







卷积神经网络
基本操作
卷积
基本词汇
Input 输入
Kernel/filter 卷积核/滤波器 用来做卷积的矩阵
Weights 权重 卷积核中元素的值
receptive field 感受野 与卷积核相对应的Input中当前对应的部分
stride 步长 卷积核每次移动的距离
activation map/feature map 特征图 做完卷积运算后的输出
padding 填充,输入的边缘补0,使得对于一定的stride,能够完成卷积
depth/channel 深度 彩色图,RGB,需要3个filter,生成3个feature map,channel为3
Output 输出
特征图大小
(N+2*padding-F)/stride+1 // N:input的长度,F:kernel的长度
操作
互相关运算:对应位置元素相乘然后求和。
池化(Pooling Layer)
在做一个缩放
保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。
最大值池化:一个filter对应的区域,找出最大值作为输出
平均值池化:平均值作为输出
AlexNet

应用了ReLU激活函数
应用了dropout(随机失活)方法防止过拟合
VGG
神经网络架构的设计逐渐变得更加抽象和模块化,VGG中出现了VGG块。
VGG块
首先有几个33的padding=1的卷积层,然后有1个22的stride=2的最大池化层
#
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_chanels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
VGG11结构
5个vgg块 + 3个全连接层
#
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks,
nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
NiN
包括LeNet、AlexNet和VGG都是通过一系列的卷积层和池化层来提取空间特征,然后通过全连接层对特征进行处理。然而,如果使用了全连接层,可能会放弃特征的空间结构。NiN(网络中的网络)提供了一个解决方法:对每个像素应用一个全连接层。
NiN块
在一个卷积层后使用了2个1*1的卷积层充当对每个元素的全连接层
#
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size,
strides,padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()
)
GoogleNet
Inception块
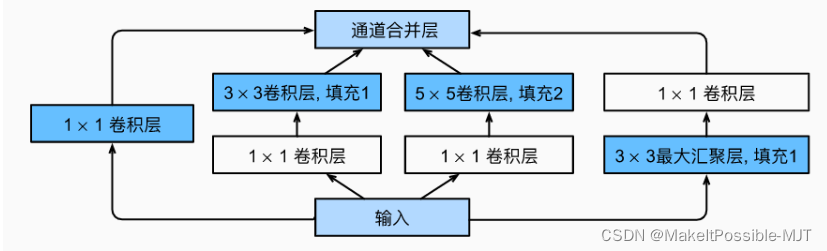
GoogleNet结构
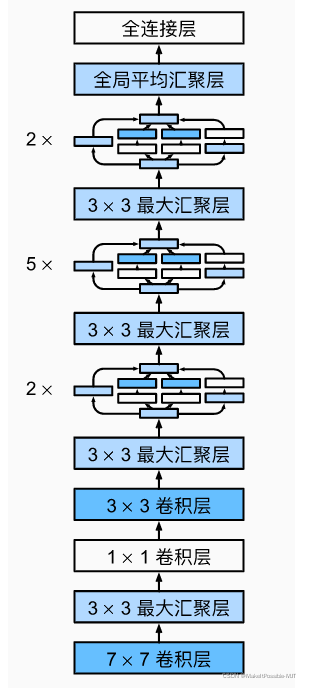
ResNet
原理
残差学习
对于一定深度的神经网络,一般情况下层数越深,准确率越高,但是当超过某一限度,神经网络就会退化。比如下图中的左图,F1到F6是越来越深的神经网络,f是我们要拟合的函数,可以看到F3比F1更加靠近f,但是F6比F1要远离f*,所以对于较复杂的神经网络,如果它没有包含前面较简单的神经网络,那么新的神经网络架构可能就会退化。
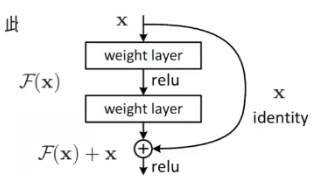
而如果复杂的神经网络包含了简单的神经网络,就不会出现退化的问题,如下图中的右图,随着神经网络越来越复杂,它越来越靠近f*。所以,对于较深层的神经网络,如果它的深层能训练成恒等映射F(x)=x,那么新模型和原模型将同样有效,同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。

可是对于深层的神经网络很难将新添加的层训练成恒等映射,针对这一问题,何凯明等提出了残差网络。它的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。即,不是去拟合H(x),而是拟合H(x)-x,这时候就不是把新添加的层拟合成一个恒等映射,而是将其逼近于0,这样训练的难度就会下降。H(x)-x就是残差。
结构
残差块
练习
0501
对于正常的图像,卷积和池化能够提取图像特征
打乱图像顺序后,使得卷积和池化难以发挥作用。
0502
LeNet的准确率不太高,只有63%。
将最大池化层换成平均池化层后,test准确率下降了1%。
将学习率更换为0.01后,发现准确率变成了50%,似乎知道了为什么软工课上用vgg跑出来的准确率是50%,呜呜。
0503
网络从LeNet更改为简化版VGG后,准确率显著提升到了82.57%。














 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









