






我以前实现的@DBLooup AJAX版,都是通过URL带参数,执行后台代理,并返回结果的方式。最近在实现一个应用模块时,看到我们公司同事的实现方式,觉得比我的更好一些,但有些缺陷。特此将代码贴出来供大家参考。具体的JS代码如下:
01
function dblookup(view,skey,column){ 02
try{
03
var url = getPath()+"/"+view+"?readviewentries&restricttocategory="+skey; 04
objHTTP = new ActiveXObject("Microsoft.XMLHTTP"); 05
//下面用get方法,在get方法中,代理取传过去的参数是用doc.query_string(0) 06
objHTTP.open("GET", vurl, false, "", "");
07
objHTTP.setRequestHeader("If-Modified-Since","0");
08
objHTTP.send(false); 09
//此处调用的是同步方法
10
resp = objHTTP.responseXML.documentElement; 11
objHTTP = null; 12
var ss="";
13
if (resp.hasChildNodes()) { 14
NodeList = resp.getElementsByTagName("viewentry")
15
for (var k=0;k 16
NodeList1=NodeList(k).getElementsByTagName("entrydata"); 17
mynode=NodeList1(column-1).firstChild;
18
mynode1=mynode.firstChild;
19
ss= mynode1.nodeValue;
20
break;
21
} 22
}else{ 23
ss=""; 24
} 25
}catch(e){ 26
ss=""; 27
} 28
return ss;
29
}
以上代码在使用URL请求视图时,使用restricttocategory进行分类限制,这样可以得到以skey为分类的视图,再通过返回的XML文档,对其进行解析得到视图中第一份文档指定列(column)中的值,并返回给调用者;
如果你想返回多个文档的指定列值,将:
ss= mynode1.nodeValue;
break;
修改为:
ss+=";"+mynode1.nodeValue;
即可。但需要注意,视图缺省只返回20个文档,相关设置在服务器文档中设置。需要返回超过20个文档时,你可以在请求的URL中加入count参数来指定需要返回文档的个数。
此函数缺点不利于扩展,假如dblookup函数已在项目中或产品模块实施,但现在需要将其功能进行扩展,加入跨库和跨服务器功能时,如果修改dblookup函数参数,则肯定会影响到现在项目中或产品模块中相关的JS代码,对升级或更新造成了不少的工作量,这些工作量又是重复的。这种情况下通常选择的是新增另一个函数,如dblookup_pro,这样会使封装的JS文件多一些冗余代码,从而增加JS文件尺寸。当然你会说,增加一个函数并不会增加JS文件多少尺寸,但你想想,都抱着这个心态,JS中这扩展点,那补充点。经过长期团队成员的修改和项目积累,会使用封装的JS文件会越来越大,到达一种冗余代码过多,但又不得不用的状态。所以我一直强调在设计通用代码时,一定要适当考虑代码容错和以后的功能扩展对现有代码的影响。这样会给今后代码维护带来非常小的工作量,虽然前期在写代码考虑的事情非常多,但你如果习惯了这种代码编写风格,会规范你的代码,提高你代码的质量,这不是每位程序员所追求的吗?
但以上代码看似正常,能运行很好。但并没有容错代码,如HTTP请求失败,视图不存在怎么办?从代码上看返回的是空值,但这个是正确的返回结果吗?但如果出现以下情况,就会出现不可估量问题:
在提交文档时,如果调用dblookup,会有可能因为网络延时造成,未返回结果就已提交文档了。如下代码片断:
1
...... 2
document.forms[0].UserCN.value = dblookup(‘vwAllUsers’,'SquallZhong',2); 3
document.forms[0].submit();
以上代码有可能让UserCN的值为空,如果在WebQuerySave()事件中有读UserCN域的值对文档进行处理,会造成程序上的运行错误。
对dblookup进行改进后,代码如下:
01
function dblookup() { 02
//返回字符串 03
var ret = null;
04
//视图别名 05
var vn = arguments[0];
06
if (vn == null || vn == "") {
07
alert("\u8bf7\u6307\u5b9a\u89c6\u56fe\u522b\u540d\uff01"); 08
return ret;
09
} 10
//关键字 11
var key = arguments[1];
12
if (key == null || key == "") {
13
alert("\u8bf7\u6307\u5b9a\u5173\u952e\u5b57\uff01"); 14
return ret;
15
} 16
//指定列名 17
var col = arguments[2];
18
if (col == null || col == "") {
19
alert("\u8bf7\u6307\u5b9a\u5217\u503c\uff01"); 20
return ret;
21
} 22
//回调函数 23
var func = arguments[3];
24
//指定数据库路径,数据库路径请使用Apps/DB.nsf。
25
//不论在WINDOW平台还是LINUX平台,在Domino平台中可使用"/"通用,并兼容URL格式 26
var dbpath = arguments[4];
27
//如果未指定数据库路径,则取当前路径
28
if (dbpath == null || dbpath == "") { 29
dbpath = getPath();
30
} 31
//将数据库路径中""转换为"/"
32
dbpath = dbpath.replace("\\", "/"); 33
//指定数据库所在服务器名称,如AS1/ACME
34
var svr = arguments[5];
35
try { 36
var url = ""; 37
if (svr == null || svr == "") {
38
url = "/" + dbpath + view + "?readviewentries&restricttocategory=" + skey; 39
} else { 40
//如果为跨DOMINO服务器请求,使用后台代理处理跨服务器请求
41
url = "/vgoresource.nsf/dblookup?openagent&login"; 42
url += "&vn=" + vn; 43
url += "&key=" + key; 44
url += "&col=" + col; 45
url += "dbpath=" + dbpath; 46
url += "svr=" + svr; 47
} 48
// 避免IECache,添加时间戳
49
url += "&__t=" + Math.random();
50
var objHTTP = null;
51
if (window.XMLHttpRequest) { 52
// 创建 Mozilla/FireFox平台的 XMLHttpRequest 对象 53
objHTTP = new XMLHttpRequest();
54
} else { 55
if (window.ActiveXObject) { 56
// 创建 IE/Windows 平台的XMLHttp对象
57
objHTTP = new ActiveXObject("Microsoft.XMLHTTP"); 58
} 59
} 60
objHTTP.open("GET", url, false); 61
objHTTP.onreadystatechange = function () { 62
if (objHTTP.readyState == 4) { 63
if (objHTTP.status == 200) { 64
//如果有回调函数 65
if (callback != null) { 66
var resp = objHTTP.responseXML.documentElement; 67
if (resp.hasChildNodes()) { 68
var NodeList = resp.getElementsByTagName("viewentry"); 69
for (var k = 0; k < NodeList.length; k++) { 70
NodeList1 = NodeList(k).getElementsByTagName("entrydata"); 71
mynode = NodeList1(column - 1).firstChild; 72
mynode1 = mynode.firstChild;
73
ret = mynode1.nodeValue;
74
} 75
} else { 76
ret = null; 77
} 78
callback(ret);
79
} else { 80
//如果没有回调函数,直接返回文本
81
return objHTTP.responseText;
82
} 83
} else { 84
return null; 85
} 86
} 87
}; 88
objHTTP.send(null);
89
} catch (e) {
90
return null; 91
} 92
}
经过整改后的代码,可实现:
dblookup(view,keystring,column-num[,callback-function[,dbpath[,servername]]])
view:视图别名
keystring:关键字查询
column-num:指定列数
callback-function:回调函数(可选)
dbpath:指定数据库路径(可选),缺省为当前数据库
servername:指定Domino服务器名称(可选),缺省为当前服务器;注:指定服务器名称时,请不要使用CN=Apps/O=ACME,这样在URL地址相加时会认为是两个参数,所以指定服务器名称时请使用Apps/ACME
方括号中为可选参数。这样可兼容以前项目所使用的dblookup(view,keystring,column-num),不需要维护已有WEB应用中调用的格式,也能实现回调函数处理功能/跨库/跨服务器功能。
有了回调函数功能,可避免在AJAX请求未完成之前,执行下面的代码,从而提高了代码的容错性,如下列代码:
01
....... 02
function savedoc() { 03
//查询是否已定义过,并回调继续提交函数
04
var key = f.StServerName.value + "!!" + f.StDBPath.value; 05
key = key.split("\\").join("/"); 06
dblookup("ArchivePolicyViewByFullDBPath", key.toLowerCase(), 1, submitdoc);
07
} 08
function submitdoc() { 09
var ret = arguments[0];
10
var f = document.forms[0];
11
if (ret == null) { 12
f.submit(); 13
} else { 14
alert("此数据库的归档策略已定义,请重新输入数据库路径!"); 15
f.StDBPath.select(); 16
f.StDBPath.focus();
17
} 18
}
后续问题考虑:
1.dblookup函数中处理是使用XML文档解析方式,如果你使用的Domino服务器是7.0以上版本,建议使用JSON来处理数据,这样效率要比XML解析效率高。如果使用JSON来处理数据,需要将视图输出格式修改为JSON输出,只需要将以下代码:
url = "/" + dbpath + view + "?readviewentries&restricttocategory=" + skey;
修改为:
url = "/" + dbpath + view + "?readviewentries&outputformat=json&restricttocategory=" + skey;
注:还需要修改对JSON数据的解析方式
2.此函数功能,并未实现根据关键字查询相应文档所指定的域名,如果哪位朋友有兴趣可以实现一下。
3.Domino中视图设置,视图中第一列必须为分类列,如果第一列不是分类列,是查不出结果的。如下图: 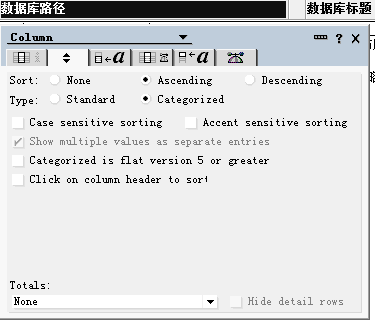
4.对于封装的JS文件,建议对其进行混淆和压缩,来提高Javascript的安全性和JS在网络中的传输速度。
参考资料:
1.JS混淆压缩工具:http://blog.csdn.net/SquallZhong/archive/2008/11/29/3410592.aspx
2.WEB性能优化及考虑:http://blog.csdn.net/SquallZhong/archive/2008/08/25/2826429.aspx















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









