







0 前言
如果说DQN从入门到放弃的前四篇是开胃菜的话,那么本篇文章就是主菜了。所以,等吃完主菜再放弃吧!
1 详解Q-Learning
在上一篇文章DQN从入门到放弃 第四篇中,我们分析了动态规划Dynamic Programming并且由此引出了Q-Learning算法。可能一些知友不是特别理解。那么这里我们再用简单的语言描述一下整个思路是什么。
为了得到最优策略Policy,我们考虑估算每一个状态下每一种选择的价值Value有多大。然后我们通过分析发现,每一个时间片的Q(s,a)和当前得到的Reward以及下一个时间片的Q(s,a)有关。有些知友想不通,在一个实验里,我们只可能知道当前的Q值,怎么知道下一个时刻的Q值呢?大家要记住这一点,Q-Learning建立在虚拟环境下无限次的实验。这意味着可以把上一次实验计算得到的Q值拿来使用呀。这样,不就可以根据当前的Reward及上一次实验中下一个时间片的Q值更新当前的Q值了吗?说起来真是很拗口。下面用比较形象的方法再具体分析一下Q-Learning。
Q-Learning的算法如下:

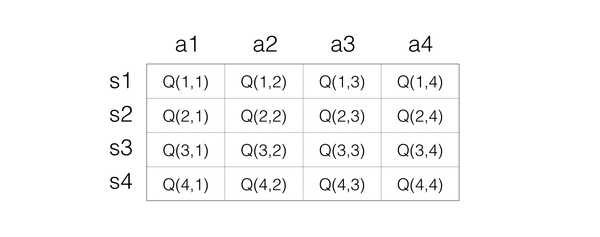
对于Q-Learning,首先就是要确定如何存储Q值,最简单的想法就是用矩阵,一个s一个a对应一个Q值,所以可以把Q值想象为一个很大的表格,横列代表s,纵列代表a,里面的数字代表Q值,如下表示:
这样大家就很清楚Q值是怎样的 了。接下来就是看如何反复实验更新。
 这样大家就很清楚Q值是怎样的 了。接下来就是看如何反复实验更新。
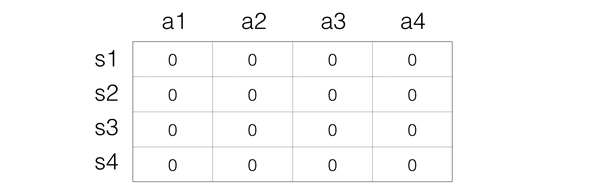
这样大家就很清楚Q值是怎样的 了。接下来就是看如何反复实验更新。Step 1:初始化Q矩阵,比如都设置为0
Step 2:开始实验。根据当前Q矩阵及方法获取动作。比如当前处在状态s1,那么在s1一列每一个Q值都是0,那么这个时候随便选择都可以。
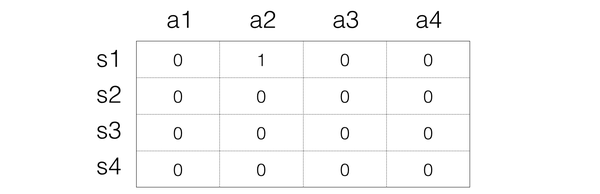
假设我们选择a2动作,然后得到的reward是1,并且进入到s3状态,接下来我们要根据
 假设我们选择a2动作,然后得到的reward是1,并且进入到s3状态,接下来我们要根据
假设我们选择a2动作,然后得到的reward是1,并且进入到s3状态,接下来我们要根据来更新Q值,这里我们假设是1,也等于1,也就是每一次都把目标Q值赋给Q。那么这里公式变成:
所以在这里,就是
那么对应的s3状态,最大值是0,所以,Q表格就变成:
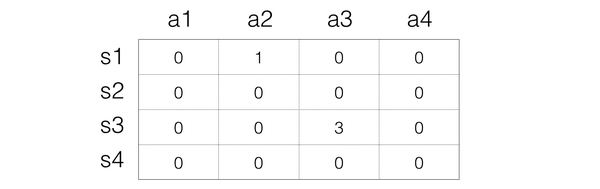
Step 3:接下来就是进入下一次动作,这次的状态是s3,假设选择动作a3,然后得到1的reward,状态变成s1,那么我们同样进行更新:
 Step 3:接下来就是进入下一次动作,这次的状态是s3,假设选择动作a3,然后得到1的reward,状态变成s1,那么我们同样进行更新:
Step 3:接下来就是进入下一次动作,这次的状态是s3,假设选择动作a3,然后得到1的reward,状态变成s1,那么我们同样进行更新:所以Q的表格就变成:
Step 4: 反复上面的方法。
就是这样,Q值在试验的同时反复更新。直到收敛。
相信这次知友们可以很清楚Q-Learning的方法了。接下来,我们将Q-Learning拓展至DQN。
2 维度灾难
在上面的简单分析中,我们使用表格来表示Q(s,a),但是这个在现实的很多问题上是几乎不可行的,因为状态实在是太多。使用表格的方式根本存不下。
举Atari为例子。
计算机玩Atari游戏的要求是输入原始图像数据,也就是210x160像素的图片,然后输出几个按键动作。总之就是和人类的要求一样,纯视觉输入,然后让计算机自己玩游戏。那么这种情况下,到底有多少种状态呢?有可能每一秒钟的状态都不一样。因为,从理论上看,如果每一个像素都有256种选择,那么就有:
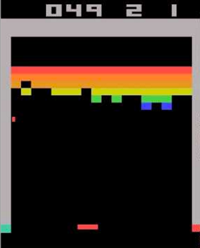 计算机玩Atari游戏的要求是输入原始图像数据,也就是210x160像素的图片,然后输出几个按键动作。总之就是和人类的要求一样,纯视觉输入,然后让计算机自己玩游戏。那么这种情况下,到底有多少种状态呢?有可能每一秒钟的状态都不一样。因为,从理论上看,如果每一个像素都有256种选择,那么就有:
计算机玩Atari游戏的要求是输入原始图像数据,也就是210x160像素的图片,然后输出几个按键动作。总之就是和人类的要求一样,纯视觉输入,然后让计算机自己玩游戏。那么这种情况下,到底有多少种状态呢?有可能每一秒钟的状态都不一样。因为,从理论上看,如果每一个像素都有256种选择,那么就有:这简直是天文数字。所以,我们是不可能通过表格来存储状态的。我们有必要对状态的维度进行压缩,解决办法就是 价值函数近似Value Function Approximation
3 价值函数近似Value Function Approximation
什么是价值函数近似呢?说起来很简单,就是用一个函数来表示Q(s,a)。即
f可以是任意类型的函数,比如线性函数:
其中是函数f的参数。
大家看到了没有,通过函数表示,我们就可以无所谓s到底是多大的维度,反正最后都通过矩阵运算降维输出为单值的Q。
这就是价值函数近似的基本思路。
如果我们就用来统一表示函数f的参数,那么就有
为什么叫近似,因为我们并不知道Q值的实际分布情况,本质上就是用一个函数来近似Q值的分布,所以,也可以说是
4 高维状态输入,低维动作输出的表示问题
对于Atari游戏而言,这是一个高维状态输入(原始图像),低维动作输出(只有几个离散的动作,比如上下左右)。那么怎么来表示这个函数f呢?
难道把高维s和低维a加在一起作为输入吗?
必须承认这样也是可以的。但总感觉有点别扭。特别是,其实我们只需要对高维状态进行降维,而不需要对动作也进行降维处理。
那么,有什么更好的表示方法吗?
当然有,怎么做呢?
其实就是,只把状态s作为输入,但是输出的时候输出每一个动作的Q值,也就是输出一个向量,记住这里输出是一个值,只不过是包含了所有动作的Q值的向量而已。这样我们就只要输入状态s,而且还同时可以得到所有的动作Q值,也将更方便的进行Q-Learning中动作的选择与Q值更新(这一点后面大家会理解)。
5 Q值神经网络化!
终于到了和深度学习相结合的一步了!
意思很清楚,就是我们用一个深度神经网络来表示这个函数f。
这里假设大家对深度学习特别是卷积神经网络已经有基本的理解。如果不是很清楚,欢迎阅读本专栏的CS231n翻译系列文章。
以DQN为例,输入是经过处理的4个连续的84x84图像,然后经过两个卷积层,两个全连接层,最后输出包含每一个动作Q值的向量。
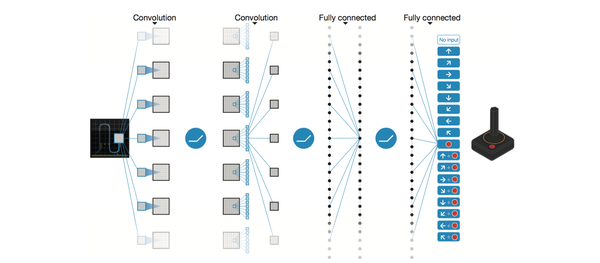 以DQN为例,输入是经过处理的4个连续的84x84图像,然后经过两个卷积层,两个全连接层,最后输出包含每一个动作Q值的向量。
以DQN为例,输入是经过处理的4个连续的84x84图像,然后经过两个卷积层,两个全连接层,最后输出包含每一个动作Q值的向量。对于这个网络的结构,针对不同的问题可以有不同的设置。如果大家熟悉Tensorflow,那么肯定知道创建一个网络是多么简单的一件事。这里我们就不具体介绍了。我们将在之后的DQN tensorflow实战篇进行讲解。
总之,用神经网络来表示Q值非常简单,Q值也就是变成用Q网络(Q-Network)来表示。接下来就到了很多人都会困惑的问题,那就是
怎么训练Q网络???
6 DQN算法
我们知道,神经网络的训练是一个最优化问题,最优化一个损失函数loss function,也就是标签和网络输出的偏差,目标是让损失函数最小化。为此,我们需要有样本,巨量的有标签数据,然后通过反向传播使用梯度下降的方法来更新神经网络的参数。
所以,要训练Q网络,我们要能够为Q网络提供有标签的样本。
所以,问题变成:
如何为Q网络提供有标签的样本?
答案就是利用Q-Learning算法。
大家回想一下Q-Learning算法,Q值的更新依靠什么?依靠的是利用Reward和Q计算出来的目标Q值:
因此,我们把目标Q值作为标签不就完了?我们的目标不就是让Q值趋近于目标Q值吗?
因此,Q网络训练的损失函数就是
上面公式是即下一个状态和动作。这里用了David Silver的表示方式,看起来比较清晰。
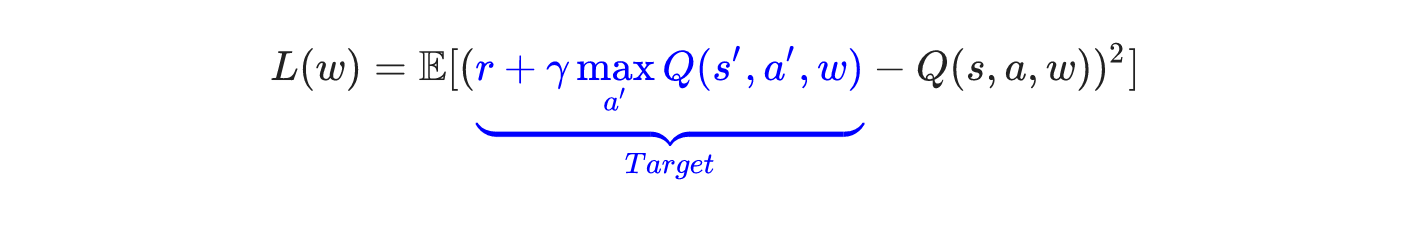 上面公式是
上面公式是既然确定了损失函数,也就是cost,确定了获取样本的方式。那么DQN的整个算法也就成型了!
接下来就是具体如何训练的问题了!
7 DQN训练
我们这里分析第一个版本的DQN,也就是NIPS 2013提出的DQN。
我们分析了这么久终于到现在放上了DQN算法,真是不容易。如果没有一定基础直接上算法还真是搞不明白。
 我们分析了这么久终于到现在放上了DQN算法,真是不容易。如果没有一定基础直接上算法还真是搞不明白。
我们分析了这么久终于到现在放上了DQN算法,真是不容易。如果没有一定基础直接上算法还真是搞不明白。具体的算法主要涉及到Experience Replay,也就是经验池的技巧,就是如何存储样本及采样问题。
由于玩Atari采集的样本是一个时间序列,样本之间具有连续性,如果每次得到样本就更新Q值,受样本分布影响,效果会不好。因此,一个很直接的想法就是把样本先存起来,然后随机采样如何?这就是Experience Replay的意思。按照脑科学的观点,人的大脑也具有这样的机制,就是在回忆中学习。
那么上面的算法看起来那么长,其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降!
也就是
在DQN中增强学习Q-Learning算法和深度学习的SGD训练是同步进行的!
通过Q-Learning获取无限量的训练样本,然后对神经网络进行训练。
样本的获取关键是计算y,也就是标签。
8 小结
好了,说到这,DQN的基本思路就介绍完了,不知道大家理解得怎么样?在下一篇文章中,我们将分析DQN在这一年来的发展变化!感谢知友们的关注!
文中图片引用自
[1] Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).
[2] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning."Nature 518.7540 (2015): 529-533.














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









