








上节课我们一起学习了Hadoop集群测试,这节课我们一起学习一下Sqoop,Sqoop是专门用来迁移数据的,它可以把数据库中的数据迁移到HDFS文件系统,当然也可以从HDFS文件系统导回到数据库。
我来说一下Sqoop的使用场景,假如你们公司有个项目运行好长时间了,积累了大量的数据,现在想升级项目并换种数据库进行存储原来的数据,那么我们就需要先把数据都存放到另一个地方,然后再用新数据库的语句把这些数据插入到新的数据库。在没有Sqoop之前,我们要做到这一点是很困难的,但是现在有了Sqoop,事情就变的简单多了,Sqoop是运行在Hadoop之上的一个工具,底层运用了MapReduce的技术,多台设备并行执行任务,速度当然大大提高,而且不用我们写这方面的代码,它提供了非常强大的命令,我们只需要知道怎样使用这些命令,再加上一些SQL语句就可以轻轻松松实现数据的迁移工作。
接下来我们便正式开始学习怎样使用Sqoop。
第一步:环境准备
1.1 从Sqoop官网下载安装包并解压到/itcast目录
大家可以参考:http://blog.csdn.net/u012453843/article/details/52951277这篇博客下载sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
Sqoop的运行需要Yarn和HDFS,它只需要知道Yarn的管理者角色ResourceManager和HDFS的管理者角色NameNode在哪台设备上就可以,我们在搭建集群的时候每台设备上都有相同的6个配置文件,因此我们把Sqoop放到任何一台设备上都可以。现在itcast03上的进程是最少的,我们便把Sqoop放到itcast03上吧。
我们使用工具把sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz上传到Itcast03的root根目录下,如下图所示。
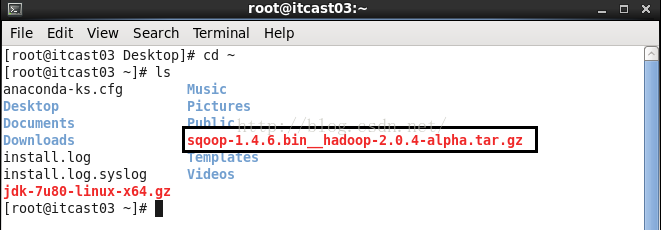
接着我们把sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz解压到/itcast目录下,执行的命令如下。
[root@itcast03 ~]#tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /itcast/
解压完之后我们到/itcast目录下查看一下,发现已经有sqoop的包了,如下所示。
[root@itcast03 ~]# cd /itcast/
[root@itcast03 itcast]# ls
hadoop-2.2.0 sqoop-1.4.6.bin__hadoop-2.0.4-alpha
[root@itcast03 itcast]#
sqoop-1.4.6.bin__hadoop-2.0.4-alpha这么长的名字我们操作起来不方便,给它起个简单的名字sqoop-1.4.6,如下所示。
[root@itcast03 itcast]#mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6
[root@itcast03 itcast]# ls
hadoop-2.2.0 sqoop-1.4.6
[root@itcast03 itcast]#
那么,我们用不用配置Sqoop呢,如果你的环境已经配置了NameNode和ResourceManager在哪台设备上,那么我们不用配置任何内容便可以使用Sqoop,现在我们的集群环境中core-site.xml和hdfs-site.xml两个文件指定了NameNode在哪两台设备上,yarn-site.xml指定了ResourceManager在哪台设备上,因此我们不用作任何配置了。
那么问题又来了,Sqoop是怎么知道我们集群的配置呢,其实Sqoop会自动去查找这台设备上HADOOP_HOME的位置,找到之后它会自动读取hadoop下面的配置文件,从而它也就知道了NameNode和ResourceManager的位置。
[root@itcast03 itcast]#echo $HADOOP_HOME
/itcast/hadoop-2.2.0
[root@itcast03 itcast]#
1.2 安装MySQL数据库
大家可以参考:http://blog.csdn.net/u012453843/article/details/52951422这篇博客来下载并配置使用Mysql
1.3 Hadoop集群
大家可以参考:http://blog.csdn.net/u012453843/article/details/52829830这篇博客来搭建集群。
第二步:启动Sqoop
2.1 经过了第一步的准备工作后,我们终于可以来启动Sqoop了,启动之前我们先看看Sqooop的目录,如下所示。可以看到,在sqoop-1.4.6的bin目录下有很多命令,我们最最常用的便是sqoop了,它基本上能满足我们的所有要求了。因为它后面可以接很多参数,这些参数的功能非常强大。
[root@itcast03 itcast]# ls
hadoop-2.2.0 sqoop-1.4.6
[root@itcast03 itcast]# cd sqoop-1.4.6/
[root@itcast03 sqoop-1.4.6]# ls
bin conf lib README.txt src
build.xml docs LICENSE.txt sqoop-1.4.6.jar testdata
CHANGELOG.txt ivy NOTICE.txt sqoop-patch-review.py
COMPILING.txt ivy.xml pom-old.xml sqoop-test-1.4.6.jar
[root@itcast03 sqoop-1.4.6]# cd bin
[root@itcast03 bin]# ls
configure-sqoop sqoop-export sqoop-list-tables
configure-sqoop.cmd sqoop-help sqoop-merge
sqoop sqoop-import sqoop-metastore
sqoop.cmd sqoop-import-all-tables sqoop-version
sqoop-codegen sqoop-import-mainframe start-metastore.sh
sqoop-create-hive-table sqoop-job stop-metastore.sh
sqoop-eval sqoop-list-databases
[root@itcast03 bin]#
我们再来看看sqoop-1.4.6的conf目录,conf目录下有个sqoop-site.xml文件,在这里面我们可以配置一些个性化的内容,这里我们可以不做任何处理。
[root@itcast03 sqoop-1.4.6]# cd conf/
[root@itcast03 conf]# ls
oraoop-site-template.xml sqoop-env-template.cmd sqoop-env-template.sh sqoop-site-template.xml sqoop-site.xml
[root@itcast03 conf]#
接下来我们便启动sqoop,我们还是先回到sqoop的bin目录下,然后使用命令./sqooop来启动,启动的过程有很多警告,这是因为我们还没有安装相关工具。我们不管它。
[root@itcast03 bin]# ./sqoop
Warning: /itcast/sqoop-1.4.6/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /itcast/sqoop-1.4.6/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /itcast/sqoop-1.4.6/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /itcast/sqoop-1.4.6/bin/../../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
Try 'sqoop help' for usage.
[root@itcast03 bin]#
第三步:把Sqoop目录配置到环境变量(这步可以不配置,只是所有命令需要到sqoop的bin目录下去操作,比较麻烦)
由于我们是在itcast03上操作sqoop的,因此我们便在itcast03上配置它的环境变量,使用的命令是vim /etc/profile,在最下方添加我们的SQOOP_HOME,如下红色字体的内容就是我们要添加的内容。
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/itcast/hadoop-2.2.0
export SQOOP_HOME=/itcast/sqoop-1.4.6
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SQOOP_HOME/bin:$PATH
配置完环境变量之后别忘了使我们的环境变量生效,我们使用的命令是:source /etc/profile
第四步:导入
4.1 我们现在想把数据库sqoop下的Student表中的数据迁移到HDFS,我们先看看Student表中都有哪些数据,可以看到有10条数据,我们就要把这10条数据上传到HDFS。(需要注意的是:Student表一定要有主键,否则会有问题)
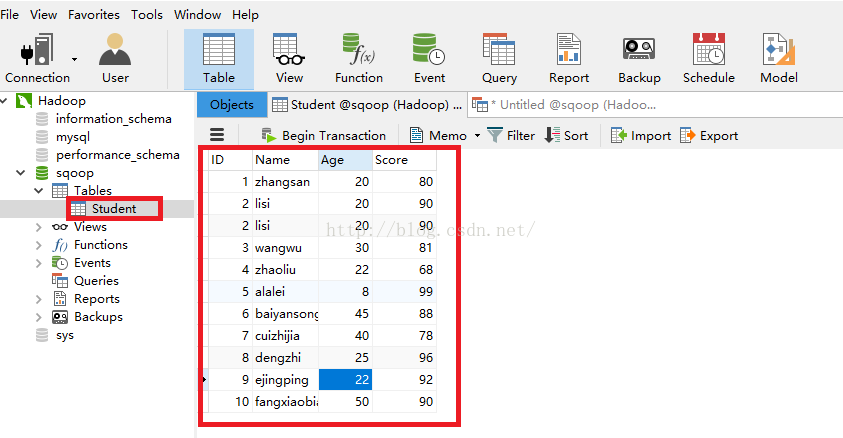
4.1.1 在开始导入之前,我们需要先把jdbc的驱动放到/itcast/sqoop-1.4.6/lib目录下,驱动包大家可以到官网下载也可以直接到:http://download.csdn.net/detail/u012453843/9667329这个网址下载。
[root@itcast03 ~]# ls
anaconda-ks.cfg Music
Desktop mysql-connector-java-5.1.40-bin.jar
Documents Pictures
Downloads Public
install.log sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
install.log.syslog Templates
jdk-7u80-linux-x64.gz Videos
[root@itcast03 ~]# cp mysql-connector-java-5.1.40-bin.jar /itcast/sqoop-1.4.6/lib
[root@itcast03 ~]#
4.1.2 设置你的itcast03设备可以远程登录到数据库。
默认情况下我们的itcast03是无法远程登录到数据库的,直接进行导入操作的话会报如下错误:
16/10/29 02:21:06 ERROR manager.SqlManager: Error executing statement: java.sql.SQLException: null, message from server: "Host 'itcast03' is not allowed to connect to this MySQL server"
java.sql.SQLException: null, message from server: "Host 'itcast03' is not allowed to connect to this MySQL server"
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:964)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:897)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:886)
at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1040)
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2253)
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2284)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2083)
at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:806)
at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:410)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:328)
at java.sql.DriverManager.getConnection(DriverManager.java:571)
at java.sql.DriverManager.getConnection(DriverManager.java:215)
at org.apache.sqoop.manager.SqlManager.makeConnection(SqlManager.java:885)
at org.apache.sqoop.manager.GenericJdbcManager.getConnection(GenericJdbcManager.java:52)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:744)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:767)
at org.apache.sqoop.manager.SqlManager.getColumnInfoForRawQuery(SqlManager.java:270)
at org.apache.sqoop.manager.SqlManager.getColumnTypesForRawQuery(SqlManager.java:241)
at org.apache.sqoop.manager.SqlManager.getColumnTypes(SqlManager.java:227)
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:295)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1833)
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1645)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:107)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:478)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605)
at org.apache.sqoop.Sqoop.run(Sqoop.java:143)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
16/10/29 02:21:06 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: No columns to generate for ClassWriter
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1651)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:107)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:478)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605)
at org.apache.sqoop.Sqoop.run(Sqoop.java:143)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
解决方法如下:
mysql -u root -p
mysql>use mysql;
mysql>select host from user where user='root';
mysql>update user set host = '%' where user ='root';
mysql>flush privileges;
mysql>select host from user where user='root';
第一句是以权限用户root登录
第二句:选择mysql库
第三句:查看mysql库中的user表的host值(即可进行连接访问的主机/IP名称)
第四句:修改host值(以通配符%的内容增加主机/IP地址),当然也可以直接增加IP地址
第五句:刷新MySQL的系统权限相关表
第六句:再重新查看user表时,有修改。。
重起mysql服务即可完成。
4.1.3 设置NameNode和DataNode时间同步,有可能NameNode和DataNode的时间是不同步的,这样的话,在执行导入操作的时候会报如下的错误。
16/10/29 03:01:50 INFO mapreduce.Job: Job job_1477729967303_0001 failed with state FAILED due to: Application application_1477729967303_0001 failed 2 times due to Error launching appattempt_1477729967303_0001_000002. Got exception: org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1477736540684 found 1477735910751
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:152)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:122)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:249)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
. Failing the application.
解决方法如下:
我们的集群有6台设备,在每台设备上使用以下两条命令。有个问题是,在执行第二条命令的时候,我在没连网的情况下无法执行,但是在连网的情况下执行成功了!!下面是我在itcast01上执行的信息,注意要在其它设备上也执行一下。
[root@itcast01 ~]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? y
[root@itcast01 ~]# ntpdate pool.ntp.org
29 Oct 11:20:27 ntpdate[2800]: step time server 168.63.242.24 offset -28761.836642 sec
[root@itcast01 ~]#
4.1.4 下面我们便开始真正开始我们的导入功能即将数据库中的数据导入到HDFS系统。使用的命令如下红色字体的内容,我说一下命令各项参数的意思。
首先./sqoop是我们操作sqoop最常用的命令也是功能最强大的命令。接着,import是导入的意思,接着,--connect jdbc:mysql://169.254.254.1:3306意思是以jdbc的方式连接数据库,169.254.254.1是我们的Windows的IP地址(该IP可以和集群连通),3306是端口。接着,sqoop是我们Student表所在的数据库的名称。接着,--username root --password root 是指数据库的用户名和密码。接着,--table Student意思是我们要导的是Student表。
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --table Student
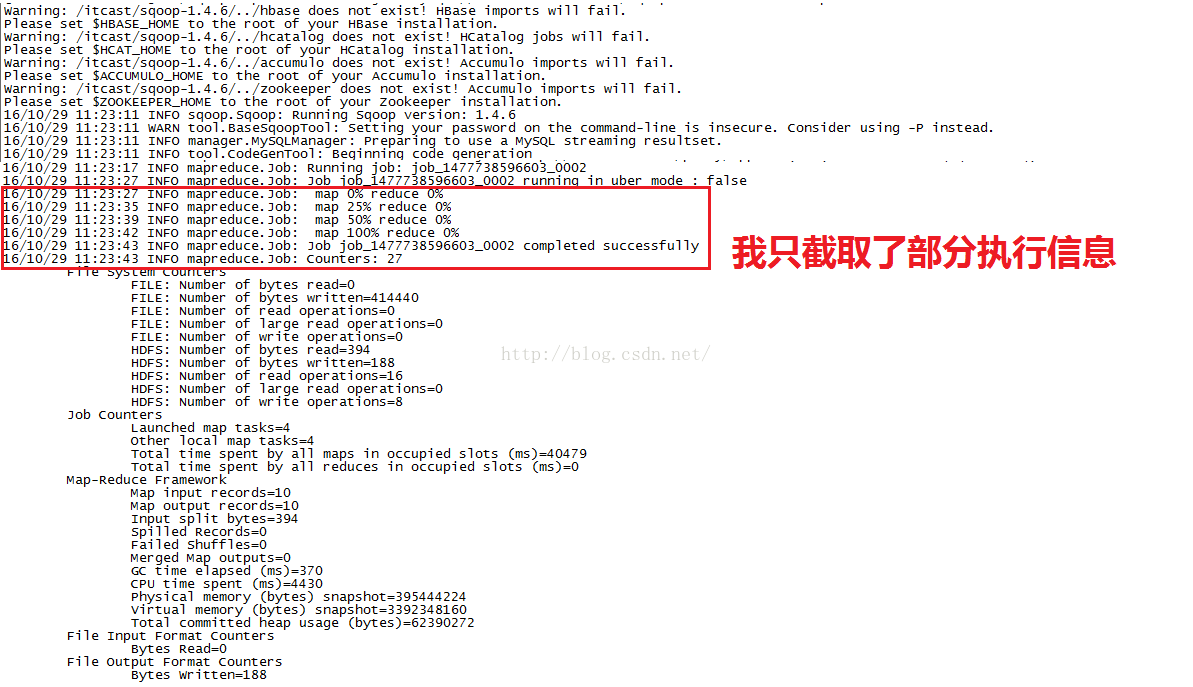
命令的执行信息如下图所示,看到红色圈住的信息时说明执行成功了,这里大家发现了没有,执行过程中只有map,reduce的进度始终是0%,说明导入功能根本就没用到reduce的功能,这个其实也好理解,我们是要把数据库中的数据导入到HDFS系统,只需要多台设备同时到数据库中去读取一条一条数据然后直接上传到HDFS,根本就不需要进行合并操作。如果是要计算很多数的和的话,就要用到reduce了,显然我们的导入功能用不到reduce。
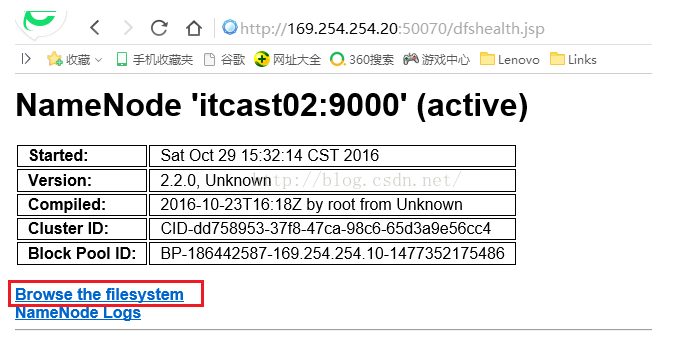
4.1.5 执行完了导入命令,我们到HDFS系统查看一下生成的结果。
我们到状态为active的namenode的HDFS界面,如下图所示,可以看到itcast02现在是active状态,我们点击"Browse the filesystem"。
点击上图的"Browse the filesystem"链接之后我们会进入到如下图所示的界面,由于我们在导入的时候没有指定要导入到HDFS的哪个目录,因此系统会自动帮我们存到一个地方,它自动存的目录在user文件夹下,如下图所示,我们点击"user"。
点击上图的"user"文件夹之后,我们会进入到如下图所示的界面,由于我们是以root的身份进行导入操作的,因此它自动帮我们生成了一个root文件夹,我们点击它。
点击上图的"root"文件夹之后,我们会进入到如下图所示的界面,我们导的是数据库中的Student表,因此这里生成了一个叫Student的文件夹,我们点击它。
点击上图的"Student"文件夹之后我们会键入到如下图所示的界面,可以看到有4个结果文件,也就是说使用了4个mapper来参与导入操作了,我们还发现文件的名字中中间都是"m",“m”代表的意思是mapper生成的文件,"r"代表的意思是reducer生成的文件。我们依次点开这四个文件,看看生成的结果是否正确。
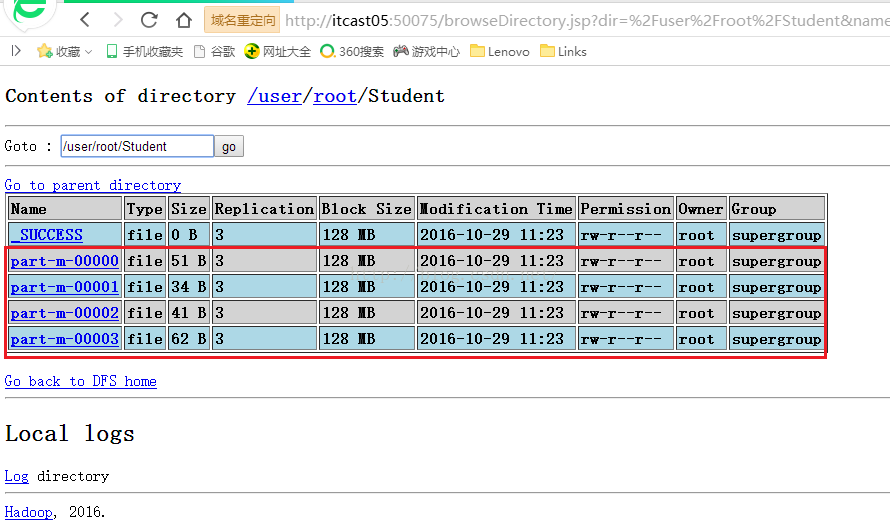
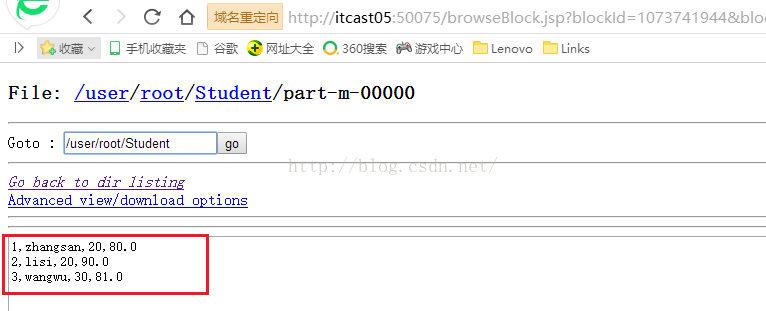
我们先看part-m-00000文件的内容,我们点击上图的"part-m-00000"链接,会看到如下图所示的内容,可以看到有三条数据信息,列与列之间默认是以","分隔的。
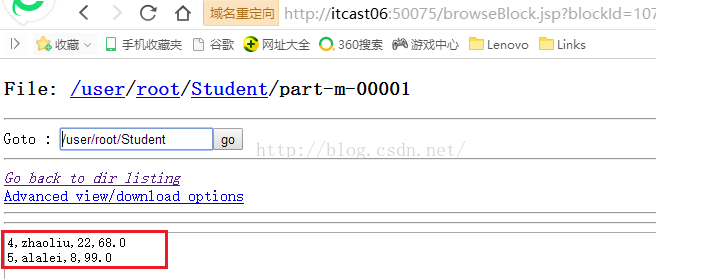
接着我们再来看part-m-00001文件的内容,如下图所示,这个文件承接上个文件,存储的是ID为4和5的两条记录。
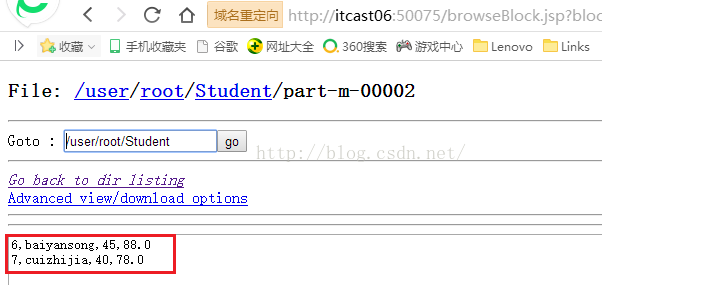
接着我们再来看看part-m-00002文件的内容,如下图所示,这个文件承接上个文件,存储的是ID为6和7的两条记录。
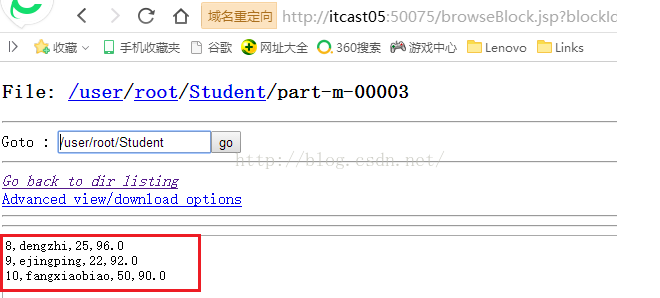
接着我们再来看看最后一个文件part-m-00003文件的内容,如下图所示,该文件承接上个文件,可以看到有ID为8、9、10的三条记录。从而可以得出结论,我们刚才的导入操作完全没问题。
4.2 我们上面以最简单的方式导入了一下数据,现在我们再多使用两个参数来进入导入操作,我们使用的命令如下,可以看到我们加了两个参数,--target-dir(指定要存放到服务器的哪个目录下)和-m(指定要起的mapper的数量,注意:m前面是一个"-",其它参数前面是两个"--",由于用不到reducer合并数据,因此起几个mapper就会生成几个文件。)
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --table Student--target-dir /sqoop/td1 -m 2
上面的命令执行完之后,我们到服务器上查看一下生成的结果,我们先到服务器根目录下,如下图所示,可以看到确实生成了sqoop文件夹,我们点击进入。
点击上图的sqoop链接之后,我们进入到如下图所示的界面,可以看到确实有我们刚才命名的td1文件夹,我们点击进入td1。
点击上图的td1链接之后,我们会看到如下图所示的界面,可以看到生成了两个结果文件part-m-00000和part-m-00001,这符合我们设置的参数-m 2的要求,我们具体看看这两个文件中的内容。
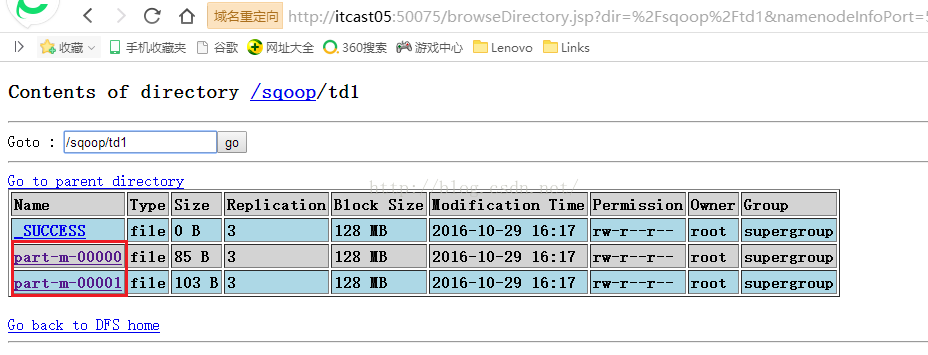
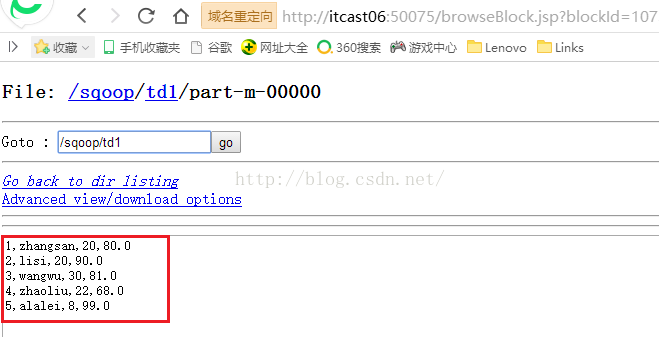
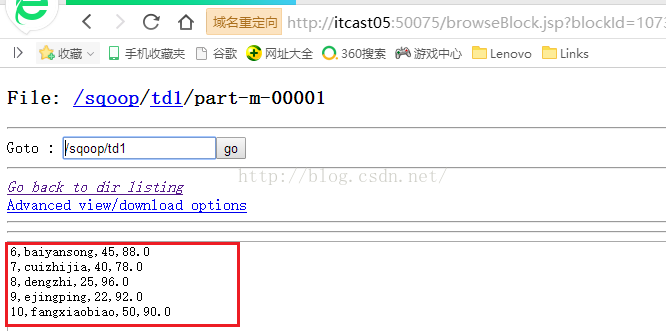
我们先看看part-m-00000文件中的内容,可以看到内容是ID从1到5的Student表中的数据。
接着我们再看看part-m-00001文件中的内容,可以看到这里面的内容是Student表ID从6到10的数据,也完全没问题!!!
4.3 我们接着来增加参数,--fields-terminated-by '\t'意思是指定列与列的分隔符为制表符,--columns 'ID,Name,Age'意思是我们要导入的只有ID、Name和Age这三列。如下所示
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --table Student --target-dir /sqoop/td2 -m 2--fields-terminated-by '\t' --columns 'ID,Name,Age'
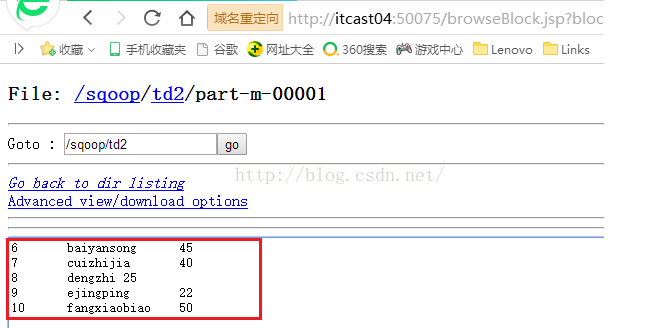
已经截的图很多了,我就不挨个截图了,直接看生成的part-m-00001文件的内容吧,如下图所示,可以看到列与列之间确实是用\t来分隔了。
4.4 我们现在来玩一个更高级的,我们使用where条件来筛选数据并导入符合条件的数据,增加的参数是--where 'ID>=3 and ID<=8',顾名思义,就是要把ID从3到8的数据导入到服务器。
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --table Student --target-dir /sqoop/td3 -m 2 --fields-terminated-by '\t' --columns 'ID,Name,Age'--where 'ID>=3 and ID<=8'
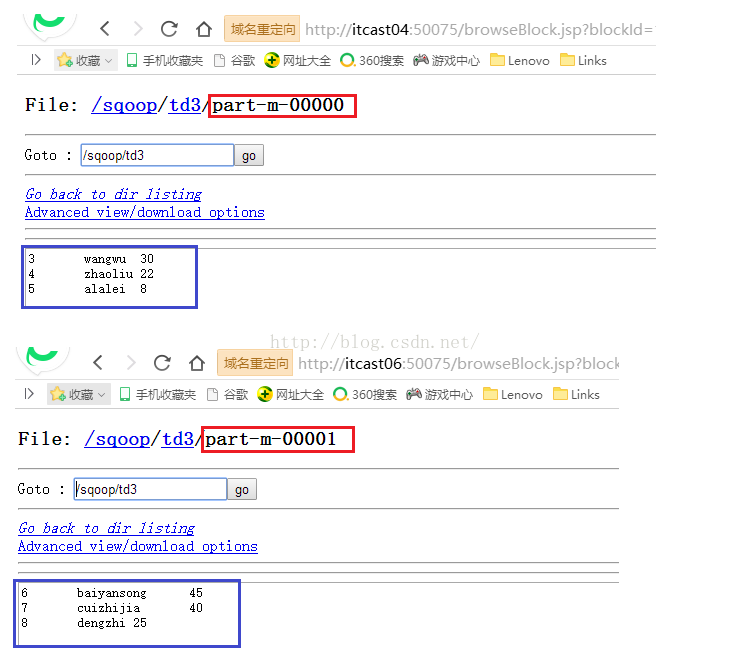
命令执行成功之后,我们来看看生成的两个文件的内容是否符合条件,如下图所示,发现完全符合我们的where条件。
4.5 接下来我们玩更高级一点的,我们使用query语句来筛选我们的数据,这意味着我们可以导入多张表的数据,我们还是来个简单的,命令如下。我们发现使用query语句的话,就不用指定table了,由于数量很少,现在我们指定mapper的数量为1。我们执行下面的命令,该命令目前有个问题。
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root--query 'select * from Student where ID>5'--target-dir /sqoop/td4-m 1 --fields-terminated-by '\t'
执行上面的命令会出现如下所示的错误信息:must contain '$CONDITIONS' in WHERE clause.的意思是在我们的query的where条件当中必须有$CONDITIONS'这个条件,这个条件就相当于一个占位符,动态接收传过来的参数,从而查询出符合条件的结果。
16/10/29 18:09:46 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: Query [select * from Student where ID>5]must contain '$CONDITIONS' in WHERE clause.
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:300)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1833)
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1645)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:107)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:478)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605)
at org.apache.sqoop.Sqoop.run(Sqoop.java:143)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
我们在上面的命令语句当中加上$CONDITIONS,如下所示。然后再执行,就可以执行成功。
[root@itcast03 bin]#./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --query 'select * from Student where ID>5 and $CONDITIONS'--target-dir /sqoop/td4 -m 1 --fields-terminated-by '\t'
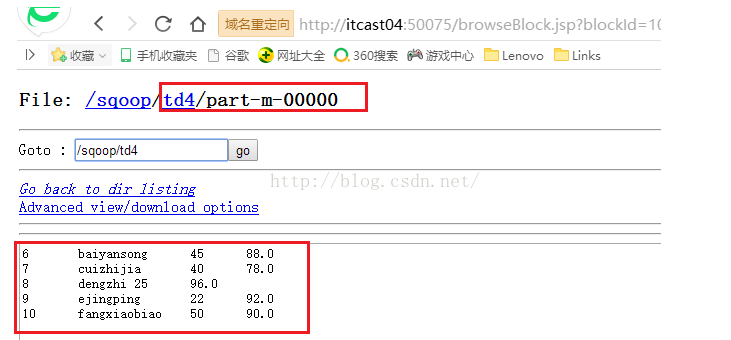
执行成功后,我们看看结果文件,如下图所示,发现确实导入的是ID从6到10的数据。
假如我们要把-m 1改成-m 2的话,导入操作会失败,我们来看一下命令执行及异常信息,如下所示。异常信息的意思是,我们没有指定mapper按什么规则来分割数据。即我这个mapper应该读取哪些数据,一个mapper的时候没有问题是因为它一个mapper就读取了所有数据,现在mapper的数量是2了,那么我第一个mapper读取多少数据,第二个mapper就读取第一个mapper剩下的数据,现在两个mapper缺少一个分割数据的条件,找一个唯一标识的一列作为分割条件,这样两个mapper便可以迅速知道表中一共有多少条数据,两者分别需要读取多少数据。
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --query 'select * from Student where ID>5 and $CONDITIONS' --target-dir /sqoop/td5-m 2 --fields-terminated-by '\t'
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
16/10/29 19:01:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
16/10/29 19:01:47 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
When importing query results in parallel, you must specify --split-by.
Try --help for usage instructions
知道了异常的原因,我们便加上分割数据的条件,我们使用的是Student表的ID字段。命令如下。
[root@itcast03 bin]# ./sqoop import --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --query 'select * from Student where ID>5 and $CONDITIONS' --target-dir /sqoop/td5 -m 2 --fields-terminated-by '\t' --split-by Student.ID
执行上面的命令,导入操作便可以成功。如下图所示。发现确实生成了两个文件,并且两个文件中的内容加起来刚好就是我们query中的条件ID>5。这里我们再详细说说$CONDITIONS'的作用,sqoop首先根据Student.ID将数据统计出来,然后传给$CONDITIONS',query语句就知道一共有多条数据了,假如第一个mapper读取了2条数据,那么也会把这个2传给$CONDITIONS,这样第二个mapper在读取数据的时候便可以根据第一个mapper读取的数量读取剩下的内容。
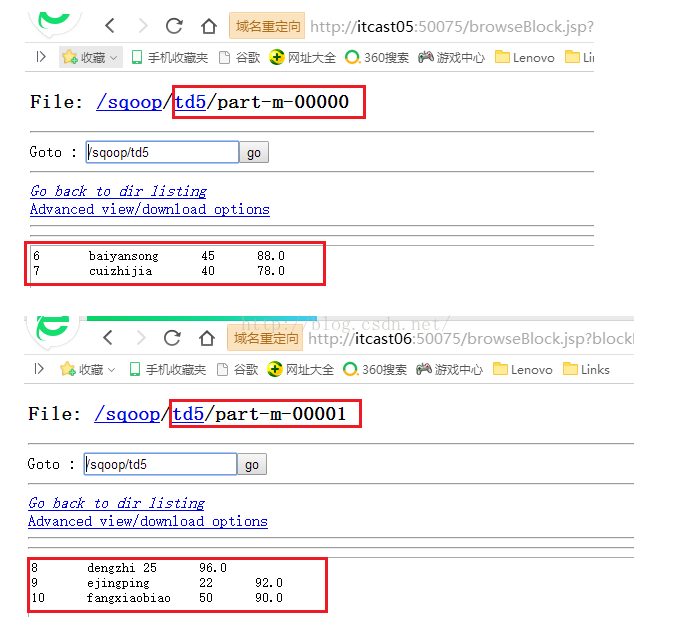
第五步:导出
我们把第四步最后导入的td5文件夹下两个文件的数据导出到数据库。
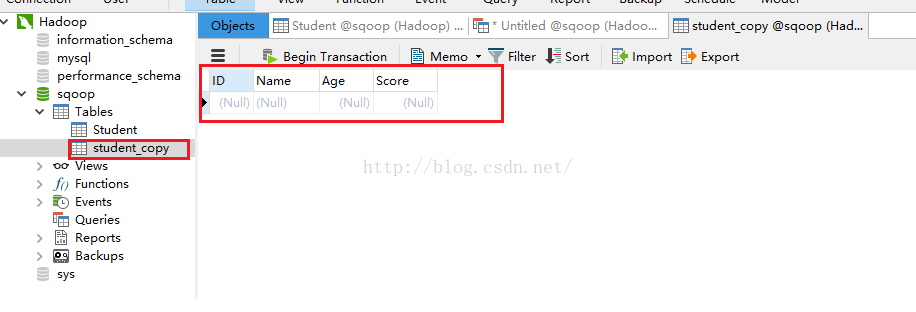
5.1 我们新建一个table表,这个table表和我们的Student表结构要一致,在mysql中有一个复制表的语句:create table student_copy like Student;这样我们便可以得到一张表结构和Student完全一样的表,如下图所示。
5.2 接下来我们便开始将服务器上的数据导出到数据库中,我们先来看一个错误的命令。
[root@itcast03 bin]# ./sqoop export --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --export-dir /sqoop/td5 -m 1 --table student_copy
错误信息如下:可以看到是数据转换出现了异常。那么是什么原因导致的呢,其实是列与列的分隔符导致的,td5下的两个文件中的数据是以"\t"来分隔的,而sqoop默认是以","来分隔的,因此出现了问题。
at student_copy.__loadFromFields(student_copy.java:335)
at student_copy.parse(student_copy.java:268)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by: java.lang.NumberFormatException: For input string: "6 baiyansong 45 88.0"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:492)
at java.lang.Integer.valueOf(Integer.java:582)
at student_copy.__loadFromFields(student_copy.java:317)
... 12 more
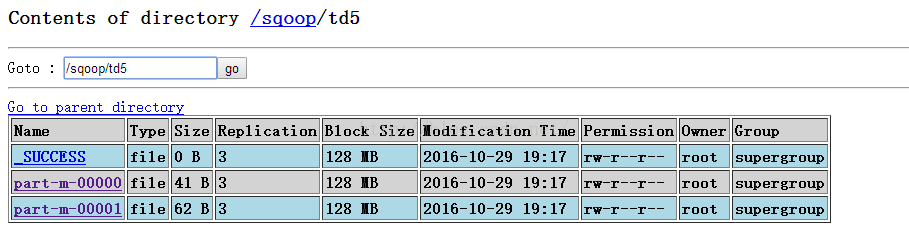
知道了问题,我们对症下药,人为指定分隔符--fields-terminated-by '\t',命令如下所示。这里说明一点的是,--export-dir /sqoop/td5这个参数有些人可能会有疑惑,因为td5文件夹下除了part-m-00000和part-m-00001两个结果文件外,还有一个名为“_SUCCESS”的文件,导出的时候会不会连这个文件的内容都导出去了呢?其实不会的,我们指定到文件夹,程序会去扫描这个文件夹下的所有文件,凡是不以"_"开头的文件都会被导出去,_SUCCESS文件是以“_”开头的,因此它不会被导出去,大家放心。
[root@itcast03 bin]#./sqoop export --connect jdbc:mysql://169.254.254.1:3306/sqoop --username root --password root --export-dir /sqoop/td5 -m 1 --table student_copy--fields-terminated-by '\t'
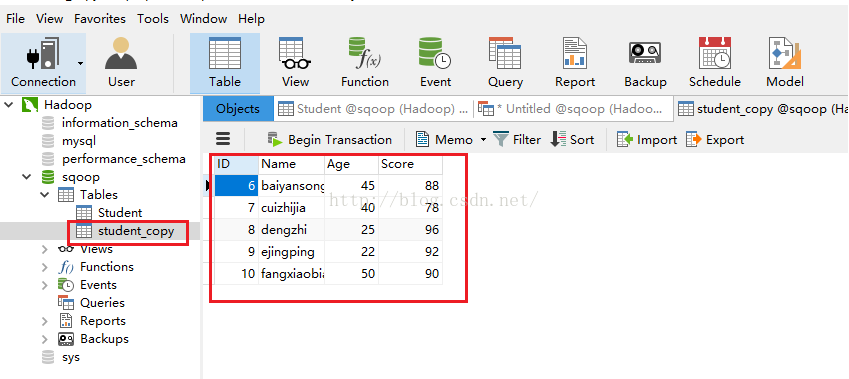
执行成功后我们看看我们刚才复制的student_copy表中是否有了我们导出的数据。发现确实导出到数据库5条数据,这5条数据也就是td5下面两个文件的内容,说明我们的导出功能也完全正常!!














 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









