









21页Visual Transformer综述,共计156篇参考文献!本文将视觉Transformer模型根据不同的任务进行分类(如检测、分类、视频等),并分析了这些方法的优缺点!
注:文末附**【Transformer】**学习交流群
A Survey on Visual Transformer

- 作者单位:华为诺亚, 北京大学, 悉尼大学
- 论文:https://arxiv.org/abs/2012.12556
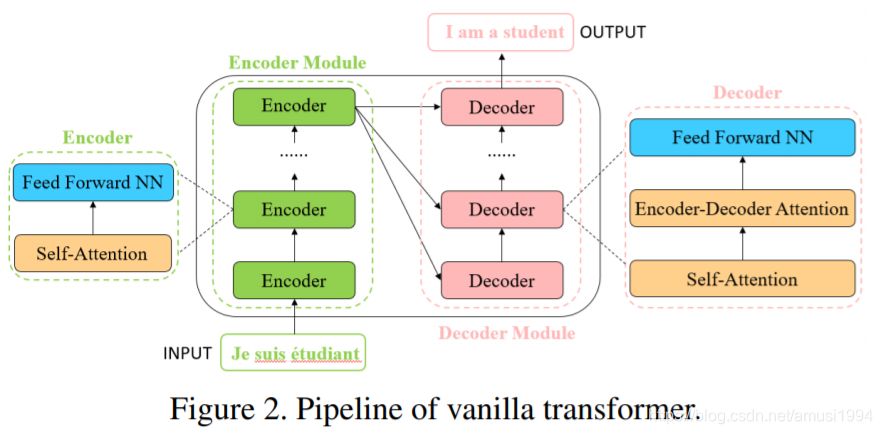
Transformer是一种主要基于自注意力机制的深度神经网络,最初应用于自然语言处理领域。受到Transformer强大的表示能力的启发,研究人员提议将Transformer扩展到计算机视觉任务。与其他网络类型(例如CNN和RNN)相比,基于Transformer的模型在各种视觉基准上显示出竞争甚至更好的性能。
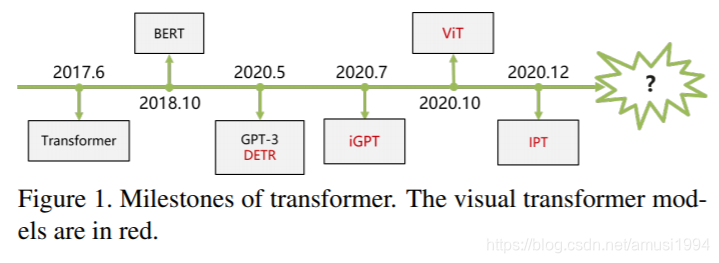
在本文中,我们通过将这些视觉Transformer模型分类为不同的任务,并分析了这些方法的优缺点,提供了文献综述。特别地,主要类别包括基本图像分类,高级视觉,低级视觉和视频处理。
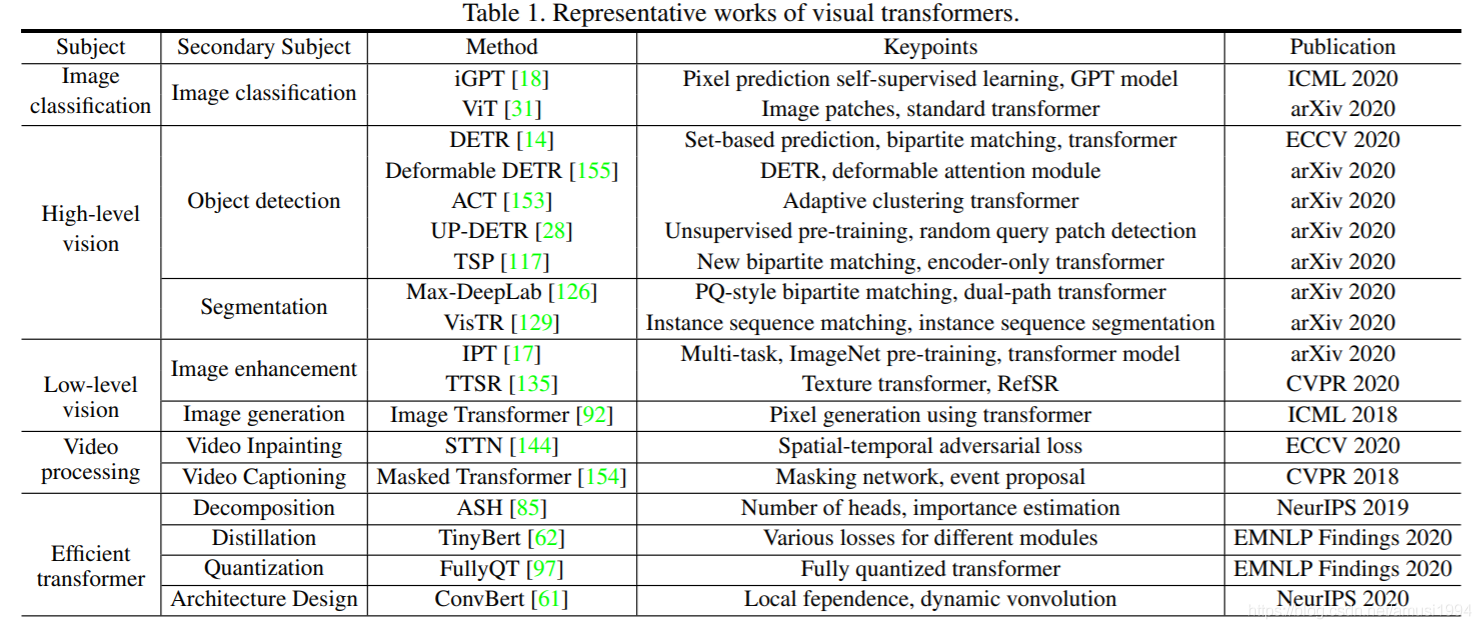
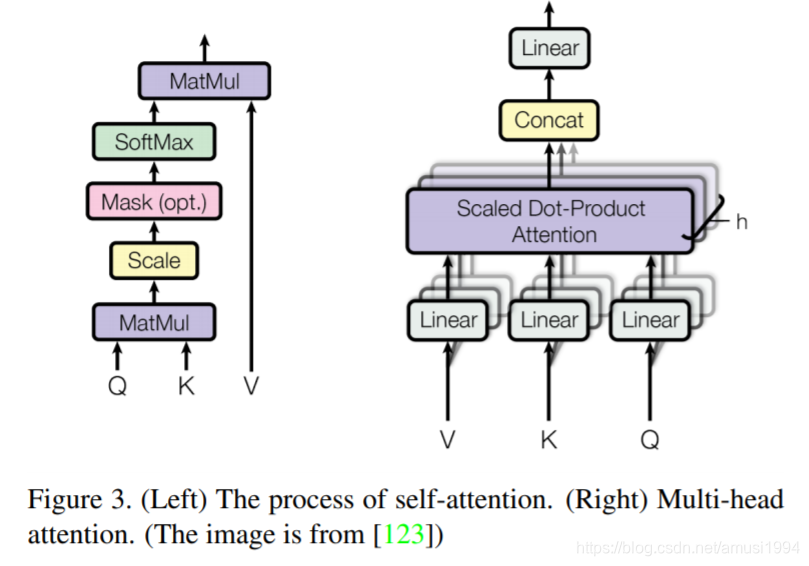
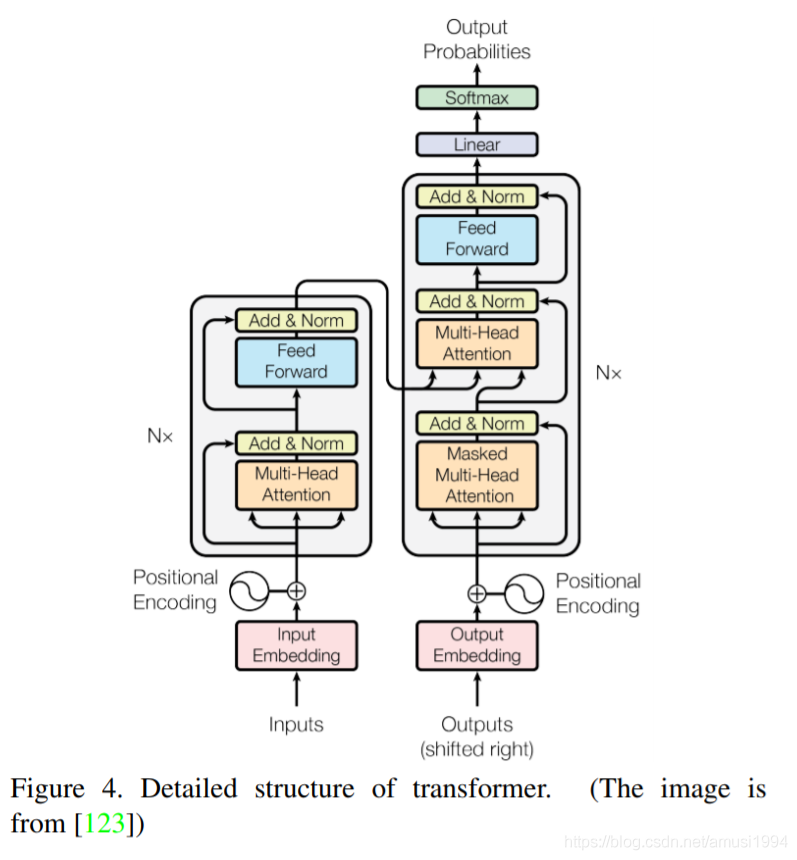
由于自注意力是的Transformer基本组成部分,因此也简要回顾了计算机视觉中的自注意力。包括有效的Transformer方法,可将Transformer推入实际应用。
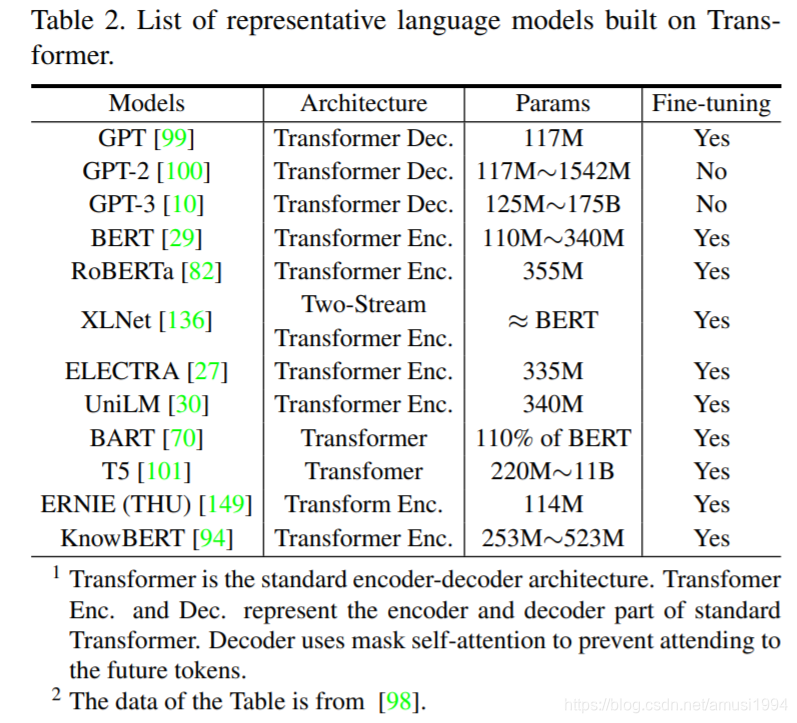
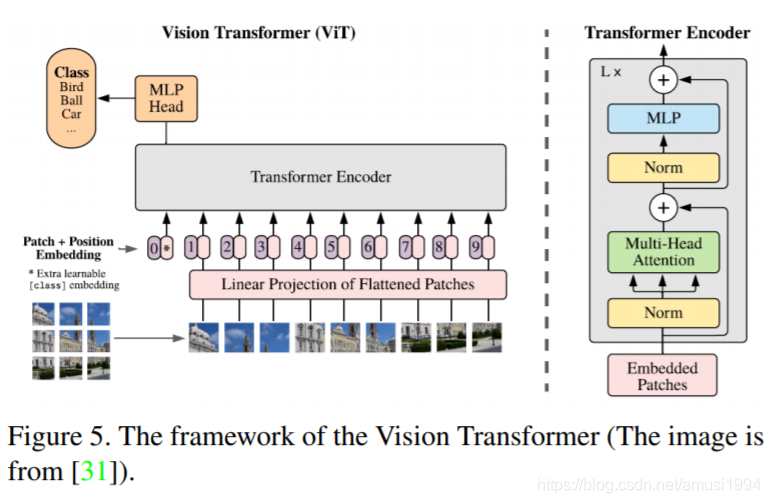
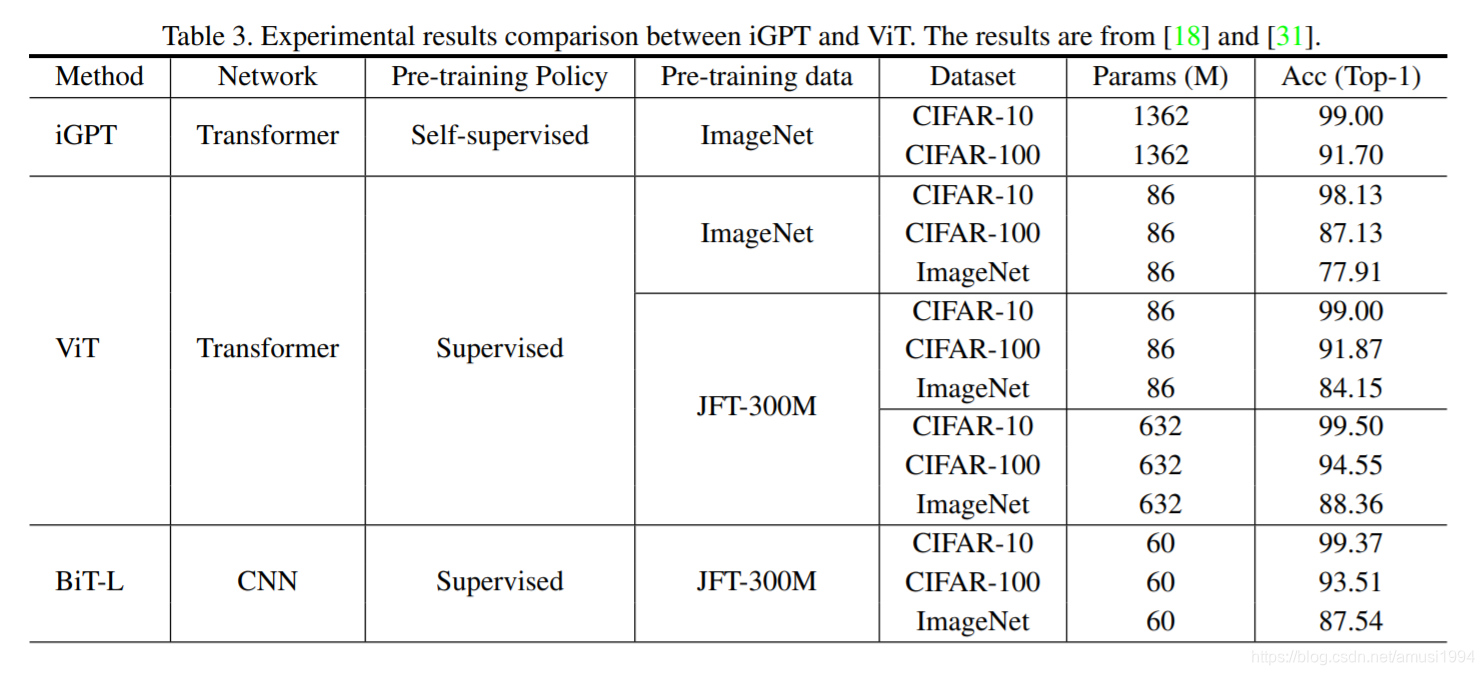
视觉Transformer近期很有代表性的工作,图像分类有:iGPT、ViT、BiT-L等
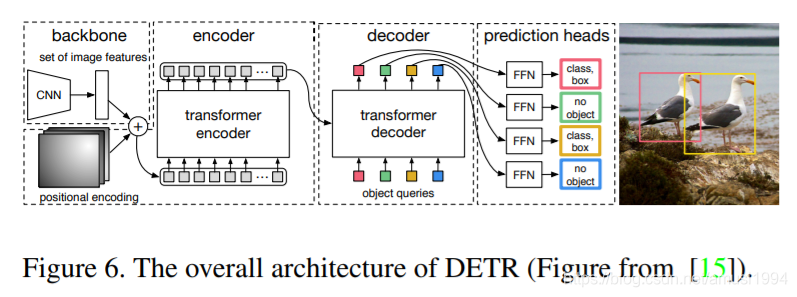
目标检测有:DETR
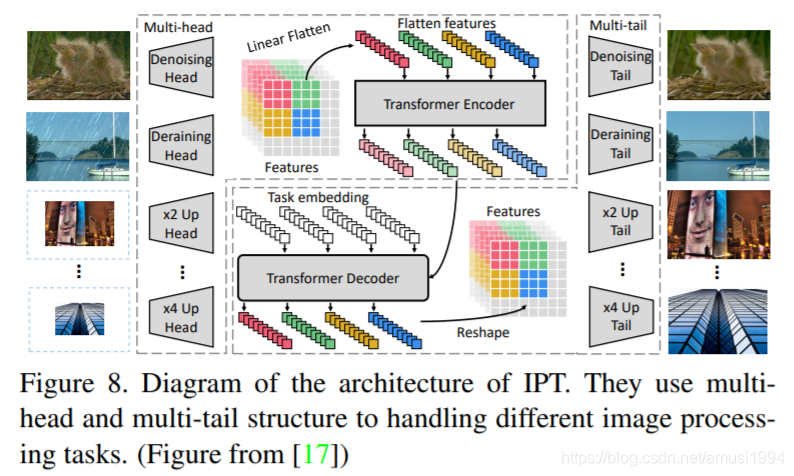
Low-level视觉有:IPT
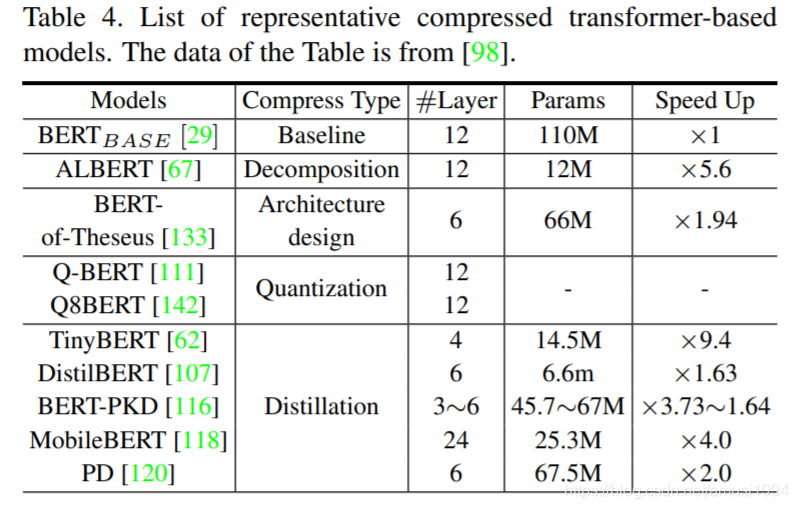
还有很多方向的Transformer应用介绍,详见综述
Transformer交流群
已建立CVer-Transformer微信交流群!想要进Transformer学习交流群的同学,可以直接加微信号:CVer5555。加的时候备注一下:Transformer+学校/企业名称+昵称,即可。然后就可以拉你进群了。
强烈推荐大家关注CVer知乎账号和CVer微信公众号,可以快速了解到最新优质的CV论文。















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









