



1)需求背景说得很好。
计算技术的不断更新使计算机体系结构的发展日新月异,计算机体系结构经历着从同
构计算模式到异构计算模式的转变,不同处理器厂商之间在体系结构和编程模型方面的巨
大差异给计算系统的应用推广带来巨大挑战。利用编译技术自动将串行程序转换为异构并
行程序是解决这个问题的一种有效手段。基于多面体模型的编译技术被认为是程序自动并
行化领域的一个研究热点。
2)三个方面的研究成果
(1) 以提升程序并行性和数据局部性为目标,本文研究了多面体编译优化的原理及流
程,分析了多面体模型的主要特点,给出了利用多面体模型进行编译优化的主要途径。与
传统的幺模矩阵模型相比,多面体模型具有更广泛的应用范围、更强大的表示能力和更全
面的优化空间,同时也存在抽象层次高、实现难度大等问题。为了全面深入的了解多面体
模型,本文分析了多面体模型的原理和基于多面体模型的编译流程,深入研究了多面体模
型最核心的调度变换算法,给出了利用多面体模型提升程序并行性和数据局部性的主要方
法。
(2) 为了发掘数据局部性和提升块间并行性,本文提出一种面向通用多核同构架构的
循环分块算法。循环分块是提升多级缓存数据局部性最有效的循环变换技术。多面体模型
实现了简单的平行四边形分块,但这种分块方法无法有效进行分块之间的并行。为了解决
循环分块的块间并行问题,衍生出分裂分块、钻石分块、六角形分块等复杂的分块形状。
其中,钻石分块、六角形分块已经在多面体编译器中得到实现,但分裂分块由于设计复杂,
目前尚无有效的算法和实现。本文设计了一种基于平行四边形的分裂分块算法,避免了传
统分裂分块依赖非仿射表达式的问题,并在PPCG 编译器中对该算法进行了实现。实验对
不同类型的stencil 计算进行测试,结果表明,PPCG 编译器采用本文提出的算法生成的
OpenMP 并行代码相较于当前效果最好的钻石分块算法生成的代码有2%的性能提升;相
较于stencil 领域专用编译器Pochoir 生成的代码有91%的性能提升。
设计了新型算法,在PPCG中实现了。
(3) 为了生成面向异构系统的并行代码,同时降低同步开销,本文提出一种面向GPU
架构的循环分块算法。钻石分块仅实现CPU 上的代码生成,六角形分块仅支持面向GPU
架构的代码生成,当面向不同架构时,为了达到最优的性能,需要采用不同的循环分块算
法;同时,复杂分块形状提升块间并行性必然以额外的同步开销为代价,频繁的同步大大
降低了程序整体性能。本文在面向CPU 架构分裂分块算法的基础上,在PPCG 编译器实
现了分块后循环层到GPU 硬件层的映射,同时实现同步最小化功能。与钻石分块相比,
本文提出的算法支持各个维度分块大小不同的情况;与六角形分块相比,本文提出的算法
能够处理多条语句、符号常量循环边界等多种复杂情况。实验对不同类型的stencil 计算
进行测试,结果表明,PPCG 采用本文提出的算法生成的CUDA 代码相较于当前应用最
广泛的六角形分块生成的代码有64%的性能提升。
做了什么说得很清楚 ,博士水平就不一样。
(4) 为了充分利用大规模并行资源,本文提出一种面向硬件并行规模的循环多维并行
识别方法。随着现代处理器架构核心数目的不断增长,传统的单维并行识别方法难以提供
足够的并行度,本文提出面向硬件并行规模的循环多维并行识别方法。根据并行层迭代次
数和目标平台硬件资源数之间的关系,动态识别嵌套循环的多个维度为并行层,将多个并
行维度的迭代空间合并后再作任务划分,以达到充分利用目标平台硬件资源的目的。该方
法在PPCG 中进行实现,通过对矩阵乘法、laplace 方程等核心计算程序进行测试,结果
表明,本文提出的方法相较于现有单维并行方法,在SW26010 异构众核处理器上性能提
升最高达1.8 倍,在Nvidia Tesla V100 平台性能提升最高达5.2 倍。
循环识别方法。
3)循环识别好说
循环展开,需要对代码中所有变量进行识别,其实也还好。
但是循环分块确实没有想到好方法。可能多面体有自己的一套逻辑。
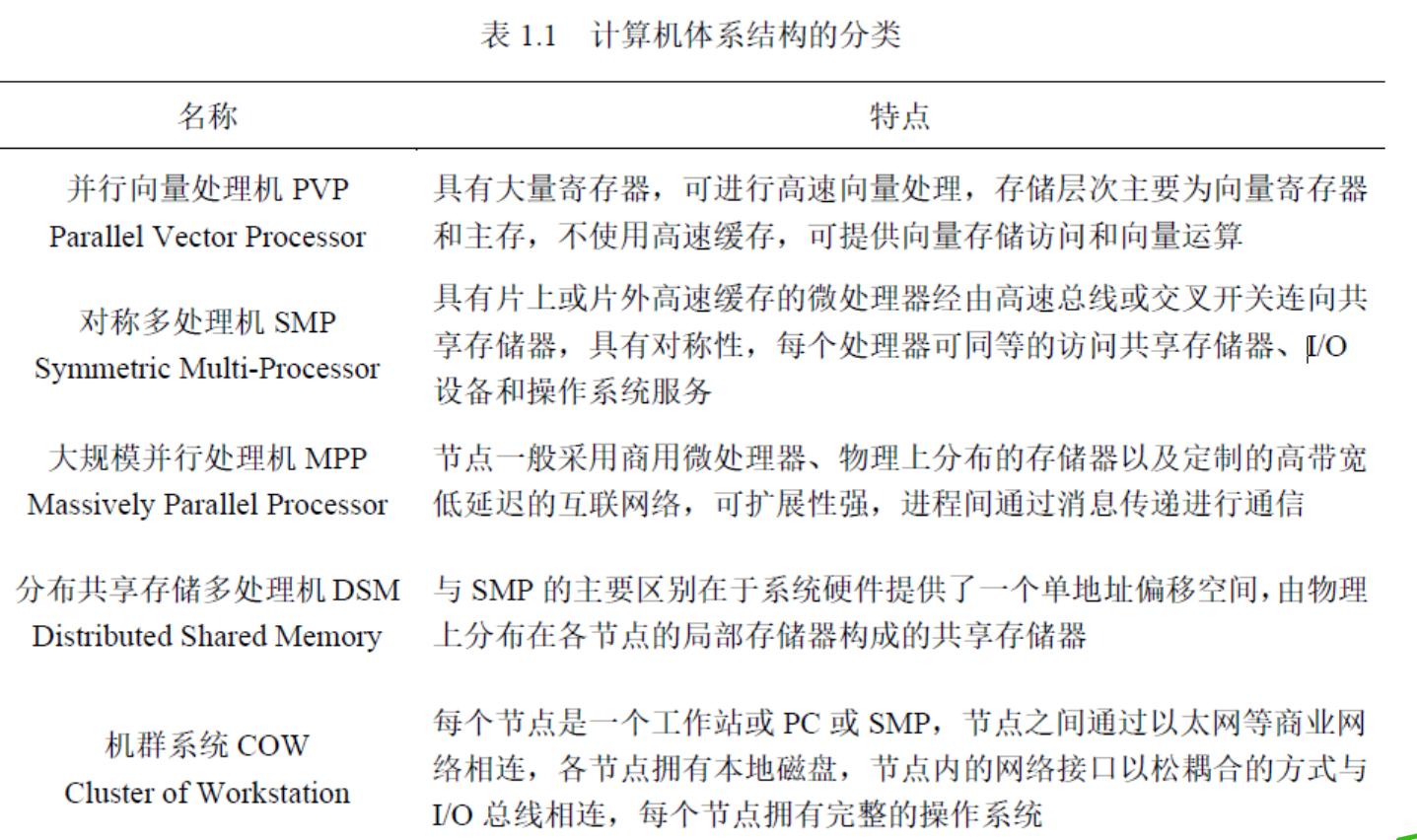
4)计算机体系结构的分类,这个分类也挺好的。
5)自动编译工具[8][9]通过检测串行程序中所蕴含的潜在并行性,实现从串行程序到等价
并行程序的自动转换
自动编译有自己的问题。
国际上针对异构系统的并行编译优化技术展开了大量研究,Par4All[10]是该领域最具
有代表性的工具之一。
6)市场前景好
法国巴黎高等师范学院(École normale supérieure)和法国国家信息与自动化研究所
(INRIA)共同领导下的PARKAS 实验室是多面体模型研究的发源地之一,该研究团队
在学术带头人Albert Cohen 的带领下,从2017 年开始与Facebook 和MIT 合作开发出面
向通用GPU 的深度学习编译器TensorComprehensions[19],
Pluto 编译器[21]
的主要开发者和维护者Uday Bondhugula 也以访问学者身份到谷歌大脑团队从事该领域
的研究。
市场很认可啊
——很久没搞了 读博士的时候研究过 什么通信优化 负载均衡 我当时做的是不规则的
学校研究工作最大的问题是,会走在时代前沿,但是会疯狂换方向
7)面向异构系统的多面体编译工具借助其强大的循环变换和优化能力,从面向异构系统
编译的各个方面进行了深入的研究并取得了许多进展,这些编译工具包括C-to-CUDA[22]、
PoCC[23]、Pluto[24]、CHiLL[25]、PPCG[26]等。与此同时,GCC、Open64、LLVM[27]和IBM
XL 等主流编译器也增加了对多面体模型的支持。因此,利用多面体模型处理面向异构系
统的代码生成具备巨大的潜力。
——同构芯片的性能优化都JB没有搞明白
8)当然,多面体模型的研究涉及各个方向,但就面向异构系统的编译技术来讲,主要包括程序分析、调度理论和代码生成三个部分。
(1) 程序分析。依赖关系分析是并行化领域程序变换的关键,多面体模型分析程序的
粒度是循环的某一次迭代,数组的一个元素,或语句在循环迭代中的一个实例。因此,多
面体模型中的依赖关系分析是根据依赖关系的定义计算出语句实例之间的依赖关系。多面
体模型的重点并不是强化依赖关系分析能力,而是利用依赖关系分析的结果来支撑模型上
强大的程序变换[24][28][29][30]。
(2) 调度理论。基于多面体模型的编译工具在收集依赖关系之后,需要借助特定的调
度表示和调度变换算法来生成适于在异构系统上运行的代码。程序的调度表示是多面体模
型的关键,一些早期的调度表示仅通过简单的迭代区间编码来定义语句的执行先后顺序
[30],这些方法只是作为某种调度变换算法的输入或输出,因此不能作为一种通用的调度
表示方式。Verdoolaege 指出程序的调度在本质上是树形结构[31],因此在多面体编译器
PPCG 中实现了一种调度树表示并将其作为一种通用的调度表示方式。调度树的优势是可
以引入新的节点来对程序的调度进行维护和修改,这为后续代码生成提供了方便。在调度
表示上实施调度变换算法之后,可以将输入的调度变换为具有更多并行性的调度并输出。
异构系统上加速部件的存储延迟是阻碍异构系统上程序性能的一个关键因素,因此多
面体模型调度算法的一个重要研究内容是提高程序在加速部件上的局部性。在多面体编译
工具上该部分的研究内容则体现在对循环分块变换的研究上,如Diamond 等分块技术
[32][33][34]。
(3) 代码生成。多面体编译工具通过调度变换算法,最终将调度表示转换为语法树表
示,并通过扫描语法树来生成最终的代码。多面体编译工具的代码生成分为基于参数多面
体的代码生成技术[35][36]和基于Presburger 关系的代码生成技术[37][38]。Tobias 等人[39]基于
调度树表示实现的代码生成算法则是在一个基于Presburger 关系的库上利用文献[35][36]
中的算法来扫描循环层。多面体模型的代码生成后端可以很方便地扩展到其它应用领域,
如北京大学高能效计算与应用中心的研究团队利用多面体代码生成技术来支持高层次综
合应用[40]。


















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









