









在人工智能的学习过程中,偏差会以多种不同的形式出现在机器学习中。
Bias的定义
Bias:“对某人或某一群体的倾向或偏见,尤指被认为不公平的方式”。
Bias被解释为偏差也可解释为偏见,其定义包括“不公平”一词。
偏差几乎可以在每个阶段影响机器学习系统。
举个例子💁,来说明我们周围世界的偏差是如何潜入你的数据的:
想象一下,我们正在构建一个模型来预测文本序列中的下一个单词。为了确保你有大量的训练数据,你把过去50年里写的每一本书都给了它。然后你让它预测这句话中的下一个单词:
“The CEOs name is ____”.
你会发现,你的模型更可能预测CEO的姓名是个男性姓名,而不是女性姓名。这种情况就是你无意中将我们社会中存在的历史刻板印象融入到你的模型中。
偏差不仅仅出现在数据中,它也可能出现在模型中。如果用于测试模型的数据不能准确地代表现实世界,最后就会得到所谓的评估偏差。
训练面部识别的例子就能够说明这个情况:
我们使用来自Instagram的照片进行测试。我们的模型在测试集上可能具有非常高的准确率,但在现实世界中就可能表现不佳。
因为大多数Instagram用户的年龄在18到35岁之间(甚至经过了强大的美颜功能)。你的模型现在偏向于那个年龄组,所以在现实生活中老年人和青少年的脸上表现得很差。
“bias”这个词字面意思有极强的负面含义,但在机器学习中并非总是如此。事先了解您要解决的问题可以帮助您在建模期间选择相关特征。这会引入人为偏见,但通常可以加快或改进建模过程。
讲到这里也许你会发现,训练机器学习模型很像抚养孩子。
为什么这样说?
因为人在成长过程中是通过使用听觉、视觉和触觉等感官来向周围的世界学习。个人对世界的理解,形成的观点,以及遇事做出的决定都与成长种所受到的影响有关。例如,一个在性别歧视社区长大和生活的孩子可能永远不会意识到他们看待不同性别的方式存在任何偏见,这与有偏差的机器学习模型完全相同。
在训练时我们不是使用感官作为输入,而是使用数据——我们提供给他们的数据! 这就是为什么在用于训练机器学习模型的数据中尽量避免偏差是如此重要。
下面详细说明机器学习中一些最常见的偏差形式:
历史偏差
在收集用于训练机器学习算法的数据时,抓取历史数据几乎总是最容易开始的地方。但是,如果我们不小心,很容易将历史数据中存在的偏差包括在内。
亚马逊有一个非常典型的例子:
2014年,亚马逊曾着手建立一个自动筛选求职者的系统。当时的想法是,向系统输入数百份简历,让系统自动挑选出最优秀的候选人。该系统是根据10年的工作申请及其结果进行培训的。
出现了什么问题呢?
亚马逊的大多数员工都是男性(尤其是在技术岗位上)。该算法了解到,由于亚马逊的男性比女性多,男性更适合应聘者,因此对非男性应聘者积极歧视。因为偏差,算法虽然“聪明”但也让人哭笑不得。
样本偏差
当训练数据不能准确反映模型在现实世界中的使用情况时,就会发生样本偏差。原因通常是,一个群体的代表性要么严重过高,要么代表性不足。
David Keene他给出了一个很好的样本偏差示例。
在训练语音到文本系统时,需要大量音频剪辑及其相应的转录。哪里比有声读物更能获得大量此类数据?这种方法有什么问题?
事实证明,绝大多数有声读物都是由受过良好教育的中年白人男性讲述的。不出所料,当用户来自不同的社会经济或种族背景时,使用这种方法训练的语音识别软件表现不佳。
由此我们可以发现,在考虑实际问题时应该切合实际生活场景,训练模型所使用的数据也一样,应该更多地考虑实际生活场景,更多地源于实际生活产出。
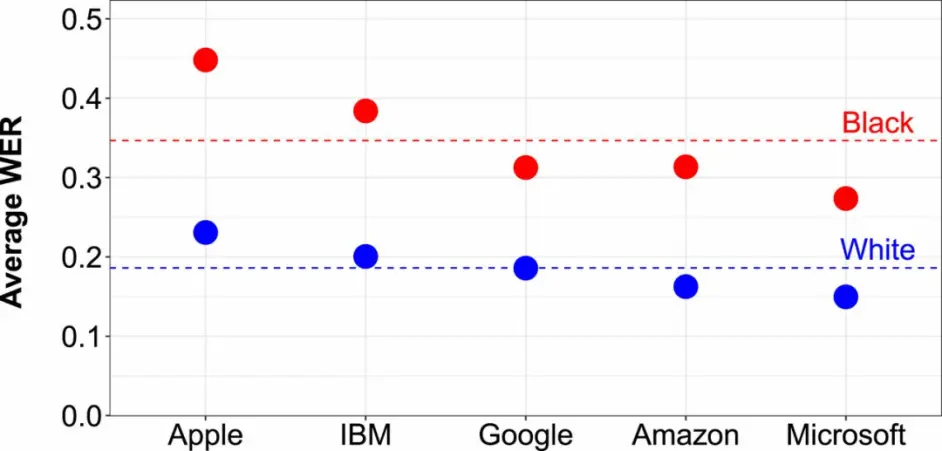
上图显示了大型科技公司语音识别系统的单词错误率 [WER]。可以清楚地看到所有算法在处理黑人语音和白人语音时都表现不佳。
标签偏差
训练ML算法所需的大量数据需要标记才能有用。
当你登录网站的时候你可能经常会被要求识别有红绿灯的广场。实际上,您是在为该图像确认一组标签,以帮助训练视觉识别模型。然而,我们给数据贴标签的方式千差百别,贴标签的不一致会给系统带来偏差。

想象一下,我们正在用上图中的框标记狮子来训练系统。然后,给系统显示此图像:

你会发现它无法识别图片中非常明显的狮子。通过仅标记面孔,在无意中把系统训练成偏向于正面狮子图片。
聚合偏差
有时我们聚合数据用以简化它,或以特定的方式呈现它。无论是在创建模型之前还是之后,这都会导致偏差。看看这个图表:
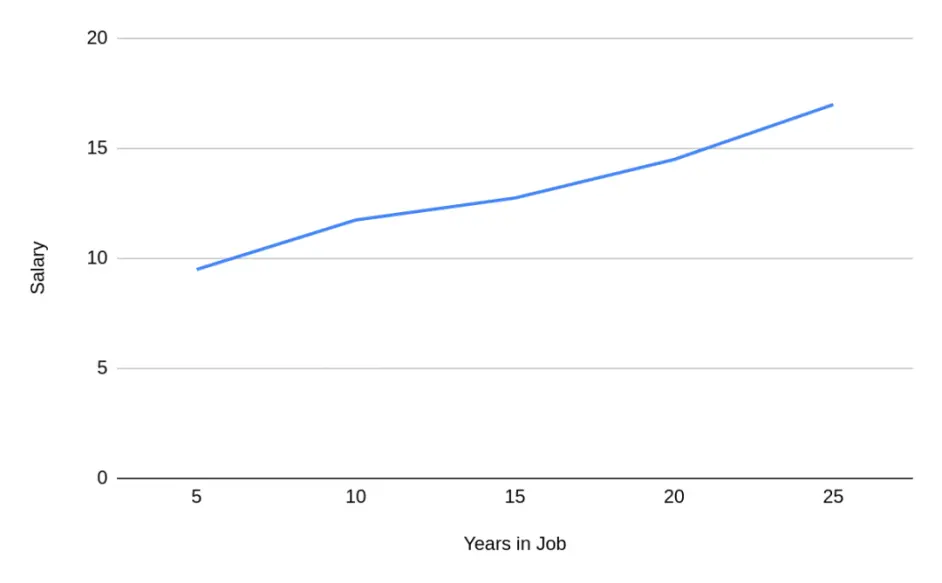
它显示了工资如何根据工作年数增加。这里有一个非常强的相关性,你工作的时间越长,你得到的报酬就越多。现在让我们看看用于创建此聚合的数据:
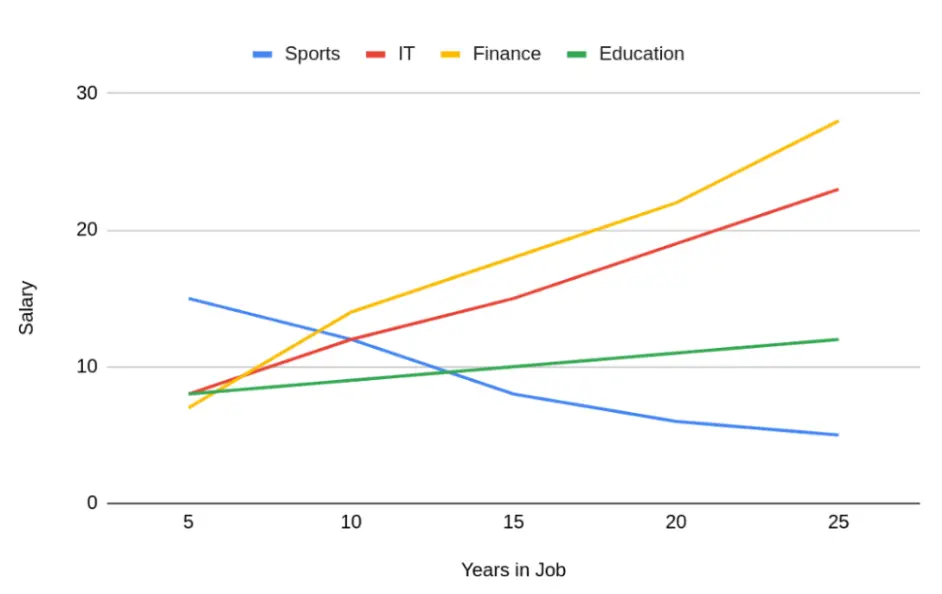
我们看到,对于运动员来说,情况恰恰相反。他们能够在职业生涯的早期获得高薪,而他们仍处于身体巅峰状态,但随着他们停止竞争,薪水就会下降。通过将他们与其他职业合并,我们的算法会对他们产生偏见。
确认偏差
简而言之,确认偏差是我们倾向于相信能证实我们现有信念的信息或丢弃不符合我们现有信念的信息。从理论上讲,我可以构建最精确的ML系统,在数据或模型上都没有偏差,但如果你打算根据自己的“直觉”改变结果,那么这也没关系。
确认偏差在机器学习应用中尤为普遍,在这些应用中,在采取任何行动之前都需要人工审查。人工智能在医疗保健中的使用让医生对算法诊断不屑一顾,因为它与他们自己的经验或理解不符。
通常在研究病例时,因为医生们没有阅读最新的研究文献,做出的判断同这些文献指出症状、技术或诊断结果略有不同。
所以一名医生可以阅读的研究期刊数量有限(尤其是在全职挽救生命的情况下),但机器学习系统可以将它们全部收录。
评价偏差
举一个不是很恰当的栗子。
假设我们正在构建一个机器学习模型来预测综艺比赛期间全国的投票率。我们通过采用年龄、职业、收入和喜好标签等一系列特征,准确预测某人是否会投票。然后构建了模型,使用最常见的投票方式对其进行了测试,得到了满意的结果,看起来好像成功了。
等投票结束,最后你发现你花了很长时间设计和测试的模型只有55%的时间是正确的——性能只比随机猜测好一点。这个糟糕的结果就是评估偏差的一个例子。
通过仅用一种投票方式评估模型,无意中设计了一个只对他们有效的系统。但是这次比赛投票模式还有其他好几种,我们没有考虑进去,即使它已经包含我们初始训练数据中的投票方式。
总结
本文讲解了偏差影响机器学习的六种不同情况,能够有助于与大家理解机器学习中很好地理解ML系统出现偏差的常见方式。
文章来源:
https://pub.towardsai.net/6-types-of-ai-bias-everyone-should-know-e72b2259cb1a


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









