







发生的场景:服务器端接收客户端请求的时候,一般需要进行签名验证,客户端IP限定等情况,在进行客户端IP限定的时候,需要首先获取该真实的IP。一般分为两种情况:
方式一、客户端未经过代理,直接访问服务器端(nginx,squid,haproxy);
方式二、客户端通过多级代理,最终到达服务器端(nginx,squid,haproxy);
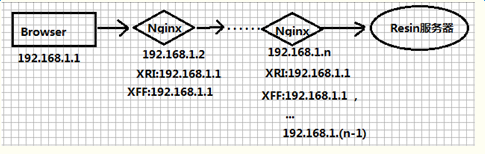
客户端请求信息都包含在HttpServletRequest中,可以通过方法getRemoteAddr()获得该客户端IP。此时如果在使用方式一形式,可以直接获得该客户端真实IP。而如果是方式二中通过代理的形式,此时经过多级反向的代理,通过方法getRemoteAddr()得不到客户端真实IP,可以通过x-forwarded-for获得转发后请求信息。当客户端请求被转发,IP将会追加在其后并以逗号隔开,例如:10.47.103.13,4.2.2.2,10.96.112.230。
请求中的参数:
request.getHeader("x-forwarded-for") : 10.47.103.13,4.2.2.2,10.96.112.230
request.getHeader("X-Real-IP") : 10.47.103.13
request.getRemoteAddr():10.96.112.230
客户端访问经过转发,IP将会追加在其后并以逗号隔开。最终准确的客户端信息为:
- x-forwarded-for 不为空,则为逗号前第一个IP ;
- X-Real-IP不为空,则为该IP ;
- 否则为getRemoteAddr() ;
代码示例:
@Slf4j
public class HttpRequestUtil {
private static final String NGINX_IP_HEADER = "X-Real-IP";
private static final String NGINX_URL_HEADER = "X-Real-Url";
private static final String NGINX_X_FORWARDED_FOR = "X-Forwarded-For";
/**
* 功能描述: 获取ip(兼容nginx转发)
*
* @param request
* @return
*/
public static String getRemoteIp(HttpServletRequest request) {
String ips = request.getHeader(NGINX_X_FORWARDED_FOR);
String[] ipArray = StringUtils.split(ips, ",");
if (ArrayUtils.isNotEmpty(ipArray)) {
return StringUtils.trim(ipArray[0]);
} else {
String ip = request.getHeader(NGINX_IP_HEADER);
if (StringUtils.isEmpty(ip)) {
ip = request.getRemoteAddr();
}
return ip;
}
}
/**
* 从request中抽取当前url(兼容nginx转发模式)
*
* @param request
* @return
* @see #NGINX_URL_HEADER
*/
public static String getRemoteUrl(HttpServletRequest request) {
/*if (checkParamNull(request)) {
return null;
}*/
String url = request.getHeader(NGINX_URL_HEADER);
if (StringUtils.isEmpty(url)) {
return request.getRequestURL().toString();
} else {
if (log.isDebugEnabled()) {
log.debug("NGINX_URL_HEADER:" + url);
}
return url;
}
}
/**
* 功能描述: <br>
* 获取hostname
*
* @param request
* @return
* @see [相关类/方法](可选)
* @since [产品/模块版本](可选)
*/
public static String getHostName(HttpServletRequest request) {
String host = request.getHeader("Host");
return host;
}
/**
* 获取用户代理
*/
public static String getUserAgent(HttpServletRequest request) {
String userAgent = request.getHeader("User-Agent");
return userAgent;
}
private static boolean checkParamNull(Object... params) {
for (Object param : params) {
if (null == param) {
log.error("Invalid Parameter.");
return true;
}
}
return false;
}
/**
* 获取格式化的URI
* @param request
* @return
*/
public static String getURIFormat(HttpServletRequest request) {
String uri = request.getRequestURI();
if("".equals(request.getContextPath())) {
uri = uri.substring(1);
}
if (StringUtils.isNotBlank(request.getQueryString())) {
uri += "?" + request.getQueryString();
}
return uri;
}
/**
* 获取请求method
* @param request
* @return
*/
public static String getRequestMethod(HttpServletRequest request) {
return request.getMethod();
}
/**
* 将cookie value封装到Map里面
* @param request
* @return
*/
public static Map<String, String> getCookieMap(HttpServletRequest request){
Map<String, String> cookieMap = Maps.newHashMap();
Cookie[] cookies = request.getCookies();
if(null != cookies){
for(Cookie cookie : cookies){
cookieMap.put(cookie.getName(), cookie.getValue());
}
}
return cookieMap;
}
}
此时,正常情况之下可以获取客户端真实的IP。需要注意的是对于服务器端采用负载的形式,需要配置保存x-forwarded-for。目前负载的形式有haproxy、nginx等形式。结构图如下:
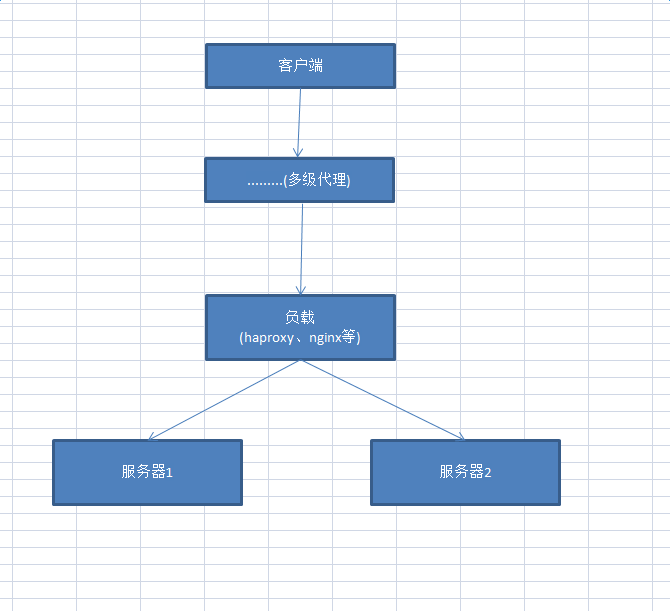
我接触的服务器端配置负载使用haproxy,相对于的配置如下:

frontend crmtest
bind :8081
mode http
option httplog
option forwardfor // 配置HAProxy会把客户端的IP信息发送给服务器,在HTTP请求中添加"X-Forwarded-For"字段。
default_backend drm
backend drm
mode http
option httplog
balance roundrobin
stick-table type ip size 200k expire 30m
stick on src
server jboss1 10.10.10.11:8081
server jboss2 10.10.10.12:8081
haproxy配置参考:http://www.cnblogs.com/dkblog/archive/2012/03/13/2393321.html














 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









