







https://zhuanlan.zhihu.com/p/29688475
2017 VQA Challenge 第一名技术报告
作者丨罗若天
学校丨TTIC博士生
研究方向丨NLP,CV
1. 前言
之前听 Chris Manning 讲过一个 talk,说他们复现别人的 paper,按照别人的算法写,做到了比原本那篇 paper 高了 10 个点的结果。还有听认识的同学说,有一年因为算法的 performance 不够好论文被拒了,第二年重新回过去跑那个代码,随便调了调,performance 就比当时他们提交的时候高了很多。
我们做玄学的,好的 idea 固然重要,然而一个好的 idea 可能带来的效果的提升还不如一个好的 trick。当然啦,最好的是 trick 又有效,而且也有一个好的故事。
所以,这里推荐今年 VQA Challenge 的一篇技术报告,名字叫:
Tips and Tricks for Visual Question Answering
从名字就可以看出来,这篇文章没有任何新颖的 idea,完全就是工程上的脏活累活,但是将作者试的所有结构都列举了出来,并做了详细的 ablation study。
虽然这篇文章中只讨论了在 VQA 上的 performance,但是可能这些 trick 也能用到其他多模态的问题上。就算不能用,这篇文章至少也告诉了你,你有哪些东西可以调。
大家可以把这篇稿子当作一篇翻译稿,我自己也不是做 VQA,所以有些东西可能不是很精准,所以我就按照论文里怎么说怎么来,我就不多做评论了。
论文地址:https://arxiv.org/abs/1708.02711
PPT(作者获奖后做的报告):
http://cs.adelaide.edu.au/~Damien/Research/VQA-Challenge-Slides-TeneyAnderson.pdf
2. VQA 背景
VQA 全称是 visual question answering。形式是给一个图片和一个关于这张图片的问题,输出一个答案。

VQA 的挑战之处在于,这是一个多模态的问题,你需要同时了解文字和图片,并进行推理,来得到最后的答案(如果需要用到 common sense 常识的话就更困难了)。类似的多模态的问题有 image captioning,visual dialog 等等。
3. 数据集
大家比较常用的数据集就是 VQA 这个数据集,来自 Gatech 和微软;他们在去年发布了第一个版本。由于这个数据集很新,所以还存在一些问题:你可以用简单的通过死记硬背来回答对很多问题,获得 ok 的效果。比如说 yes/no 问题,如果永远回答 yes,你就能答对大部分。所以这个数据集的答案有一定先验,不是很平衡。
今年,他们在去年的基础上,采集了新的数据,发布了 VQA-v2 的版本,这个版本比之前的版本又大了一倍。一共有 650000 的问题答案对,涉及 120000 幅不同的图片。
这个新的数据库主要解决了答案不平衡的问题。对于同一个问题,他们保证,有两张不同的图片,使得他们对这个问题的答案是不同的。

在新的 VQA-v2 中,对于 yes/no 问题,yes 和 no 的回答是五五开。
4. VQA 基本建模方法
首先把 VQA 问题看作分类问题。由于 VQA 数据集中的问题大多跟图片内容有关,所以其实可能的正确答案的个数非常有限,大概在几百到几千个。
一般来说,会根据训练数据集中答案出现的次数,设定一个阈值,只保留出现过一定次数的答案,作为答案的候选选项。然后把这些候选答案当作不同的标签,这样的话 VQA 就可以当作一个分类问题。
其次是使用 Joint embedding 方法。就是对于一张图片,一个问题,我们分别对图片和问题用神经网络进行 embed,把他们投影到一个共同的“语义”空间中,然后对图片和问题特征进行一些操作(比如连接,逐元素相乘啊等等),最后输入进一个分类网络;
根据训练集的数据 end-to-end 训练整个网络。
以下为本文的整体框架:
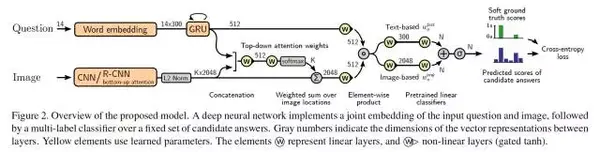
简而言之,这是一个 joint RNN/CNN embedding 模型,加上一个简单的问题对图片的注意力机制。
5. 本文使用的一些 trick 汇总:
· 把 VQA 看成多类别分类(mutli-label clasification)问题,而不是多选一;
· 使用 soft score 作为 label;
· 使用 gated tanh 作为非线性层的 activation;
· 使用了 bottom-up 的图片特征;
· 用预训练的特征对最后的分类网络进行初始化;
· 训练时使用大 mini-batch,并在 sample 训练数据时使用均衡的 sample 方法。
从最简单的开始介绍:
· 非线性层
文章里全部是用了gated tanh 作为非线性层。

本质上就是原来的 tanh 激励上根据获得的 gate 进行了 mask,其实是跟 LSTM 和 GRU 中间非线性用的是一样的。
本文中,作者将该层与 tanh 和 ReLU 进行了比较,gated tanh 能获得更好的结果。但是本文没有尝试 Gated CNN 文章中用到的 Gated Linear Layer 进行比较(在 Gated CNN 中,GLU 要比 GTU 更好)。
· 多类别分类
在 VQA-v2 数据集中,由于数据采集自不同的 turker,所以同一张图片同一个问题可能会有多个答案。在数据集中,每个答案都有 0 到 1 的 accuracy。
基于这样的事实,本文并没有像其他论文一样做多选一的分类问题,而是转换成了 multi-label 分类问题。原本的 softmax 层被改为了 sigmoid 层。因此,最后的网络输出给了每个答案一个 0-1 的分数。
由于每个答案的 accuracy 是 0-1,所以本文使用了 soft target score。其中,$s$ 是 ground truth,$\hat s$ 是网络的输出。
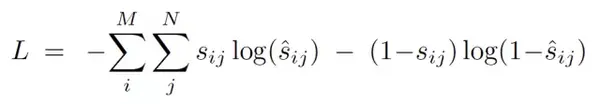
这个公式和普通的二值分类的 binary cross entropy 非常像。事实上,如果 ground truth accuracy 是 0 或者 1 的话,这个公式就等价于 binary cross entropy。
虽然在预处理时,我们根据答案的出现次数滤掉了一些不常见的答案,但是我们仍然会使用这一部分数据,只是认为这个问题所有候选答案的 accuracy 都是 0。
看成多类别分类效果更好的原因有二:首先,sigmoid output 能够对有多个答案的数据进行训练;其次,soft target score 提供了更丰富的训练信号。
· 分类网络初始化
由于分类网络最后一层是个全连接层,所以最后每个答案的分数就是图片特征和问题特征与网络权重的点积。所以我们可以把最后一层全连接层权重的每一行都是每个答案的特征,这样最后的分数其实就是图片特征和问题特征与答案特征的相似度。
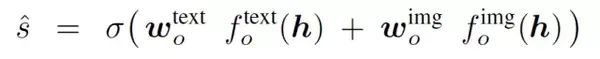
所以 $w_o^\text{text}$ 的每一行通过答案的 glove feature 进行初始化。对 $w_o^\text{img}$,他们使用了 google images。对每个答案,在 google 上进行了搜索,挑选了 10个 最相关的图片,计算了 10 张图片 resnet feature 的平均值,用它做了 $w_o^\text{img}$ 每一行初始化的值。
· 大 minibatch 和均衡 sample
本文他们尝试了多种 minbatch size 的可能,他们发现,256, 384,512 作为 batch size 效果都不错,比更多数据或者更少的数据要更好。
均衡 sample 的设计来源于 vqa v2 本身的特性。由于每个问题,都可以找到不同的答案,所以这里作者强制在同一个 batch 中,每个问题都要出现两次,并且问题的答案需要是不同的。
· bottom-up image feature
这部分的内容来源于他们另外一篇 paper:https://arxiv.org/abs/1707.07998
这个 trick 是结果提升最大的来源,本质上,这里他们使用了一种更强的图片特征,所以获得了最好的结果提升。那篇文章中他们将这图像特征也用在了 capitoning,获得了当时 leaderboard 的第一名。
具体方法是,他们用 visual genome 训练了一个 Faster RCNN,每张图片的 feature 就是图片中 top-K 物体的 feature。他们尝试了对每张图片固定 K 的值,和根据一个阈值来选择物体(每张图片可以有不同的 K)。
跟普通的 resnet 的区别在于,这里他们是直接对 object 做 attention,而不是图片中每个方块区域进行 attention。从直观的理解来说,这样的 attention 更加有解释性。
注意的是,这里 cnn 没有进行 finetune,每张图片的 feature 都是事先已经提取好的了。
这部分在 Visual Genome 上训练 Faster RCNN 的代码已经公布在 github:
https://github.com/peteanderson80/bottom-up-attention

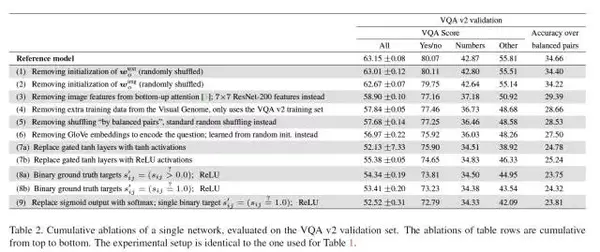
这几改进对结果的影响可以在此表中展现,可以看到每移除一项变化对结果的影响。
6. 其余模型细节
文本处理
对于问题,每个问题通过空格和标点分割成一个一个单词,包括数字组成的单词也全部当作单独的一个独立的单词。句子被截断到最多 14 个单词(因为只有 0.25% 的问题长度大于 14),每个词的 embedding 长度设为 300。
用 wikipedia/gigaword 上训练的 pretrained glove 特征进行初始化,长度小于 14 的句子填补全 0 特征,word embeedding 送入一个 forward-GRU,hidden size 为 512。他们使用 final state 作为 feature。
他们的句子中没有包含 start 和 end token,也没有 dynamic unrolling,每个句子在提取特征的时候都看作长度 14 的句子。他们发现 recurrent unit 跑相同的 iteration 更加有效(文章中并没有给出这个部分的 ablation study,笔者:这个其实还挺不常见的) 。
他们也比较了其他算法:比如说使用不同大小的 word embedding,embedding 随机初始化,逆序 GRU,双向 GRU,两层 GRU,词包模型;其中单层顺序 GRU,300 维 glove 初始化比其他尝试都要好(实际上词包模型效果十分接近,这跟 IBOWIMG 的发现是差不多的)。
RNN hidden size
他们也试了不同大小的 hidden state size,最后选用了 512,虽然更大的 hidden state size 有可能获得更好的结果,但是训练多次的结果 variance 也会更大。
图像特征的 l2 norm
文中声称图像特征最好根据 l2 norm 归一化。虽然文中也没有给出不归一化的结果进行比较,但这跟笔者在类似问题上的经验是一致的。
注意力机制
基本上这个注意力机制和其他的差不多:将 sentence embeeding $q$ 连接到到每个 location 的 image feature,然后通过一个 MLP 获得每个 location 的分值,然后再通过一个 softmax 获得 attention map,然后以后的 visual feature 就是每一个 location 的 feature 的加权平均。
这篇文章仅使用了这个最简单的注意力机制,并没有与其他更 fancy 的模型进行比较。
Multimodal fusion
这篇文章的 fusion 简单到爆炸,就是先对视觉特征和文本特征通过一个非线性层,然后进行一个 hadamard product,就是逐元素相乘。他们和 concatenation 比较效果要更好(并没有在文章中的表格中体现)。但他们没有尝试其他的 fusion 方式。
这次 vqa 的并列第二名都是对 fusion 层进行改进,包括其实很多最近其他做 vqa 的论文也都是在这个地方改来改去,所以可能如果换成那些效果会更好。
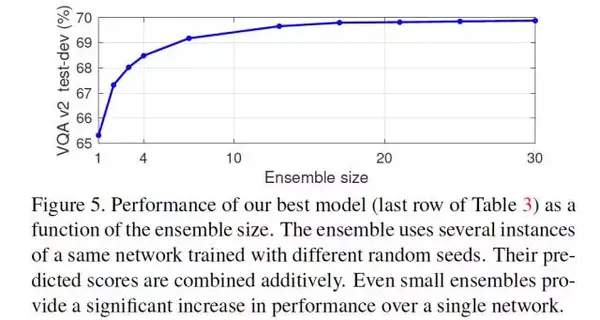
Ensemble
Ensemble 对于结果的提升也是非常大的,下图表现了 Ensemble 的个数对结果的影响。
额外的训练数据
他们同时也使用了 visual genome 中的 qa 数据。他们只保留了 visual genome 中答案在候选答案中的问题对作为训练数据。这对结果有一定的提高(但非常微小)。
如果把答案不在候选答案中的问题,看成全 0 的 label 的话,反而会导致更差的结果。
更难的 evaluation metric
他们不但使用了 VQA 标准的 accruacy 作为 evaluation metric,他们还使用了 Accuracy over pairs。这是平衡问题对(也就是同样问题,不同答案)都回答准确的比例。他们最后在甄选模型的时候很大程度地考虑了这个新的 metric。
7. 总结
修炼玄学的悲欢,我们这些努力不简单。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
微信公众号:PaperWeekly
新浪微博:@PaperWeekly














 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









