







简述:
读《Java解惑》 第10章 阅读笔记
谜题 86 添加括号导致的编译器错误
添加括号会产生编译期错误的情况
int, 或者long, 最小值的绝对值比正数绝对值要大1

添加了括号后

谜题 87 紧张的关系 “==” 符号的非自反性
Transitive.java
package com.anialy.test.java_puzzlers.chapter_10.紧张的关系_87;
public class Transitive {
public static void main(String[] args) {
long x = Long.MAX_VALUE;
double y = (double) Long.MAX_VALUE;
long z = Long.MAX_VALUE - 1;
System.out.println("x == y : " + (x == y));
System.out.println("y == z : " + (y == z));
System.out.println("x == z : " + (x == z));
System.out.println("Float.NaN == Float.NaN : " + (Float.NaN == Float.NaN));
}
}
输出:
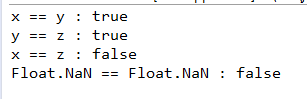
谜题 88 原始类型的处理
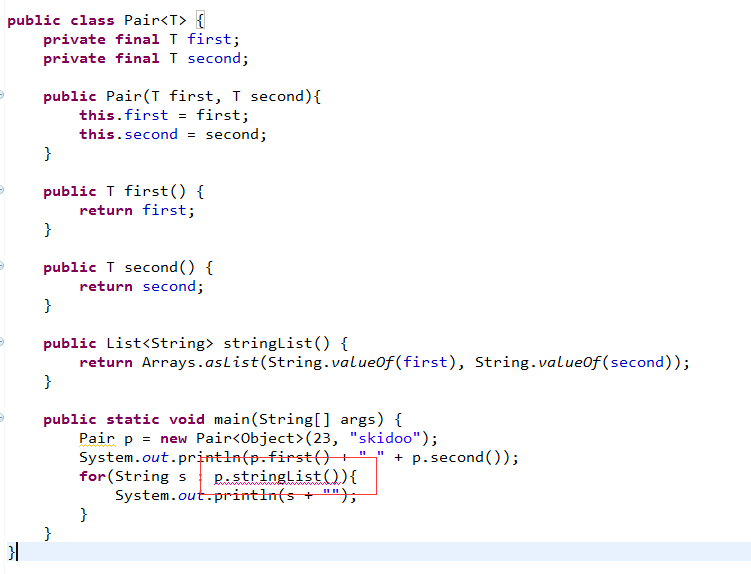
程序中的p是属于原始类型Pair的,所以它的所有实例方法都要执行这种擦除。在一个实例方法声明中出现的每个参数化的类型都要被其对应的原始部分所取代。我们程序中的变量p是属于原始类型pair的,所以它的所有实例方法都要执行这种擦除。
谜题 89 泛型迷药,外围类和内部类使用相同的类型参数名
首先看这样一段代码

run之后报错信息如下,

说明:
避免内部类遮蔽外部类的类型参数名字,一个泛型的内部类可以访问到他的外围类的类型参数
优化:
优先使用静态成员类而不是非静态成员类,LinkedList.Node的一个实例不仅含有value和next字段,还有一个隐藏的字段,包含对外围的LinkedList实例的引用。虽然外部类的实例在实例在构造阶段会被用来读取和修改head,但是一旦构造完成,它就变成一个甩不掉的包袱。
使用static修饰Node之后的代码
package com.anialy.test.java_puzzlers.chapter_10.泛型迷药_89;
public class LinkedList<E> {
private Node<E> head;
private static class Node<T> {
T value;
Node<T> next;
Node(T value, Node<T> next) {
this.value = value;
this.next = next;
}
}
public void add(E e){
head = new Node<E>(e, head);
}
public void dump(){
for(Node<E> n = head; n != null; n = n.next){
System.out.println(n.value + ", ");
}
}
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>();
list.add("world");
list.add("Hello");
list.dump();
}
}
谜题90 荒谬痛苦的超类 引用外层类super函数的问题

编译后就不通过,原因如下:
要想实例化一个内部类,入Inner1, 需要提供一个外围类的实例给构造器。一般情况下,它是隐式传递给构造器的,但是它也可以以exception.super(args)的方式通过超类构造器调用。如果外围类实例是隐式传递的,编译器会自动产生表达式:它使用this来指代最内部的超类是一个成员变量的外围类。在本例中,那个超类就是Inner1.因为当前类Inner2间接扩展了Outer类,Inner1便是他的一个继承而来的成员。
显示传递合理的外围类实例:
但是这个成员类真的需要使用外围类实例?如果答案是否定的,那么应该把它设为静态成员类
尽量使用静态嵌套类而少用非静态的。
谜题 91 序列杀手 序列化过程中,调用序列化对象的方法,由于状态不一致导致的问题
SerialKiller.java
package com.anialy.test.java_puzzlers.chapter_10.序列杀手_91;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerialKiller {
public static void main(String[] args){
Sub sub = new Sub(666);
sub.checkInvariant();
Sub copy = (Sub)deepCopy(sub);
copy.checkInvariant();
}
public static Object deepCopy(Object obj){
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
new ObjectOutputStream(bos).writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bos.toByteArray());
return new ObjectInputStream(bin).readObject();
} catch(Exception e) {
throw new IllegalArgumentException();
}
}
}
Sub.java
package com.anialy.test.java_puzzlers.chapter_10.序列杀手_91;
public class Sub extends Super {
private int id;
public Sub(int id){
this.id = id;
set.add(this);
}
@Override
public int hashCode (){
return id;
}
@Override
public boolean equals(Object o){
return (o instanceof Sub) && (id == ((Sub)o).id);
}
public void checkInvariant(){
if(!set.contains(this)){
throw new AssertionError("invariant violated");
}
}
}
Super.java
package com.anialy.test.java_puzzlers.chapter_10.序列杀手_91;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
public class Super implements Serializable {
final Set<Super> set = new HashSet<Super>();
}
运行后输出:

说明:
HashSet类有一个readObject方法,它创建一个空的HashMap,并且使用HashMap的put方法,针对集合中的每个元素在HashMa中插入的一个键-值对。put方法会调用键的hashCode方法以确定它所在的单元格。三列映射表中唯一的键就是Sub的实例,而它的set字段正在被反序列化。这个实例的子类字段,即id,尚未被初始化,所以它的值为0,即所有int字段的默认初始值,Sub的hashCode方法将返回这个值,而不是最后保存在这个字段中的值666.因为hashCode返回了错误的值,相应的键-值对条目将会放入错误的单元格中。当id被初始化为666时,一切都太迟了。当Sub实例在HashMap中的时候,改变这个字段的值就会破坏这个字段,进而破坏HashSet,破坏Sub实例。
关键点:
1. 如果一个HashSet、Hashtable或HashMap被序列化,那么请确认它们的内容没有直接或间接地引用它们自身。
2. 在readObject或readResolve方法中,请避免直接或间接地在正在进行反序列化的对象上调用任何方法
谜题 92 私有成员变量不会继承
Twisted.java
package com.anialy.test.java_puzzlers.chapter_10.双绞线_92;
public class Twisted {
private String name;
public Twisted(String name) {
this.name = name;
}
private void reproduce(){
new Twisted("reproduce"){
void printName() {
System.out.println(name);
}
}.printName();
}
public static void main(String[] args) {
new Twisted("main").reproduce();
}
}输出:
说明:
私有成员不会被继承,所以在这个程序中,name方法并没有被继承到reproduce方法中的匿名类中。所以,匿名类中对name的取值就只能关联到到外围(“main")实例而不是当前("reproduced")实例。这就是最小闭合作用域。















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









