就不可能在一个时钟周期内完成数据的读取,这还没有考虑硬件的限制和电流实际上达不到光速。相比之下,寄存器在CPU内部,当然读起来会快一点。距离对于桌面电脑影响很大,对于手机影响就要小得多。手机CPU的时钟频率比较慢(iPhone 5s为1.3GHz),而且手机的内存紧挨着CPU。
原因二:硬件设计不同(1 Byte表示一个字节, 1B=8bit)
最新的iPhone 5s,CPU是A7,寄存器有6000多位(31个64位寄存器,加上32个128位寄存器)。而iPhone 6s的内存是1GB,约为80亿位(bit)。这意味着,高性能、高成本、高耗电的设计可以用在寄存器上,反正只有6000多位,而不能用在内存上。因为每个位的成本和能耗只要增加一点点,就会被放大80亿倍。事实上确实如此,内存的设计相对简单,每个位就是一个电容和一个晶体管,而寄存器的设计则完全不同,多出好几个电子元件。并且通电以后,寄存器的晶体管一直有电,而内存的晶体管只有用到的才有电,没用到的就没电,这样有利于省电。这些设计上的因素,决定了寄存器比内存读取速度更快。
原因三:工作方式不同
寄存器的工作方式很简单,只有两步:(1)找到相关的位,(2)读取这些位。
内存的工作方式就要复杂得多:
(1)找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
(2)将指针送往内存管理单元(MMU),由MMU将虚拟的内存地址翻译成实际的物理地址。
(3)将物理地址送往内存控制器(memory controller),由内存控制器找出该地址在哪一根内存插槽(bank)上。
(4)确定数据在哪一个内存块(chunk)上,从该块读取数据。
(5)数据先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。为了缓解寄存器与内存之间的巨大速度差异,硬件设计师做出了许多努力,包括在CPU内部设置缓存Cache、优化CPU工作方式,尽量一次性从内存读取指令所要用到的全部数据等等。
上面说到”缓存“,大部分程序员都知道什么是软件架构中缓存的概念。这里所说的缓存是指硬件“高速缓冲存储器”,是存在于主存与CPU之间的一级存储器(常见于计算机cpu性能指标中:一级缓存、二级缓存,高配置的服务器会有三级缓存), 由静态存储芯片(SRAM)组成,容量比较小但速度比主存高得多, 接近于CPU的速度。在计算机存储系统的层次结构中,是介于中央处理器和主存储器之间的高速小容量存储器。它和主存储器一起构成一级的存储器。高速缓冲存储器和主存储器之间信息的调度和传送是由硬件自动进行的。高速缓冲存储器最重要的技术指标是它的命中率(一级缓存(a=n*80%) - 二级缓存(b=a*80%) - 三级缓存(c=b*80%))。所谓的命中就是在缓存上读取到指定的数据。
既然是缓存,那么大小肯定是有局限,也就是说不是所有cpu需要的数据都能在缓存中命中,因为它有着自己的更新策略。如下
1. 根据程序局部性规律可知:程序在运行中,总是频繁地使用那些最近被使用过的指令和数据。这就提供了替换策略的理论依据。综合命中率、实现的难易及速度的快慢各种因素,替换策略可有随机法、先进先出法、最近最少使用法等。
(1).随机法(RAND法)
随机法是随机地确定替换的存储块。设置一个随机数产生器,依据所产生的随机数,确定替换块。这种方法简单、易于实现,但命中率比较低。
(2).先进先出法(FIFO法)
先进先出法是选择那个最先调入的那个块进行替换。当最先调入并被多次命中的块,很可能被优先替换,因而不符合局部性规律。这种方法的命中率比随机法好些,但还不满足要求。先进先出方法易于实现,
(3).最近最少使用法(LRU法)
LRU法是依据各块使用的情况, 总是选择那个最近最少使用的块被替换。这种方法比较好地反映了程序局部性规律。 实现LRU策略的方法有多种。
2 在多体并行存储系统中,由于 I/O 设备向主存请求的级别高于 CPU 访存,这就出现了 CPU 等待 I/O 设备访存的现象,致使 CPU 空等一段时间,甚至可能等待几个主存周期,从而降低了 CPU 的工作效率。为了避免 CPU 与 I/O 设备争抢访存,可在 CPU 与主存之间加一级缓存,这样,主存可将 CPU 要取的信息提前送至缓存,一旦主存在与 I/O 设备交换时, CPU 可直接从缓存中读取所需信息,不必空等而影响效率。
3 目前提出的算法可以分为以下三类(第一类是重点要掌握的):
(1)传统替换算法及其直接演化,其代表算法有 :①LRU( Least Recently Used)算法:将最近最少使用的内容替换出Cache ;②LFU( Lease Frequently Used)算法:将访问次数最少的内容替换出Cache;③如果Cache中所有内容都是同一天被缓存的,则将最大的文档替换出Cache,否则按LRU算法进行替换 。④FIFO( First In First Out):遵循先入先出原则,若当前Cache被填满,则替换最早进入Cache的那个。
(2)基于缓存内容关键特征的替换算法,其代表算法有:①Size替换算法:将最大的内容替换出Cache②LRU— MIN替换算法:该算法力图使被替换的文档个数最少。设待缓存文档的大小为S,对Cache中缓存的大小至少是S的文档,根据LRU算法进行替换;如果没有大小至少为S的对象,则从大小至少为S/2的文档中按照LRU算法进行替换;③LRU—Threshold替换算法:和LRU算法一致,只是大小超过一定阈值的文档不能被缓存;④Lowest Lacency First替换算法:将访问延迟最小的文档替换出Cache。
(3)基于代价的替换算法,该类算法使用一个代价函数对Cache中的对象进行评估,最后根据代价值的大小决定替换对象。其代表算法有:①Hybrid算法:算法对Cache中的每一个对象赋予一个效用函数,将效用最小的对象替换出Cache;②Lowest Relative Value算法:将效用值最低的对象替换出Cache;③Least Normalized Cost Replacement(LCNR)算法:该算法使用一个关于文档访问频次、传输时间和大小的推理函数来确定替换文档;④Bolot等人 提出了一种基于文档传输时间代价、大小、和上次访问时间的权重推理函数来确定文档替换;⑤Size—Adjust LRU(SLRU)算法:对缓存的对象按代价与大小的比率进行排序,并选取比率最小的对象进行替换。














 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









