






-------不动脑子的我仿佛一个筛子---------
索引
(自己查了搞出来和最后看了题解还是不一样的)
当然这些可能都是套路最后就没什么意思了.....


以及在"前女友"后面的东西
[flag在index里]
stristr(不区分大小写): 查找 "world" 在 "Hello world!" 中的第一次出现,并返回字符串的剩余部分:
大概看了一下 是php协议里面有关文件包含的漏洞
学习网站: https://blog.csdn.net/fageweiketang/article/details/80699051 (可是我看不太懂qaq)
构造网址: http://120.24.86.145:8005/post/index.php?file=php://filter/read=convert.base64-encode/resource=index.php
file=php://filter/read=convert.base64-encode/resource=,.....
(一个read 一个resource
[最后是== 哦 base64编码非常常见了] (发现可以直接用御剑解密qaq)
还真是在index里哇_)()
[备份是个好习惯]
【md5解密网址: https://www.cmd5.com/(看起来还挺厉害)】 地址在这 https://coding.net/u/yihangwang/p/SourceLeakHacker/git
后台备份。我下载到了王一航dalao的工具 但是python里面有不一样 稍微改用了一下print () 就可以扫描后台的备份文件啦
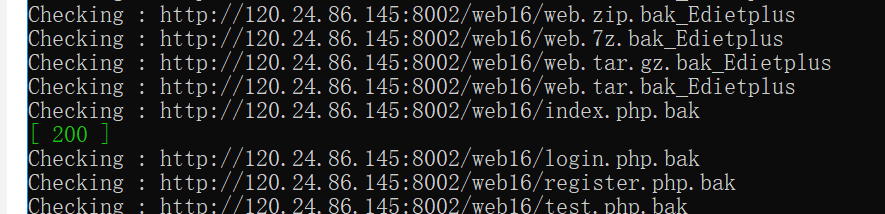
使用的时候先cd切换到目录下面 再运行这个文件就可以啦
记得要后面加上网址哦(http开头的!) (其实完全用脚本就行.... qaq)打开文件 Index.php.bak 注意是bak....

后面的(1)str_replace 用kekeyy双写绕过
(2)
if(md5($key1) == md5($key2) && $key1 !== $key2)
{
echo $flag."取得flag";
}
本身不一样, ,加密了之后一样了,这个是典型的php漏洞哦,构造数组(都返回null给了flag),或者是0e会被认为科学计数法,后面都是0
下列的字符串的MD5值都是0e开头的:
QNKCDZO
240610708
s878926199a
s155964671a
s214587387a
s214587387a
这里参考了https://blog.csdn.net/zpy1998zpy/article/details/80582974
经过试验 http://120.24.86.145:8002/web16/?kekeyy1[]=2&kekeyy2[]=4可行
【注意 】【构造的时候要使用“?” 而且是kekeyy1 kekeyy2】
$str = strstr($_SERVER['REQUEST_URI'], '?');
$str = substr($str,1);
$str = str_replace('key','',$str);
分析三句话: strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回str2在str1中首次出现的地址;否则,返回NULL (那么,这个我们的url肯定是?的子串,那么str存的就是哪个地址)
stristr() 函数查找字符串在另一个字符串中第一次出现的位置。(不区分大小写)
substr() 方法可在字符串中抽取从 start 下标开始的指定数目的字符。 (就是把他们都抽取过来啦)
str_replace() 把字符串 "Hello world!" 中的字符 "world" 替换为 "Shanghai": (把3种的1替换成2) 那么这里就是把str(提取到的一大串)里面的key替换成""咯,那么我们写两个咯kekeyy kkeyey都可以
然后我们知道变量的名字必须是key1 所以这样应对就好啦
<?php
echo str_replace("world","Shanghai","Hello world!");
?>
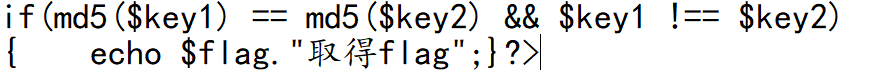
[成绩单]
怎么变成这样格式了....
数据库...
[秋山名老司机]
【我可以做什么?】
【完全观察网页 观察源代码 url 抓包 构造表达式 刷新】(刷新)
【所有一些可能都是给到的提示。。。。】
刷新发现网页计算在变化 python交!正则表达式 (在人工智能报告里找到了安装位置。。)

。。。。。
发现requests已经有了
以及pip必须在cmd里 不能在python里跑 , 还有就是要写成-m才可以。(在windows里)
以及py要求格式缩进.... 缩进。没缩进不行

学会了python的用法(找到。。)但是仍然失败的-。-
post的话网址变了,和之前的题解比。…… 有些鸡贼。
待续。小姐姐的博客:https://blog.csdn.net/destiny1507/article/details/82414623
[速度要快]
还是小姐姐博客里的 脚本!!窝还不会写!!!
【python】
Python3 bytes.decode()方法 Python3 字符串 描述 decode() 方法以指定的编码格式解码 bytes 对象。默认编码为 'utf-8'。
flag = base64.b64decode(flag) (base64解码)
参考这里:https://blog.csdn.net/New_feature/article/details/82974240
代码在备份里有。。哎 要是柿子杰看到我肯定瞬间就明白了
[正则表达式]
这里emmmmmmm
/key.*key.{4,7}key:\/.\/(.*key)[a-z][[:punct:]]/i
前面是分隔符, keyakeyaaaakey:/a/aakeyb,
keya(.是任意的需要写一个 *是0次或者多次)keyaaaa(重复4-7次)key:/a/a(是先用\转义了 再表明是/) 括号是用来表示范围的 akeyb.
[a-z]是啥都行 /i是不区分大小写 后面那个是括号
以后都按照这个构造就好
转载小姐姐的博客: https://blog.csdn.net/destiny1507/article/details/82429521
=============以下来自小姐姐博客
正则表达式语法补充:
一、
"\b" :不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 "is" 正则就要写成 "\bis\b"
\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
"\d": 匹配数字
"\w":匹配字母,数字,下划线.
"\s":匹配空格
".":匹配除了换行符以外的任何字符
"[abc]": 字符组 匹配包含括号内元素的字符
另:
"\W" 匹配任意不是字母,数字,下划线 的字符
"\S" 匹配任意不是空白符的字符
"\D" 匹配任意非数字的字符
"\B" 匹配不是单词开头或结束的位置
"[^abc]" 匹配除了abc以外的任意字符
二、(来自https://www.cnblogs.com/afarmer/archive/2011/08/29/2158860.html)
* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。
+ 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 中的”do” 。? 等价于 {0,1}。
{n} n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。
{n,} n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。
==============关于里面的代码:
<?php highlight_file('2.php'); $key='KEY{********************************}'; $IM= preg_match("/key.*key.{4,7}key:\/.\/(.*key)[a-z][[:punct:]]/i", trim($_GET["id"]), $match); if( $IM ){ die('key is: '.$key); } ?>
preg_match() 函数用于进行正则表达式匹配,成功返回 1 ,否则返回 0 。
preg_match() 匹配成功一次后就会停止匹配,如果要实现全部结果的匹配,则需使用 preg_match_all() 函数。preg_match (pattern , subject, matches)
| 参数 | 描述 |
|---|---|
| pattern | 正则表达式 |
| subject | 需要匹配检索的对象 |
| matches | 可选,存储匹配结果的数组 |
trim() 函数移除字符串两侧的空白字符或其他预定义字符。(并不那么可怕)
而且$_GET("name") 只是个名字(不重要)
如果地址是这样:http://zhidao.baidu.com/question/245400834.php?an=0&si=3
$_GET['an']; //等于0
$_GET['si']; //等于3
所以最后得出结论只要构造好发过去就可以了
还有... 很严重哦 这个是get, 不是post呀,get只要url里面输入id=..... (参见以前六级查询网站的xx=.... )就好了 不用hackbar (还是动点脑子 你看人家妹子都是自己在搞 你每次都查题解qnq)
正则: 继续https://blog.csdn.net/qq_26090065/article/details/81606045
^once 匹配那些以once开头的字符串
once$ 匹配那些以once结尾的字符串
[a-z] //匹配所有的小写字母
[A-Z] //匹配所有的大写字母
[a-zA-Z] //匹配所有的字母
[0-9] //匹配所有的数字
[0-9\.\-] //匹配所有的数字,句号和减号 (加 \ 是为了转义)
[ \f\r\t\n] //匹配所有的白字符
[[:alpha:]] 任何字母
[[:digit:]] 任何数字
[[:alnum:]] 任何字母和数字
[[:space:]] 任何空白字符
[[:upper:]] 任何大写字母
[[:lower:]] 任何小写字母
[[:punct:]] 任何标点符号
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]
[^0-9] 匹配除了数字的字符(在一组方括号里使用^时,它表示"非"或"排除"的意思 )
{3} 前面的字符或字符簇只出现3次
{x,} 前面的内容出现x或更多的次数
{x,y} 前面的内容至少出现x次,但不超过y次
? 与 {0,1} 是相等的,它们都代表着: 0个或1个前面的内容 或 前面的内容是可选的
* 与 {0,} 是相等的,它们都代表着 0 个或多个前面的内容
+ 与 {1,} 是相等的,表示 1 个或多个前面的内容
. 匹配除 "\n" 之外的任何单个字符
x|y 匹配 x 或 y
[xyz] 匹配所包含的任意一个字符
\b 匹配一个单词边界,例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界
\cx 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
\W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
\xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。.
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。
\n 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。
\nm 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。
\nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。
\un 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。
---------------------
作者:河马的鲸鱼
来源:CSDN
原文:https://blog.csdn.net/qq_26090065/article/details/81606045?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!
[login1[skctf]]
[你从哪里来]
加一个头部...
HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,
一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器藉此可以获得一些信息用于处理。
比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
Referer的正确英语拼法是referrer。
由于早期HTTP规范的拼写错误,为了保持向后兼容就将错就错了。
其它网络技术的规范企图修正此问题,使用正确拼法,所以目前拼法不统一。
(原文:https://blog.csdn.net/qq_30464257/article/details/81432021?utm_source=copy )
好了,最好从网页点击开始,重新抓一个包(感觉里面东西被我已经改坏了)
似乎大小写不敏感,但是必须字母要写对,比如forwarded
还有就是网址要写https://www.google.com
试了一下,加了hk(我那边网址)不能得到密码。hk是后面的顶级域名。因为.cn没了,好像现在一般企业都有这种认证的。。
==================
.com被定义为国际通用商业顶级域名。
.cn被定义为中国区域的顶级域名。
.com.cn先会去搜索.cn,找到.cn服务器后,再由.cn服务器搜索.com.
中国政府呼吁大家尽量注册在.cn下面,也就是中国政府建议你注册.com.cn
但从商业国际化角度看,.com要优于.com.cn.
只有一个问题,就是目前全球的根服务器,好象有13台在美国,1台在日本,还有的我不知道了。好象中国是没有的。也就是说,如果我们与美国的连线被切断,很有可能,国内用户还可以访问.com.cn,但不能访问.com了。
其实,从技术层面上说,.com域名和.cn域名并没有质量上的差异,有条件的话完全可以两个都注册了,这样对品牌保护可以更全面些。
[md5coll...]
【注意!经过md5加密之后的值是0e】
这样就会出错,之前遇到过!(误认为科学计数法)
以及,“please input a”
这个不是"one, 一个 "而是a啊 变量值叫a啊 【网页信息一般都是完整的啊 完整的啊 完整的啊】
记录一下!!!常见的oe开头的
【有问题,抓包解决。多抓包】(出了个false就false吗? 有变化已经成功了一半。)
QNKCDZO【记不住,就用了这个,QNKCDZO】
0e830400451993494058024219903391
s878926199a
0e545993274517709034328855841020
s155964671a
0e342768416822451524974117254469
s214587387a
0e848240448830537924465865611904
s214587387a 【s214587387a】
0e848240448830537924465865611904
s878926199a
0e545993274517709034328855841020
s1091221200a
0e940624217856561557816327384675
s1885207154a
0e509367213418206700842008763514
s1502113478a
0e861580163291561247404381396064
s1885207154a
0e509367213418206700842008763514
0e861580163291561247404381396064
s1885207154a
0e509367213418206700842008763514
s1836677006a
0e481036490867661113260034900752
s155964671a
0e342768416822451524974117254469
s1184209335a
0e072485820392773389523109082030
原文:https://blog.csdn.net/qq_39629343/article/details/80696263?utm_source=copy
[程序员本地网站]
改xff头就可以了...
【记录一下 伪造成在本地登录:】
X-Forwarded-For: 简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项。
此外,发现burp抓包改的时候可以直接在repeater里面改,改了看到改过之后的回应。!!!!!
就像python那个界面。。。。可视化的会好一点点














 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









