







图像拼接的基本流程

(1) 图像预处理:对原始图像进行直方图匹配、平滑滤波、增强变换等数字图像
处理的基本操作,为图像拼接的下一步作好准备。
(2) 图像配准:图像配准是整个图像拼接流程的核心,配准的精度决定了图像的拼接质量。其基本思想是:首先找到待配准图像与参考图像的模板或特征点的对应位置,然后根据对应关系建立参考图像与待配准图像之间的转换数学模型,将待配准图像转换到参考图像的坐标系中,确定两图像之间的重叠区域。精确配准的关键是寻找一个能很好描述两幅图像转换关系的数据模型。
(3) 图像合成:确定了两幅图像之间的转换关系模型,即重叠区域后,就需要根据重叠区域的信息将待拼接图像镶嵌成一个视觉可行的全景图。由于地形存在微小差别或拍摄条件不同等因素造成图像灰度(或亮度)差异,或者图像配准结果仍存在一定配准误差,为了尽可能地减少遗留变形或图像间的亮度(或灰度)差异对镶嵌结果的影响,就需要选择合适的图像合成策略。
目前,国内外学者提出了很多图像配准的方法,但是各种方法都与一定范围的应用领域有关系,具有各自不同的特点。它们一般由四个要素组成[9]:特征空间、相似性度量、搜索空间和搜索策略。
(1) 特征空间(feature space)
特征空间是从图像中提取的用于配准的信息。特征可以是图像的灰度值,也可以是边界、轮廓等结构特征,或是角点、高曲率点等显著特征,亦或是统计特征、高层结构描述与句法描述等[9-11]。
(2) 相似性度量(similarity metric)
相似性度量是度量配准图像特征之间的相似性。典型的相似性度量有灰度相关、相关系数、互信息等。基于图像特征配准算法,常采用的相似性度量一般建立在各种距离函数上,如欧式距离、街区距离、Hausdorff 距离等。特征空间代表参与配准的数据,相似性度量决定配准度,二者的结合可以忽略许多与配准不相关的畸变,突出图像的本质结构与特征。
(3) 搜索空间(search space)
图像配准问题是一个参数的最优化估计问题,搜索空间就是指所有可能的变换组成的空间,即待估计参数组成的空间。搜索空间的组成和范围由图像变换的类型和强度决定。图像变换分为全局变换和局部变换。全局变换将整幅数字图像作为研究对象,用一个参数矩阵来描述整个图像的变换参数,常见的全局几何变换有仿射变换、投影变换和非线性变换等;局部变换允许变换参数有位置依赖性,即各个单元的变换参数随其所处位置不同而不同。配准算法就是要在搜索空间找出一个使图像之间的相似性度量最佳的位置。
(4) 搜索策略(search strategy)
搜索策略是指在搜索空间中采用合适的方法找出平移、旋转等变换参数的最优估计。这对于减少配准特征和相似性度量的计算量具有重要意义。图像间的变换越复杂,搜索空间就越复杂,对搜索策略的要求就越高,因此选择合适的探索策略至关重要。常见的搜索策略有穷尽搜索、启发式搜索、广义Hough 变换、多尺度搜索、树与图搜索、序贯判决、线性规划、神经网络、遗传算法、模拟退火算法等等。每种方法都有它的优缺点,在很大程度上,搜索策略的选择取决于搜索空间的特性。
设计配准算法时首先确定图像的类型和成像畸变范围,然后根据图像配准的性能指标确定特征空间和搜索空间,最后选择合适的搜索策略找到能使待配准图像之间的相似性度量最大的最佳匹配关系模型。根据上述四个要素的不同选择,产生了各种具体的图像配准技术的不同分类方法。目前提出的用于图像配准的算法可以分为三大类型:基于区域灰度相关的匹配算法、基于特征相关的匹配算法和基于解释相似的算法[12]。图像配准技术经过多年的研究,每类方法中都包含了不同的具体实现途径以适应具体问题。其中,基于解释的图像匹配需要建立在图片自动判读的专家系统之上进行,至今尚未取得突破性的进展。
作者:刘伟民
毕业于:中国科学院计算技术研究所
- 视频中的图像一般重叠面积比较大,因此容易找到对应点。
- 视频中的图像一般很难用到和人交互的东西,所以一般识别对应点应该是自动的过程。
- 视频拼接一般要求速度比较快,最好达到实时拼接的效果。
图像拼接的要求:
- 很多图像要自动识别出图像之间的序列关系,就是那幅图像应该和那副图像挨着。
- 图像不要求速度,但是要求精确,就是准确度比较高。
- 图像拼接可以加入人工成分,就是可以让人自己选定对应的点。
下面我们用SIFT特征进行一个简单的图像拼接过程:
步骤:
l
l
l
l
l
拼接实验:
素材图片:
下面是我拼接的结果:
下面是*****的拼接结果:
结果分析:
我的实验中的图像有的地方很亮,这个对图像进行加权融合就可以解决。
其效果和*****的差不多。
*****的拼接程序经常出现【拼接失败】的情况,我的程序更具有鲁棒性。
缺点:拼接速度没有*****的快。
算法描述
procedure ImageMatching
{
输入FirstImage;
输入SecondImage;
//获得两幅图象的大小
Height1=GetImageHeight(FirstImage);
Height2=GetImageHeight(SecondImage);
Width1=GetImageWidth(FirstImage);
Width2=GetImageWidth(SecondImage);
// 从第二幅图象取网格匹配模板
SecondImageGrid = GetSecondImageGrid(SecondImage);
// 粗略匹配,网格在第一幅图象中先从左向右移动,再从下到上移动,每次移动一个网格间距,Step_Width 或Step_Height,当网格移出重叠区域后结束
y=Heitht1-GridHeight;
MinValue = MaxInteger;
While ( y<Height1-OverlapNumber)//当网格移出重叠部分后结束
{
x=Grid_Width/2; //当网格位于第一幅图象的最左边时,A点的横坐标。
While ( x<(Width1-Grid_Width/2) )
{
FirstImageGrid=GetImgaeGrid(FirstImgaeGrid, x, y);
differ=CaculateDiff(FirstImgaeGrid, SecondImageGrid);//计算象素值差的平
//方和
if (differ<MinValue)
{
BestMatch_x=x;
BestMatch_y=y;
MinValue = differ;
}
x= x+Step_width;
}
y=y-Step_Height;
}
//精确匹配
Step_Width= Step_Width/2;
Step_Height= Step_Height/2;
While ( Step_Height>0 & Step_Width>0)//当水平步长和垂直步长均减为零时结束
{
if(Step_Height==0)//当仅有垂直步长减为零时,将其置为1
Step_Height=1;
If(Step_Width==0) //当仅有水平步长减为零时,将其置为1
Step_Width=1;
temp_x = BestMatch_x;
temp_y = BestMatch_y;
for ( i= -1; i<1; i++)
for( j= -1; j<1; j++)
{
if ((i=0&j!=0)|(i!=0&j=0))
{
FirstImageGrid=GetImgaeGrid(FirstImgaeGrid,
temp_x+i*Step_Width, temp_y +j*Step_Height);
differ=CaculateDiff(FirstImgaeGrid, SecondImageGrid);
if (differ<MinValue)
{
BestMatch_x=x;
BestMatch_y=y;
MinValue = differ;
}
}
}
Step_Height = Step_Height /2;
Step_Width = Step_Width/2;
}
} ——————————————————————————————————————
主要分为以下几个步骤:
(1) 读入两张图片并分别提取SIFT特征
(2) 利用k-d tree和BBF算法进行特征匹配查找
(3) 利用RANSAC算法筛选匹配点并计算变换矩阵
(3) 图像融合
SIFT算法以及RANSAC算法都是利用的RobHess的SIFT源码,前三个步骤RobHess的源码中都有自带的示例。
(1) SIFT特征提取
直接调用RobHess源码(RobHess的SIFT源码分析:综述)中的sift_features()函数进行默认参数的SIFT特征提取,主要代码如下:
- img1_Feat = cvCloneImage(img1);//复制图1,深拷贝,用来画特征点
- img2_Feat = cvCloneImage(img2);//复制图2,深拷贝,用来画特征点
- //默认提取的是LOWE格式的SIFT特征点
- //提取并显示第1幅图片上的特征点
- n1 = sift_features( img1, &feat1 );//检测图1中的SIFT特征点,n1是图1的特征点个数
- export_features("feature1.txt",feat1,n1);//将特征向量数据写入到文件
- draw_features( img1_Feat, feat1, n1 );//画出特征点
- cvNamedWindow(IMG1_FEAT);//创建窗口
- cvShowImage(IMG1_FEAT,img1_Feat);//显示
- //提取并显示第2幅图片上的特征点
- n2 = sift_features( img2, &feat2 );//检测图2中的SIFT特征点,n2是图2的特征点个数
- export_features("feature2.txt",feat2,n2);//将特征向量数据写入到文件
- draw_features( img2_Feat, feat2, n2 );//画出特征点
- cvNamedWindow(IMG2_FEAT);//创建窗口
- cvShowImage(IMG2_FEAT,img2_Feat);//显示


(2) 利用k-d tree和BBF算法进行特征匹配查找,并根据最近邻和次近邻距离比值进行初步筛选
也是调用RobHess源码中的函数,加上之后的一些筛选处理,主要代码如下:
- //根据图1的特征点集feat1建立k-d树,返回k-d树根给kd_root
- kd_root = kdtree_build( feat1, n1 );
- Point pt1,pt2;//连线的两个端点
- double d0,d1;//feat2中每个特征点到最近邻和次近邻的距离
- int matchNum = 0;//经距离比值法筛选后的匹配点对的个数
- //遍历特征点集feat2,针对feat2中每个特征点feat,选取符合距离比值条件的匹配点,放到feat的fwd_match域中
- for(int i = 0; i < n2; i++ )
- {
- feat = feat2+i;//第i个特征点的指针
- //在kd_root中搜索目标点feat的2个最近邻点,存放在nbrs中,返回实际找到的近邻点个数
- int k = kdtree_bbf_knn( kd_root, feat, 2, &nbrs, KDTREE_BBF_MAX_NN_CHKS );
- if( k == 2 )
- {
- d0 = descr_dist_sq( feat, nbrs[0] );//feat与最近邻点的距离的平方
- d1 = descr_dist_sq( feat, nbrs[1] );//feat与次近邻点的距离的平方
- //若d0和d1的比值小于阈值NN_SQ_DIST_RATIO_THR,则接受此匹配,否则剔除
- if( d0 < d1 * NN_SQ_DIST_RATIO_THR )
- { //将目标点feat和最近邻点作为匹配点对
- pt2 = Point( cvRound( feat->x ), cvRound( feat->y ) );//图2中点的坐标
- pt1 = Point( cvRound( nbrs[0]->x ), cvRound( nbrs[0]->y ) );//图1中点的坐标(feat的最近邻点)
- pt2.x += img1->width;//由于两幅图是左右排列的,pt2的横坐标加上图1的宽度,作为连线的终点
- cvLine( stacked, pt1, pt2, CV_RGB(255,0,255), 1, 8, 0 );//画出连线
- matchNum++;//统计匹配点对的个数
- feat2[i].fwd_match = nbrs[0];//使点feat的fwd_match域指向其对应的匹配点
- }
- }
- free( nbrs );//释放近邻数组
- }
- //显示并保存经距离比值法筛选后的匹配图
- cvNamedWindow(IMG_MATCH1);//创建窗口
- cvShowImage(IMG_MATCH1,stacked);//显示

(3) 利用RANSAC算法筛选匹配点并计算变换矩阵
此部分最主要的是RobHess源码中的ransac_xform()函数,此函数实现了用RANSAC算法筛选匹配点,返回结果是计算好的变换矩阵。
此部分中,我利用匹配点的坐标关系,对输入的两幅图像的左右关系进行了判断,并根据结果选择使用矩阵H或H的逆阵进行变换。
所以读入的两幅要拼接的图像的左右位置关系可以随意,程序中可自动调整。
主要代码如下:
- //利用RANSAC算法筛选匹配点,计算变换矩阵H,
- //无论img1和img2的左右顺序,计算出的H永远是将feat2中的特征点变换为其匹配点,即将img2中的点变换为img1中的对应点
- H = ransac_xform(feat2,n2,FEATURE_FWD_MATCH,lsq_homog,4,0.01,homog_xfer_err,3.0,&inliers,&n_inliers);
- //若能成功计算出变换矩阵,即两幅图中有共同区域
- if( H )
- {
- qDebug()<<tr("经RANSAC算法筛选后的匹配点对个数:")<<n_inliers<<endl; //输出筛选后的匹配点对个数
- int invertNum = 0;//统计pt2.x > pt1.x的匹配点对的个数,来判断img1中是否右图
- //遍历经RANSAC算法筛选后的特征点集合inliers,找到每个特征点的匹配点,画出连线
- for(int i=0; i<n_inliers; i++)
- {
- feat = inliers[i];//第i个特征点
- pt2 = Point(cvRound(feat->x), cvRound(feat->y));//图2中点的坐标
- pt1 = Point(cvRound(feat->fwd_match->x), cvRound(feat->fwd_match->y));//图1中点的坐标(feat的匹配点)
- //qDebug()<<"pt2:("<<pt2.x<<","<<pt2.y<<")--->pt1:("<<pt1.x<<","<<pt1.y<<")";//输出对应点对
- //统计匹配点的左右位置关系,来判断图1和图2的左右位置关系
- if(pt2.x > pt1.x)
- invertNum++;
- pt2.x += img1->width;//由于两幅图是左右排列的,pt2的横坐标加上图1的宽度,作为连线的终点
- cvLine(stacked_ransac,pt1,pt2,CV_RGB(255,0,255),1,8,0);//在匹配图上画出连线
- }
- cvNamedWindow(IMG_MATCH2);//创建窗口
- cvShowImage(IMG_MATCH2,stacked_ransac);//显示经RANSAC算法筛选后的匹配图
- /*程序中计算出的变换矩阵H用来将img2中的点变换为img1中的点,正常情况下img1应该是左图,img2应该是右图。
- 此时img2中的点pt2和img1中的对应点pt1的x坐标的关系基本都是:pt2.x < pt1.x
- 若用户打开的img1是右图,img2是左图,则img2中的点pt2和img1中的对应点pt1的x坐标的关系基本都是:pt2.x > pt1.x
- 所以通过统计对应点变换前后x坐标大小关系,可以知道img1是不是右图。
- 如果img1是右图,将img1中的匹配点经H的逆阵H_IVT变换后可得到img2中的匹配点*/
- //若pt2.x > pt1.x的点的个数大于内点个数的80%,则认定img1中是右图
- if(invertNum > n_inliers * 0.8)
- {
- CvMat * H_IVT = cvCreateMat(3, 3, CV_64FC1);//变换矩阵的逆矩阵
- //求H的逆阵H_IVT时,若成功求出,返回非零值
- if( cvInvert(H,H_IVT) )
- {
- cvReleaseMat(&H);//释放变换矩阵H,因为用不到了
- H = cvCloneMat(H_IVT);//将H的逆阵H_IVT中的数据拷贝到H中
- cvReleaseMat(&H_IVT);//释放逆阵H_IVT
- //将img1和img2对调
- IplImage * temp = img2;
- img2 = img1;
- img1 = temp;
- ui->mosaicButton->setEnabled(true);//激活全景拼接按钮
- }
- else//H不可逆时,返回0
- {
- cvReleaseMat(&H_IVT);//释放逆阵H_IVT
- QMessageBox::warning(this,tr("警告"),tr("变换矩阵H不可逆"));
- }
- }
- else
- ui->mosaicButton->setEnabled(true);//激活全景拼接按钮
- }
- else //无法计算出变换矩阵,即两幅图中没有重合区域
- {
- QMessageBox::warning(this,tr("警告"),tr("两图中无公共区域"));
- }

(3) 图像融合
这里有两种拼接方法:
① 简易拼接方法的过程是:首先将右图img2经变换矩阵H变换到一个新图像中,然后直接将左图img1加到新图像中,这样拼接出来会有明显的拼接缝,但也是一个初步的成品了。
② 另一种方法首先也是将右图img2经变换矩阵H变换到一个新图像中,然后图像的融合过程将目标图像分为三部分,最左边完全取自img1中的数据,中间的重合部分是两幅图像的加权平均,重合区域右边的部分完全取自img2经变换后的图像。加权平均的权重选择也有好多方法,比如可以使用最基本的取两张图像的平均值,但这样会有明显的拼接缝。这里首先计算出拼接区域的宽度,设d1,d2分别是重叠区域中的点到重叠区域左边界和右边界的距离,则使用如下公式计算重叠区域的像素值:
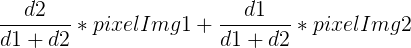
主要代码如下:
- //若能成功计算出变换矩阵,即两幅图中有共同区域,才可以进行全景拼接
- if(H)
- {
- //拼接图像,img1是左图,img2是右图
- CalcFourCorner();//计算图2的四个角经变换后的坐标
- //为拼接结果图xformed分配空间,高度为图1图2高度的较小者,根据图2右上角和右下角变换后的点的位置决定拼接图的宽度
- xformed = cvCreateImage(cvSize(MIN(rightTop.x,rightBottom.x),MIN(img1->height,img2->height)),IPL_DEPTH_8U,3);
- //用变换矩阵H对右图img2做投影变换(变换后会有坐标右移),结果放到xformed中
- cvWarpPerspective(img2,xformed,H,CV_INTER_LINEAR + CV_WARP_FILL_OUTLIERS,cvScalarAll(0));
- cvNamedWindow(IMG_MOSAIC_TEMP); //显示临时图,即只将图2变换后的图
- cvShowImage(IMG_MOSAIC_TEMP,xformed);
- //简易拼接法:直接将将左图img1叠加到xformed的左边
- xformed_simple = cvCloneImage(xformed);//简易拼接图,克隆自xformed
- cvSetImageROI(xformed_simple,cvRect(0,0,img1->width,img1->height));
- cvAddWeighted(img1,1,xformed_simple,0,0,xformed_simple);
- cvResetImageROI(xformed_simple);
- cvNamedWindow(IMG_MOSAIC_SIMPLE);//创建窗口
- cvShowImage(IMG_MOSAIC_SIMPLE,xformed_simple);//显示简易拼接图
- //处理后的拼接图,克隆自xformed
- xformed_proc = cvCloneImage(xformed);
- //重叠区域左边的部分完全取自图1
- cvSetImageROI(img1,cvRect(0,0,MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvSetImageROI(xformed,cvRect(0,0,MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvSetImageROI(xformed_proc,cvRect(0,0,MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvAddWeighted(img1,1,xformed,0,0,xformed_proc);
- cvResetImageROI(img1);
- cvResetImageROI(xformed);
- cvResetImageROI(xformed_proc);
- cvNamedWindow(IMG_MOSAIC_BEFORE_FUSION);
- cvShowImage(IMG_MOSAIC_BEFORE_FUSION,xformed_proc);//显示融合之前的拼接图
- //采用加权平均的方法融合重叠区域
- int start = MIN(leftTop.x,leftBottom.x) ;//开始位置,即重叠区域的左边界
- double processWidth = img1->width - start;//重叠区域的宽度
- double alpha = 1;//img1中像素的权重
- for(int i=0; i<xformed_proc->height; i++)//遍历行
- {
- const uchar * pixel_img1 = ((uchar *)(img1->imageData + img1->widthStep * i));//img1中第i行数据的指针
- const uchar * pixel_xformed = ((uchar *)(xformed->imageData + xformed->widthStep * i));//xformed中第i行数据的指针
- uchar * pixel_xformed_proc = ((uchar *)(xformed_proc->imageData + xformed_proc->widthStep * i));//xformed_proc中第i行数据的指针
- for(int j=start; j<img1->width; j++)//遍历重叠区域的列
- {
- //如果遇到图像xformed中无像素的黑点,则完全拷贝图1中的数据
- if(pixel_xformed[j*3] < 50 && pixel_xformed[j*3+1] < 50 && pixel_xformed[j*3+2] < 50 )
- {
- alpha = 1;
- }
- else
- { //img1中像素的权重,与当前处理点距重叠区域左边界的距离成正比
- alpha = (processWidth-(j-start)) / processWidth ;
- }
- pixel_xformed_proc[j*3] = pixel_img1[j*3] * alpha + pixel_xformed[j*3] * (1-alpha);//B通道
- pixel_xformed_proc[j*3+1] = pixel_img1[j*3+1] * alpha + pixel_xformed[j*3+1] * (1-alpha);//G通道
- pixel_xformed_proc[j*3+2] = pixel_img1[j*3+2] * alpha + pixel_xformed[j*3+2] * (1-alpha);//R通道
- }
- }
- cvNamedWindow(IMG_MOSAIC_PROC);//创建窗口
- cvShowImage(IMG_MOSAIC_PROC,xformed_proc);//显示处理后的拼接图
- /*重叠区域取两幅图像的平均值,效果不好
- //设置ROI,是包含重叠区域的矩形
- cvSetImageROI(xformed_proc,cvRect(MIN(leftTop.x,leftBottom.x),0,img1->width-MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvSetImageROI(img1,cvRect(MIN(leftTop.x,leftBottom.x),0,img1->width-MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvSetImageROI(xformed,cvRect(MIN(leftTop.x,leftBottom.x),0,img1->width-MIN(leftTop.x,leftBottom.x),xformed_proc->height));
- cvAddWeighted(img1,0.5,xformed,0.5,0,xformed_proc);
- cvResetImageROI(xformed_proc);
- cvResetImageROI(img1);
- cvResetImageROI(xformed); //*/
- /*对拼接缝周围区域进行滤波来消除拼接缝,效果不好
- //在处理前后的图上分别设置横跨拼接缝的矩形ROI
- cvSetImageROI(xformed_proc,cvRect(img1->width-10,0,img1->width+10,xformed->height));
- cvSetImageROI(xformed,cvRect(img1->width-10,0,img1->width+10,xformed->height));
- cvSmooth(xformed,xformed_proc,CV_MEDIAN,5);//对拼接缝周围区域进行中值滤波
- cvResetImageROI(xformed);
- cvResetImageROI(xformed_proc);
- cvShowImage(IMG_MOSAIC_PROC,xformed_proc);//显示处理后的拼接图 */
- /*想通过锐化解决变换后的图像失真的问题,对于扭曲过大的图像,效果不好
- double a[]={ 0, -1, 0, -1, 5, -1, 0, -1, 0 };//拉普拉斯滤波核的数据
- CvMat kernel = cvMat(3,3,CV_64FC1,a);//拉普拉斯滤波核
- cvFilter2D(xformed_proc,xformed_proc,&kernel);//滤波
- cvShowImage(IMG_MOSAIC_PROC,xformed_proc);//显示处理后的拼接图*/
- }
右图经变换后的结果如下图:

简易拼接结果如下图:

使用第二种方法时,重合区域融合之前如下图:

加权平均融合之后如下图:

用Qt做了个简单的界面,如下:

还有很多不足,经常有黑边无法去除,望大家多多指正。
实验环境:
IDE是 Qt Creator 2.4.1,Qt版本是4.8.4,OpenCV版本是2.4.4,SIFT源码来自RobHess给出的源码
源码下载:基于SIFT特征的全景图像拼接,Qt工程:http://download.csdn.net/detail/masikkk/5702681
——————————————————————————————————————遥感图像拼接与裁剪
一、试验目的:通过ENVI和ARCGIS软件对下载的大足地区的TM图像进行拼接和裁剪,将自己的家乡所在的区域裁剪出来。通过本次试验,初步熟悉ENVI和ARCGIS软件,为今后环境遥感学习奠定基础。
二、试验原理:
三、数据来源:已经数字化好的1:400万部全国各县界的shp格式的矢量数据。从遥感数据共享中心(http://ids.ceode.ac.cn/)下载下来的LANDSAT5 TM数据。波段数为7,各波段信息如表1所示:
| 波段 | 波长范围(μm) | 分辨率 |
| 1 | 0.45~0.53 | 30米 |
| 2 | 0.52~0.60 | 30米 |
| 3 | 0.63~0.69 | 30米 |
| 4 | 0.76~0.90 | 30米 |
| 5 | 1.55~1.75 | 30米 |
| 6 | 10.40~12.50 | 120>米 |
| 7 | 2.08~2.35 | 30米 |
表1
四、实验步骤:
1、数据的下载:
图1
图2
图3
2、图像的拼接
图4
图5
图6
图8
图9
3、投影转换
图10
图11
图12
图13
图14
图15
图16
4、图像的裁剪
(1)矢量文件掩膜裁剪
图17
图18
裁剪好的大足图像如图19所示:
图19
(2)规则裁剪
图20
图21
图22
图23
(3)感兴趣区掩膜裁剪
图24
图25
图26
图27
五、实验结果与分析:
六、实验心得:
图像拼接技术主要包括两个关键环节即图像配准和图像融合对于图像融合部分,由于其耗时不太大,且现有的几种主要方法效果差别也不多,所以总体来说算法上比较成熟。而图像配准部分是整个图像拼接技术的核心部分,它直接关系到图像拼接算法的成功率和运行速度,因此配准算法的研究是多年来研究的重点。
目前的图像配准算法基本上可以分为两类:基于频域的方法(相位相关方法)和基于时域的方法。
相位相关法最早是由Kuglin和Hines在1975年提出的,并且证明在纯二维平移的情形下,拼接精度可以达到1个像素,多用于航空照片和卫星遥感图像的配准等领域。该方法对拼接的图像进行快速傅立叶变换,将两幅待配准图像变换到频域,然后通过它们的互功率谱直接计算出两幅图像间的平移矢量,从而实现图像的配准。由于其具有简单而精确的特点,后来成为最有前途的图像配准算法之一。但是相位相关方法一般需要比较大的重叠比例(通常要求配准图像之间有50%的重叠比例),如果重叠比例较小,则容易造成平移矢量的错误估计,从而较难实现图像的配准。
基于时域的方法又可具体分为基于特征的方法和基于区域的方法。基于特征的方法首先找出两幅图像中的特征点(如边界点、拐点),并确定图像间特征点的对应关系,然后利用这种对应关系找到两幅图像间的变换关系。这一类方法不直接利用图像的灰度信息,因而对光线变化不敏感,但对特征点对应关系的精确程度依赖很大。这一类方法采用的思想较为直观,目前大部分的图像配准算法都可以归为这一类。基于区域的方法是以一幅图像重叠区域中的一块作为模板,在另一幅图像中搜索与此模板最相似的匹配块,这种算法精度较高,但计算量过大。
按照匹配算法的具体实现又可以分为直接法和搜索法两大类,直接法主要包括变换优化法,它首先建立两幅待拼接图像间的变换模型,然后采用非线性迭代最小化算法直接计算出模型的变换参数,从而确定图像的配准位置。该算法效果较好,收敛速度较快,但是它要达到过程的收敛要求有较好的初始估计,如果初始估计不好,则会造成图像拼接的失败。搜索法主要是以一幅图像中的某些特征为依据,在另一幅图像中搜索最佳配准位置,常用的有比值匹配法,块匹配法和网格匹配法。比值匹配法是从一幅图像的重叠区域中部分相邻的两列上取出部分像素,然后以它们的比值作模板,在另一幅图像中搜索最佳匹配。这种算法计算量较小,但精度较低;块匹配法则是以一幅图像重叠区域中的一块作为模板,在另一幅图像中搜索与此模板最相似的匹配块,这种算法精度较高,但计算量过大;网格匹配法减小了块匹配法的计算量,它首先要进行粗匹配,每次水平或垂直移动一个步长,记录最佳匹配位置,然后在此位置附近进行精确匹配,每次步长减半,然后循环此过程直至步长减为0。这种算法较前两种运算量都有所减小,但在实际应用中仍然偏大,而且粗匹配时如果步长取的太大,很可能会造成较大的粗匹配误差,从而很难实现精确匹配。
——————————————————————————————————————网上搜的都是一行代码Stitcher::Status status = stitcher.stitch(imgs, pano);就出来的傻瓜拼接,连opencv基本的包都没用。
自己好歹用了下基本的包实现了下。
鲁棒性不太好,图片少的时候没事,图片一多就出现了内存错误和木有特征点的错误。
#include <iostream>
#include <fstream>
#include <io.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/stitching/stitcher.hpp"
#include "opencv2/stitching/warpers.hpp"
#define MaxPics 30
//F:\Program Files\opencv\modules\stitching\include\opencv2\stitching
using namespace std;
using namespace cv;
bool try_use_gpu = false;
int filenum;
vector<Mat> imgs;
string result_name = "result.jpg";
//void printUsage();
//int parseCmdArgs(int argc, char** argv);
int readDir(char *path,char fnames[MaxPics][100]);
int readDir(char *path,char fnames[MaxPics][100])
{
struct _finddata_t c_file;
intptr_t hFile;
filenum=0;
char fullpath[100];
sprintf(fullpath,"%s\\*.jpg",path);
// Find first .c file in current directory
if( (hFile = _findfirst( fullpath, &c_file )) == -1L )
printf( "No *.jpg files in current directory %s!\n",fullpath);
else
{
printf( "Listing of .jpg files in %s directory\n\n",path);
printf( "RDO HID SYS ARC FILE SIZE\n", ' ' );
printf( "--- --- --- --- ---- ----\n", ' ' );
do {
printf( ( c_file.attrib & _A_RDONLY ) ? " Y " : " N " );
printf( ( c_file.attrib & _A_SYSTEM ) ? " Y " : " N " );
printf( ( c_file.attrib & _A_HIDDEN ) ? " Y " : " N " );
printf( ( c_file.attrib & _A_ARCH ) ? " Y " : " N " );
//ctime_s( buffer, _countof(buffer), &c_file.time_write );
printf( " %-15s %9ld\n",c_file.name, c_file.size );
sprintf(fnames[filenum],"%s\\%s",path,c_file.name);
filenum++;
} while( _findnext( hFile, &c_file ) == 0 );
_findclose( hFile );
}
return filenum;
}
int main(int argc, char* argv[])
{
clock_t start,finish;
double totaltime;
start=clock();
argv[1]="pic";
char fdir[MaxPics][100];
filenum = readDir(argv[1],fdir);
Mat img, pano;
for(int i=0 ; i<filenum ;i++){
img = imread(fdir[i]);
imgs.push_back(img);
}
Stitcher stitcher = Stitcher::createDefault(try_use_gpu);
stitcher.setRegistrationResol(0.1);//为了加速,我选0.1,默认是0.6,最大值1最慢,此方法用于特征点检测阶段,如果找不到特征点,调高吧
//stitcher.setSeamEstimationResol(0.1);//默认是0.1
//stitcher.setCompositingResol(-1);//默认是-1,用于特征点检测阶段,找不到特征点的话,改-1
stitcher.setPanoConfidenceThresh(1);//默认是1,见过有设0.6和0.4的
stitcher.setWaveCorrection(false);//默认是true,为加速选false,表示跳过WaveCorrection步骤
//stitcher.setWaveCorrectKind(detail::WAVE_CORRECT_HORIZ);//还可以选detail::WAVE_CORRECT_VERT ,波段修正(wave correction)功能(水平方向/垂直方向修正)。因为setWaveCorrection设的false,此语句没用
//找特征点surf算法,此算法计算量大,但对刚体运动、缩放、环境影响等情况下较为稳定
detail::SurfFeaturesFinder *featureFinder = new detail::SurfFeaturesFinder();
stitcher.setFeaturesFinder(featureFinder);
//找特征点ORB算法,但是发现草地这组图,这个算法不能完成拼接
//detail::OrbFeaturesFinder *featureFinder = new detail::OrbFeaturesFinder();
//stitcher.setFeaturesFinder(featureFinder);
//Features matcher which finds two best matches for each feature and leaves the best one only if the ratio between descriptor distances is greater than the threshold match_conf.
detail::BestOf2NearestMatcher *matcher = new detail::BestOf2NearestMatcher(false, 0.5f/*=match_conf默认是0.65,我选0.8,选太大了就没特征点啦,0.8都失败了*/);
stitcher.setFeaturesMatcher(matcher);
// Rotation Estimation,It takes features of all images, pairwise matches between all images and estimates rotations of all cameras.
//Implementation of the camera parameters refinement algorithm which minimizes sum of the distances between the rays passing through the camera center and a feature,这个耗时短
stitcher.setBundleAdjuster(new detail::BundleAdjusterRay());
//Implementation of the camera parameters refinement algorithm which minimizes sum of the reprojection error squares.
//stitcher.setBundleAdjuster(new detail::BundleAdjusterReproj());
//Seam Estimation
//Minimum graph cut-based seam estimator
//stitcher.setSeamFinder(new detail::GraphCutSeamFinder(detail::GraphCutSeamFinderBase::COST_COLOR));//默认就是这个
//stitcher.setSeamFinder(new detail::GraphCutSeamFinder(detail::GraphCutSeamFinderBase::COST_COLOR_GRAD));//GraphCutSeamFinder的第二种形式
//啥SeamFinder也不用,Stub seam estimator which does nothing.
stitcher.setSeamFinder(new detail::NoSeamFinder);
//Voronoi diagram-based seam estimator.
//stitcher.setSeamFinder(new detail::VoronoiSeamFinder);
//exposure compensators曝光补偿
//stitcher.setExposureCompensator(new detail::BlocksGainCompensator());//默认的就是这个
//不要曝光补偿
stitcher.setExposureCompensator(new detail::NoExposureCompensator());
//Exposure compensator which tries to remove exposure related artifacts by adjusting image intensities
//stitcher.setExposureCompensator(new detail::detail::GainCompensator());
//Exposure compensator which tries to remove exposure related artifacts by adjusting image block intensities
//stitcher.setExposureCompensator(new detail::detail::BlocksGainCompensator());
//Image Blenders
//Blender which uses multi-band blending algorithm
//stitcher.setBlender(new detail::MultiBandBlender(try_use_gpu));//默认的是这个
//Simple blender which mixes images at its borders
stitcher.setBlender(new detail::FeatherBlender());//这个简单,耗时少
//柱面?球面OR平面?默认为球面
PlaneWarper* cw = new PlaneWarper();
//SphericalWarper* cw = new SphericalWarper();
//CylindricalWarper* cw = new CylindricalWarper();
stitcher.setWarper(cw);
Stitcher::Status status = stitcher.estimateTransform(imgs);
if (status != Stitcher::OK)
{
cout << "Can't stitch images, error code = " << int(status) << endl;
return -1;
}
status = stitcher.composePanorama(pano);
if (status != Stitcher::OK)
{
cout << "Can't stitch images, error code = " << int(status) << endl;
return -1;
}
cout<<"程序开始";
imwrite(result_name, pano);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
cout<<"\n此程序的运行时间为"<<totaltime<<"秒!"<<endl;
return 0;
}
至于其他的拼接方式,http://academy.nearsoft.com/project-updates/makingapanoramapicture写的挺好。我引用之,并总结如下
1,Stitcher class from OpenCV library
- Pros
- Extremely simple. Build panorama in just one command.
- It performs from finding features through blending in the selected projection by itself.
- Cons
- Uses SURF algorithm (patented, not allowed for commercial use).
- Slow at searching for features, running on a smartphone
2,BoofCV
- Pros
- Still easy to use.
- Java native.
- Cons
- It blends without warping into the spherical projection.
- Still uses SURF.
当然自己实现最好,我的上述代码就是第一种了
——————————————————————————————————————1.1 图像拼接技术的研究背景及研究意义
图像拼接(image mosaic)是一个日益流行的研究领域,他已经成为照相绘图学、计算机视觉、图像处理和计算机图形学研究中的热点。图像拼接解决的问题一般式,通过对齐一系列空间重叠的图像,构成一个无缝的、高清晰的图像,它具有比单个图像更高的分辨率和更大的视野。
早期的图像拼接研究一直用于照相绘图学,主要是对大量航拍或卫星的图像的整合。近年来随着图像拼接技术的研究和发展,它使基于图像的绘制(IBR)成为结合两个互补领域——计算机视觉和计算机图形学的坚决焦点,在计算机视觉领域中,图像拼接成为对可视化场景描述(Visual Scene Representaions)的主要研究方法:在计算机形学中,现实世界的图像过去一直用于环境贴图,即合成静态的背景和增加合成物体真实感的贴图,图像拼接可以使IBR从一系列真是图像中快速绘制具有真实感的新视图。
在军事领域网的夜视成像技术中,无论夜视微光还是红外成像设备都会由于摄像器材的限制而无法拍摄视野宽阔的图片,更不用说360 度的环形图片了。但是在实际应用中,很多时候需要将360 度所拍摄的很多张图片合成一张图片,从而可以使观察者可以观察到周围的全部情况。使用图像拼接技术,在根据拍摄设备和周围景物的情况进行分析后,就可以将通过转动的拍摄器材拍摄的涵盖周围360 度景物的多幅图像进行拼接,从而实时地得到超大视角甚至是360 度角的全景图像。这在红外预警中起到了很大的作用。
微小型履带式移动机器人项目中,单目视觉不能满足机器人的视觉导航需要,并且单目视觉机器人的视野范围明显小于双目视觉机器人的视野。利用图像拼接技术,拼接机器人双目采集的图像,可以增大机器人的视野,给机器人的视觉导航提供方便。在虚拟现实领域中,人们可以利用图像拼接技术来得到宽视角的图像或360 度全景图像,用来虚拟实际场景。这种基于全景图的虚拟现实系统,通过全景图的深度信息抽取,恢复场景的三维信息,进而建立三维模型。这个系统允许用户在虚拟环境中的一点作水平环视以及一定范围内的俯视和仰视,同时允许在环视的过程中动态地改变焦距。这样的全景图像相当于人站在原地环顾四周时看到的情形。在医学图像处理方面,显微镜或超声波的视野较小,医师无法通过一幅图像进行诊视,同时对于大目标图像的数据测量也需要把不完整的图像拼接为一个整体。所以把相邻的各幅图像拼接起来是实现远程数据测量和远程会诊的关键环节圆。在遥感技术领域中,利用图像拼接技术中的图像配准技术可以对来自同一区域的两幅或多幅图像进行比较,也可以利用图像拼接技术将遥感卫星拍摄到的有失真地面图像拼接成比较准确的完整图像,作为进一步研究的依据。
从以上方面可以看出,图像拼接技术的应用前景十分广阔,深入研究图像拼接技术有着很重要的意义
1.2图像拼接算法的分类
图像拼接作为这些年来图像研究方面的重点之一,国内外研究人员也提出了很多拼接算法。图像拼接的质量,主要依赖图像的配准程度,因此图像的配准是拼接算法的核心和关键。根据图像匹配方法的不同仁阔,一般可以将图像拼接算法分为以下两个类型:
(1) 基于区域相关的拼接算法。
当以两块区域像素点灰度值的差别作为判别标准时,最简单的一种方法是直接把各点灰度的差值累计起来。这种办法效果不是很好,常常由于亮度、对比度的变化及其它原因导致拼接失败。另一种方法是计算两块区域的对应像素点灰度值的相关系数,相关系数越大,则两块图像的匹配程度越高。该方法的拼接效果要好一些,成功率有所提高。
基于特征的配准方法有两个过程:特征抽取和特征配准。首先从两幅图像中提取灰度变化明显的点、线、区域等特征形成特征集冈。然后在两幅图像对应的特征集中利用特征匹配算法尽可能地将存在对应关系的特征对选择出来。一系列的图像分割技术都被用到特征的抽取和边界检测上。如canny 算子、拉普拉斯高斯算子、区域生长。抽取出来的空间特征有闭合的边界、开边界、交叉线以及其他特征。特征匹配的算法有:交叉相关、距离变换、动态编程、结构匹配、链码相关等算法。
1.3本文的主要工作和组织结构
本文的主要工作:
(1) 总结了前人在图像拼接方面的技术发展历程和研究成果。
(2) 学习和研究了前人的图像配准算法。
(3) 学习和研究了常用的图像融合算法。
(4) 用matlab实现本文中的图像拼接算法
(5) 总结了图像拼接中还存在的问题,对图像拼接的发展方向和应用前景进行展望。
本文的组织结构:
第一章主要对图像拼接技术作了整体的概述,介绍了图像拼接的研究背景和应用前景,以及图像拼接技术的大致过程、图像拼接算法的分类和其技术难点。第二章主要介绍讨论了图像预处理中的两个步骤,即图像的几何校正和噪声点的抑制。第三章主要介绍讨论了图像配准的多种算法。第四章主要介绍讨论了图像融合的一些算法。第五章主要介绍图像拼接软件实现本文的算法。第六章主要对图像拼接中还存在的问题进行总结,以及对图像拼接的发展进行展望。
1.4 本章小结
本章主要对图像拼接技术作了整体的概述,介绍了图像拼接的研究背景和应用前景,以图像拼接算法的分类和其技术难点,并且对全文研究内容进行了总体介绍。
第二章
2.1图像拼接
如图。

2.2 图像的获取方式
图像拼接技术原理是根据图像重叠部分将多张衔接的图像拼合成一张高分辨率全景图 。这些有重叠部分的图像一般由两种方法获得 : 一种是固定照相机的转轴 ,然后绕轴旋转所拍摄的照片 ;另一种是固定照相机的光心 ,水平摇动镜头所拍摄的照片。其中 ,前者主要用于远景或遥感图像的获取 ,后者主要用于显微图像的获取 ,它们共同的特点就是获得有重叠的二维图像。
2.3 图像的预处理
2.3.1 图像的校正
当照相系统的镜头或者照相装置没有正对着待拍摄的景物时候,那么拍摄到的景物图像就会产生一定的变形。这是几何畸变最常见的情况。另外,由于光学成像系统或电子扫描系统的限制而产生的枕形或桶形失真,也是几何畸变的典型情况。几何畸变会给图像拼接造成很大的问题,原本在两幅图像中相同的物体会因为畸变而变得不匹配,这会给图像的配准带来很大的问题。因此,解决几何畸变的问题显得很重要。
图象校正的基本思路是,根据图像失真原因,建立相应的数学模型,从被污染或畸变的图象信号中提取所需要的信息,沿着使图象失真的逆过程恢复图象本来面貌。实际的复原过程是设计一个滤波器,使其能从失真图象中计算得到真实图象的估值,使其根据预先规定的误差准则,最大程度地接近真实图象。
2.3.2 图像噪声的抑制
图像噪声可以理解为妨碍人的视觉感知,或妨碍系统传感器对所接受图像源信息进行理解或分析的各种因素,也可以理解成真实信号与理想信号之间存在的偏差。一般来说,噪声是不可预测的随机信号,通常采用概率统计的方法对其进行分析。噪声对图像处理十分重要,它影响图像处理的各个环节,特别在图像的输入、采集中的噪声抑制是十分关键的问题。若输入伴有较大的噪声,必然影响图像拼接的全过程及输出的结果。根据噪声的来源,大致可以分为外部噪声和内部噪声;从统计数学的观点来定义噪声,可以分为平稳噪声和非平稳噪声。各种类型的噪声反映在图像画面上,大致可以分为两种类型。一是噪声的幅值基本相同,但是噪声出现的位置是随机的,一般称这类噪声为椒盐噪声。另一种是每一点都存在噪声,但噪声的幅值是随机分布的,从噪声幅值大小的分布统计来看,其密度函数有高斯型、瑞利型,分别成为高斯噪声和瑞利噪声,又如频谱均匀分布的噪声称为白噪声等。
1.均值滤波
![]()
![]()
其中,s为模板,M为该模板中包含像素的总个数。

图2.2.2.1模板示意图
2.中值滤波
中值滤波是基于排序统计理论的一种能有效抑制噪声的非线性信号处理技术。它的核心算法是将模板中的数据进行排序,这样,如果一个亮点(暗点)的噪声,就会在排序过程中被排在数据序列的最右侧或者最左侧,因此,最终选择的数据序列中见位置上的值一般不是噪声点值,由此便可以达到抑制噪声的目的。
取某种结构的二维滑动模板,将模板内像素按照像素值的大小进行排序,生成单调上升(或下降)的二维数据序列。二维德中值滤波输出为
其中,f(x,y),g (x,y)分别为原图像和处理后的图像,w二维模板,k ,l为模板的长宽,Med 为取中间值操作,模板通常为3
2.4 本章小结
本章主要介绍了图像几何畸变校正和图像噪声抑制两种图像预处理.
第三章
3.1 图像配准的概念
给定同一景物的从不同的视角或在不同的时间获取的两个图像I ,I 和两个图像间的相似度量S(I ,I ),找出I ,I 中的同名点,确定图像间的最优变换T,使得S(T(I ),I )达到最大值。
3.2 基于区域的配准
3.2.1 逐一比较法
设搜索图为s待配准模板为T,如图3.1所示,S大小为M N,T大小为U V,如图所示。

![]() (N-V+1)个,配准的目标就是在(M-U+1)
(N-V+1)个,配准的目标就是在(M-U+1) ![]() (N-V+1)个分块图像中找一个与待配准图像最相似的图像,这样得到的基准点就是最佳配准点。
(N-V+1)个分块图像中找一个与待配准图像最相似的图像,这样得到的基准点就是最佳配准点。
![]() 的内容。若两者一致,则T和S
的内容。若两者一致,则T和S![]() 之差为零。在现实图像中,两幅图像完全一致是很少见的,一般的判断是在满足一定条件下,T和S
之差为零。在现实图像中,两幅图像完全一致是很少见的,一般的判断是在满足一定条件下,T和S![]() 之差最小。
之差最小。
根据以上原理,可采用下列两种测度之一来衡量T和S 的相似程度。D(i,j)的值越小,则该窗口越匹配。
![]()
![]()
![]() (m,n)-T(m,n)]
(m,n)-T(m,n)]![]()
或
![]()
![]()
![]() [S
[S![]() (m,n)-T(m,n)
(m,n)-T(m,n)![]()
或者利用归一化相关函数。将式(3-1)展开可得:
D(i,j)=![]()
![]()
![]()
![]() S (m,n)*T(m,n)+
S (m,n)*T(m,n)+![]()
![]()
关函数为:
R(i,j)=
当R(i,j)越大时,D(i,j)越小,归一化后为:

根据Cauchy-Schwarz不等式可知式(3-5)中0![]() R(i,j)
R(i,j)![]() 1,并且仅当值S (m, n)/T (m, n)=常数时,R(i,j)取极大值。
1,并且仅当值S (m, n)/T (m, n)=常数时,R(i,j)取极大值。
3.2.2 分层比较法
图像处理的塔形(或称金字塔:Pyramid)分解方法是由Burt和Adelson首先提出的,其早期主要用于图像的压缩处理及机器人的视觉特性研究。该方法把原始图像分解成许多不同空间分辨率的子图像,高分辨率(尺寸较大)的子图像放在下层,低分辨率(尺寸较小)的图像放在上层,从而形成一个金字塔形状。
![]() 2邻域内的像素点的像素值分别取平均,作为这一区域(2
2邻域内的像素点的像素值分别取平均,作为这一区域(2 ![]() 2)像素值,得到分辨率低一级的图像。然后,将此分辨率低一级的图像再作同样的处理,也就是将低一级的图像4
2)像素值,得到分辨率低一级的图像。然后,将此分辨率低一级的图像再作同样的处理,也就是将低一级的图像4 ![]() 4邻域内的像素点的像素值分别取平均,作为这一区域(4
4邻域内的像素点的像素值分别取平均,作为这一区域(4![]()
3.2.3 相位相关法
相位相关度法是基于频域的配准常用算法。它将图像由空域变换到频域以后再进行配准。该算法利用了互功率谱中的相位信息进行图像配准,对图像间的亮度变化不敏感,具有一定的抗干扰能力,而且所获得的相关峰尖锐突出,位移检测范围大,具有较高的匹配精度。
S=F{s}=![]() e
e![]()
![]() e
e![]()
若图像s,t相差一个平移量(x ,y ),即有:
![]() )=e
)=e![]() T(
T(![]() )
)
 =e
=e ![]()
3.3 基于特征的配准
3.3.1 比值匹配法
比值匹配法算法思路是利用图像中两列上的部分像素的比值作为模板,即在参考图像T的重叠区域中分别在两列上取出部分像素,用它们的比值作为模板,然后在搜索图S中搜索最佳的匹配。匹配的过程是在搜索图S中,由左至右依次从间距相同的两列上取出部分像素,并逐一计算其对应像素值比值;然后将这些比值依次与模板进行比较,其最小差值对应的列就是最佳匹配。这样在比较中只利用了一组数据,而这组数据利用了两列像素及其所包含的区域的信息。
来源:http://www.ce86.com/a/computer/jsjyy123/200906/17-72995-2.html
——————————————————————————————————————基本介绍
图像配准和图像融合是图像拼接的两个关键技术。图像配准是图像融合的基础,而且图像配准算法的计算量一般非常大,因此图像拼接技术的发展很大程度上取决于图像配准技术的创新。早期的图像配准技术主要采用点匹配法,这类方法速度慢、精度低,而且常常需要人工选取初始匹配点,无法适应大数据量图像的融合。图像拼接的方法很多,不同的算法步骤会有一定差异,但大致的过程是相同的。一般来说,图像拼接主要包括以下五步:
折叠图像预处理
包括数字图像处理的基本操作(如去噪、边缘提取、直方图处理等)、建立图像的匹配模板以及对图像进行某种变换(如傅里叶变换、小波变换等)等操作。
折叠图像配准
就是采用一定的匹配策略,找出待拼接图像中的模板或特征点在参考图像中对应的位置,进而确定两幅图像之间的变换关系。
折叠建立变换模型
根据模板或者图像特征之间的对应关系,计算出数学模型中的各参数值,从而建立两幅图像的数学变换模型。
折叠统一坐标变换
根据建立的数学转换模型,将待拼接图像转换到参考图像的坐标系中,完成统一坐标变换。
折叠融合重构
将带拼接图像的重合区域进行融合得到拼接重构的平滑无缝全景图像。
折叠编辑本段图像拼接的基本流程图。
相邻图像的配准及拼接是全景图生成技术的关键,有关图像配准技术的研究至今已有很长的历史,其主要的方法有以下两种:基于两幅图像的亮度差最小的方法和基于特征的方法。其中使用较多的是基于特征模板匹配特征点的拼接方法。该方法允许待拼接的图像有一定的倾斜和变形,克服了获取图像时轴心必须一致的问题,同时允许相邻图像之间有一定色差。全景图的拼接主要包括以下4个步骤:图像的预拼接,即确定两幅相邻图像重合的较精确位置,为特征点的搜索奠定基础。特征点的提取,即在基本重合位置确定后,找到待匹配的特征点。图像矩阵变换及拼接,即根据匹配点建立图像的变换矩阵并实现图像的拼接。最后是图像的平滑处理。
折叠编辑本段图像拼接技术分类
图像拼接技术主要包括两个关键环节即图像配准和图像融合。对于图像融合部分,由于其耗时不太大,且现有的几种主要方法效果差别也不多,所以总体来说算法上比较成熟。而图像配准部分是整个图像拼接技术的核心部分,它直接关系到图像拼接算法的成功率和运行速度,因此配准算法的研究是多年来研究的重点。
目前的图像配准算法基本上可以分为两类:基于频域的方法(相位相关方法)和基于时域的方法。
折叠相位相关法
相位相关法最早是由Kuglin和Hines在1975年提出的,并且证明在纯二维平移的情形下,拼接精度可以达到1个像素,多用于航空照片和卫星遥感图像的配准等领域。该方法对拼接的图像进行快速傅立叶变换,将两幅待配准图像变换到频域,然后通过它们的互功率谱直接计算出两幅图像间的平移矢量,从而实现图像的配准。由于其具有简单而精确的特点,后来成为最有前途的图像配准算法之一。但是相位相关方法一般需要比较大的重叠比例(通常要求配准图像之间有50%的重叠比例),如果重叠比例较小,则容易造成平移矢量的错误估计,从而较难实现图像的配准。
折叠基于时域的方法
基于时域的方法又可具体分为基于特征的方法和基于区域的方法。基于特征的方法首先找出两幅图像中的特征点(如边界点、拐点),并确定图像间特征点的对应关系,然后利用这种对应关系找到两幅图像间的变换关系。这一类方法不直接利用图像的灰度信息,因而对光线变化不敏感,但对特征点对应关系的精确程度依赖很大。这一类方法采用的思想较为直观,大部分的图像配准算法都可以归为这一类。基于区域的方法是以一幅图像重叠区域中的一块作为模板,在另一幅图像中搜索与此模板最相似的匹配块,这种算法精度较高,但计算量过大。
按照匹配算法的具体实现又可以分为直接法和搜索法两大类,直接法主要包括变换优化法,它首先建立两幅待拼接图像间的变换模型,然后采用非线性迭代最小化算法直接计算出模型的变换参数,从而确定图像的配准位置。该算法效果较好,收敛速度较快,但是它要达到过程的收敛要求有较好的初始估计,如果初始估计不好,则会造成图像拼接的失败。搜索法主要是以一幅图像中的某些特征为依据,在另一幅图像中搜索最佳配准位置,常用的有比值匹配法,块匹配法和网格匹配法。比值匹配法是从一幅图像的重叠区域中部分相邻的两列上取出部分像素,然后以它们的比值作模板,在另一幅图像中搜索最佳匹配。这种算法计算量较小,但精度较低;块匹配法则是以一幅图像重叠区域中的一块作为模板,在另一幅图像中搜索与此模板最相似的匹配块,这种算法精度较高,但计算量过大;网格匹配法减小了块匹配法的计算量,它首先要进行粗匹配,每次水平或垂直移动一个步长,记录最佳匹配位置,然后在此位置附近进行精确匹配,每次步长减半,然后循环此过程直至步长减为0。这种算法较前两种运算量都有所减小,但在实际应用中仍然偏大,而且粗匹配时如果步长取的太大,很可能会造成较大的粗匹配误差,从而很难实现精确匹配。
stitching是OpenCV2.4.0一个新模块,功能是实现图像拼接,所有的相关函数都被封装在Stitcher类当中。这个类当中我们可能用到的成员函数有createDefault、estimateTransform、composePanorama、stitch。其内部实现的过程是非常繁琐的,需要很多算法的支持,包括图像特征的寻找和匹配,摄像机的校准,图像的变形,曝光补偿和图像融合。但这些模块的接口、调用,强大的OpenCV都为我们搞定了,我们使用OpenCV做图像拼接,只需要调用createDefault函数生成默认的参数,再使用stitch函数进行拼接就ok了。就这么简单!estimateTransform和composePanorama函数都是比较高级的应用,如果各位对stitching的流程不是很清楚的话,还是慎用。
实例也非常简单,下载链接哦:http://download.csdn.net/detail/yang_xian521/4321158。
输入原图(为了显示,我都压缩过):


















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









