







紧接我们上次的问题,如何获取服务器发送的资源,保存到本地?上一篇文章见java网络爬虫核心原理。
一、Java IO流三分游(input,output)
我们知道计算机是用来处理数据的。所有的程序,多媒体资源,在计算机内部都是以二进制形式存放的(本质是电荷的有无,磁场的有无,高低电压。高低、有无、这些形式被抽象成0或1,二进制数据,这是由硬件的物理特性决定的)。
拿我们经常看的电影为例:电影从硬盘被加载到内存,经播放器解码处理后在显示器上播放显示。这个过程中,电影(数据)从磁盘被读取到了内存。下载这个电影的时候,数据从网络(服务器)被读取到内存,然后由相应的下载程序写入到硬盘。
我们平常用电脑所做的操作,基本都离不开数据从硬盘到内存、从内存到网络(另一台设备)、从网络到内存、从内存到硬盘等的转换。也就是说数据从一个地方转移到另一个地方,是很常见的操作。Java经过高度的抽象,运用面向对象的思想,配合优秀的设计模式,为我们提供了相应的处理类,答案就是Java 的IO包。
名字起得很形象,IO流,数据从一个地方转移到另一个地方,两地之间就像连了一根水管,数据经水管从一个地方流到另一个地方。
IO流可分为两大类——字节流和字符流。字节流以二进制比特位的形式传输数据,字符流通过相应的编码,专门用来传输文本数据。但是字符流本质还是对字节流的包装。
鉴于网络数据的传输大多是以字节形式传输的,我们这里主要关注IO流中字节流部分。
字节流
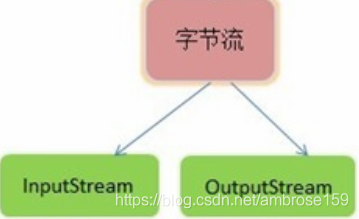
java提供两个接口,表示字节数据从一个地方(网络、内存、硬盘)的输入与输出(流入与流出)。那么,我们上次留下的问题就是,找到一种对应操作的类,让数据从网络,流向本地硬盘,保存为文件。
二、通过Java IO流实现数据从网络到本地的转移
Demo1,爬取必应首页背景图
/**
* 把URL标识的网络资源保存到本地文件
* @param url 访问的URL资源
* @param is 网络连接的输入流
* @author luckyriver
*/
public static void main(String[] args) {
URL url=null;
InputStream is=null;
try {
//以必应首页图片为例
url = new URL
("https://cn.bing.com/th?id=OHR.Montreux_ZH-CN5485205583_1920x1080.jpg&rf=LaDigue_1920x1080.jpg");
is=url.openConnection().getInputStream();//得到输入流
} catch (Exception e1) {
e1.printStackTrace();
}
//建立缓冲输入流,包装得到的普通输入流
try(
BufferedInputStream bif=new BufferedInputStream(is);
/*
建立缓冲输出流,包装文件输出流,写入数据到磁盘文件,起名为“1.jpg”,路径为项目路径
文件保存格式为jpg(或者jpeg)
*/
BufferedOutputStream bof=
new BufferedOutputStream(
new FileOutputStream(
new File("1.jpg")
)
)
)
{//读写流程
int len;
byte[] buffer=new byte[1024*10];
while (-1!=(len=bif.read(buffer))) {
bof.write(buffer, 0, len);
}
bof.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
运行代码,刷新我们的项目,可以在我们的项目目录下看到对应文件:

打开查看:

Demo2,获取必应首页H5文件
public static void main(String[] args) {
URL url=null;
InputStream is=null;
try {
//以百度首页为例
url = new URL
("https://cn.bing.com");
is=url.openConnection().getInputStream();//得到输入流
} catch (Exception e1) {
e1.printStackTrace();
}
//建立缓冲输入流,包装得到的普通输入流
try(
BufferedInputStream bif=new BufferedInputStream(is);
//建立缓冲输出流,包装文件输出流,写入数据到磁盘文件,
//资源类型为html文件,起名为“1.html”,路径为项目路径
BufferedOutputStream bof=
new BufferedOutputStream(
new FileOutputStream(
new File("1.html")
)
)
)
{//读写流程
int len;
byte[] buffer=new byte[1024*10];
while (-1!=(len=bif.read(buffer))) {
bof.write(buffer, 0, len);
}
bof.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
运行后刷新项目,打开名为1.html 的文件:
进行到这里,我们应该对爬虫有了更深的了解——通过代码模拟浏览器向服务器请求资源,可以选择把服务器响应的资源读到内存,进行数据分析,也可以选择把数据保存资源到本地磁盘。
但是,可能你也发现了,我总不能每次都手动输入URL吧?这样的话还不如直接用浏览器呢!但是,我们知道,URL一般都在网页里面的超链接里,我们整个网页都能得到,还怕得不到链接(URL)吗?如下:


接下来的问题是,如何从网页里获取资源链接(URL)。下次我会整理出一个小案例,并介绍相关工具的使用。














 2099
2099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









