






http://antkillerfarm.github.io/
浮点运算和代码优化
1.浮点运算问题
浮点运算在工业中应用非常广泛,但嵌入式CPU通常没有对浮点运算提供直接的硬件支持。而采用标准库提供的软件计算方案,性能又很差。这时就需要使用浮点运算协处理器加速浮点运算。(486之前的PC,CPU和浮点运算协处理器FPU也是分开的,例如i486DX是有FPU的型号,而i486SX则是没有FPU的型号。)
硬件的支持离不开软件的使用。如果在添加了FPU的硬件上,使用浮点计算的软件方案的话,FPU也是不起作用的。因此必须用FPU驱动库函数替换标准库提供的软件方案的相应函数。
最直观的做法是将所有用到浮点计算的地方都替换成FPU函数。例如如下代码:
float a,b,c;
a = b + c;假设FPU加法函数的原型为:
float Add(float a, float b);
如果我们要使用FPU硬件加速的话,只需要将上述代码改为:
float a,b,c;
a = Add(b,c);就可以了。
上面的这种方法显然是直观而正确的,但是却不方便。需要将源代码中,所有涉及到浮点运算的地方都做相应的修改,而且以函数的方式取代C语言中的运算符,本身书写起来也很麻烦。
我们可以这样思考一下,C语言是如何将运算符转换成机器指令的呢?首先编译阶段肯定要做类型判断,整数加法和浮点数加法的指令显然不会相同。而链接阶段,只有符号表的概念,类型也好、运算符也好,都灰飞烟灭了。
因此,我们只要看一看浮点加法的汇编指令,就可以找到相关的符号表了。经查浮点加法对应的符号是__adddf3(gcc下)。因此它的原型就是:
float64 __adddf3(float64 x, float64 y)
将FPU函数写成这个样子,然后在链接阶段替换标准库函数就可以了。具体操作如下:
1.使用nm命令查看libgcc.a中的符号表,可以查到__adddf3在_addsub_df.o中。
2.使用ar命令的d选项从libgcc.a中去掉_addsub_df.o。
3.在链接时使用FPU函数库
2.立即数计算量的问题
请看以下代码:
float64 a, b,c;
a = 2*PI * (b - c) / 365.25;机器执行这段代码会进行几次运算呢?
答案是3次。虽然有4个运算符,但2*PI是在编译阶段运算的。(这可以通过查看生成的汇编代码来验证。)基于同样的理由,我们还可以改进这段代码:
a = 2*PI / 365.25 * (b - c);
这样只需要2次运算了。
需要说明的是括号如果不改变运算的顺序的话,是不会改变计算次数的。因此
a = (2*PI / 365.25) * (b - c);
和
a = 2*PI / 365.25 * (b - c);
是等效的,都只需要2次运算。
3.冗余代码的问题
假设我们定义了a函数,但是在其他地方并未使用该函数,我们是否可以认为a函数的代码不会出现在最终的可执行文件中呢?
这个问题至少在gcc没有设置任何参数时,是否定的。不管a函数使用与否,它的代码都会包含在最终的可执行文件中。
对于PC来说,这不是个太大的问题,但对于嵌入式设备来说,任何空间的浪费都是不可接受的。
写到这里,有人会说,使用gcc的-o2选项优化代码,不就可以了吗?遗憾的是,这是不行的。
-o2有什么作用呢?还是上面的例子:
void main()
{
float64 a, b,c;
a = 2*PI * (b - c) / 365.25;
}如果是-o2选项的话,机器会进行几次运算呢?
答案是0次。这种不涉及到输出结果的计算,直接被忽略掉了。
回到第一个问题。如何做才能在最终的可执行文件中不包含未使用的函数呢?步骤如下:
gcc添加-ffunction-sections选项。我们通常的做法是一个.c文件编译生成一个.o文件。而这个.c文件中的函数代码都会包含在.o文件的.text段(section)中。而-ffunction-sections选项会将每个函数放在单独的段中,例如a函数,会被放到.text.a段中。
ld添加–gc-sections选项。这个选项的作用是不链接未使用的段。
从上面的步骤可以看出,链接的最小单位既不是.o文件,也不是单个函数,而是段。
使用以上方法生成的程序,理论上没什么问题,但实际中,还是有不方便之处:为每一个函数生成一个段,可以想象可执行文件中会有多少段,而在某些平台上,代码在段之间的跳转是要比段内跳转消耗资源的。
我们可以在链接脚本中合并这些段,以下是一个简单的实例:
.text :
{
. = ALIGN(4);
text_start = .;
*(.text.*)
. = ALIGN(4);
text_end = .;
}音频常识
人的听觉范围
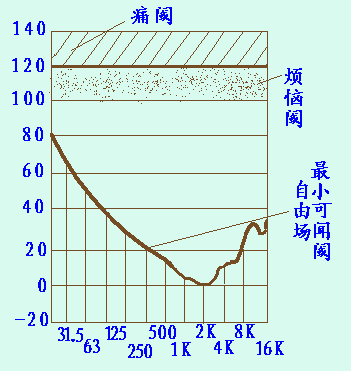
图上的上限是到16KHz,但并不是说16KHz以上听不到了,因为高频听力随着年龄增长而减弱直到丧失,一般来说25岁以上的人,在16KHz以上的听力几乎完全丧失,而10几岁的人,完全可以听到19KHz左右的声音(这就是有一种传说中的蚊音手机铃声神马的,在中学生间流传很广,据说老师听不到只有学生能听到,也是基于这个道理)。
各种编解码算法比较
http://www.rosoo.net/a/201012/10600.html
这个帖子比较了ITU提出的G系列的各种语音编解码方案。
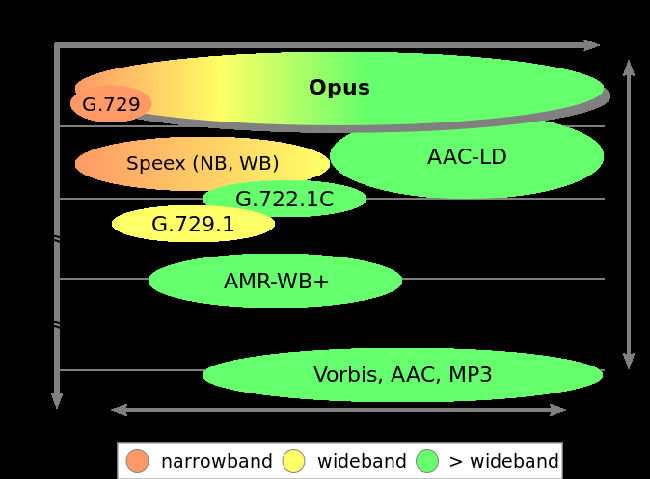
上图是各种音频编解码框架的比较图。
其中narrowband是指频率在4kHz以下的声音信号,一般情况下,人的说话声就位于这个频率范围内,因此又被称为“语音”。
allband是指频率在24kHz以下的声音信号。这也是人耳所能听到的频率范围。这个范围内的声音统称“音频”。
介于两者之间的,被称为wideband。
声道
声道一般表示为X.Y的形式,其中X为高音音箱的个数,Y为低音音箱的个数。比如常见的2.1声道,就是左音箱、右音箱+低音音箱(俗称低音炮)。
一般来说,Y的值为0或1。而X的值,有以下几种:
1.X=1。单声道
2.X=2。左、右。
3.X=4。前左、前右,后左、后右。
4.X=5。前左、前右,后左、后右、中置。
5.X=7。前左、前右,后左、后右、中置、中左、中右。
数字功放
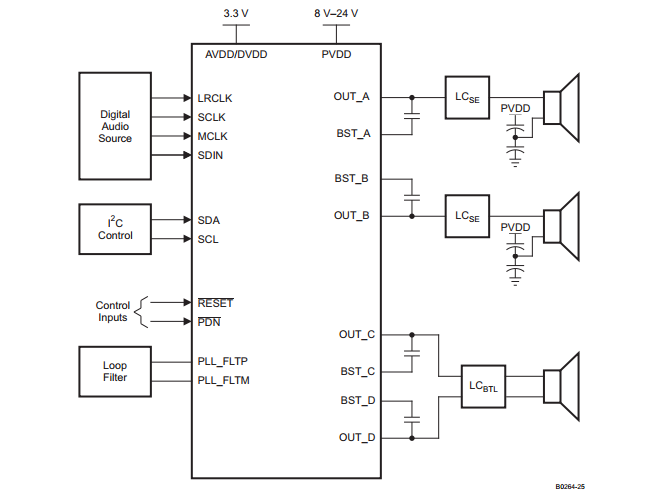
上图是TI TAS5731M的2.1声道应用图。
其中的SE,表示单端连接模式(Single-End),和桥接式负载 BTL(Bridge-Tied-Load)相对应。后者在同等供电电压和负载的情况下,可以提供4倍于SE的输出功率,并具有良好的低频响应,常用于连接低音音箱。
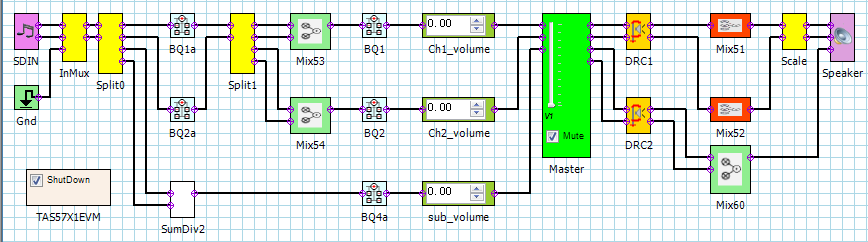
这是TI TAS5731M数字音频的处理流程,其中上两路是高音声道,最下面一路是低音声道。
IIS
亦称I2S。Inter—IC Sound总线是飞利浦公司为数字音频设备之间的音频数据传输而制定的一种总线标准,该总线专责于音频设备之间的数据传输,广泛应用于各种多媒体系统。
I2S总线由4根线组成:
1.SDATA。数据线,根据方向的不同,又分为SDO和SDI。一根数据线可以传输两个声道的数据,但对于当前越来越多的声道来说,这显然就不够用了。因此目前的MCU设计中,多数都集成了更多的SDO线。这些SDO线共享各种时钟线。多SDO线的DMA传输,一般采用时分复用的交错数据流的方式来设置。
2.LRCK,(也称WS)。帧时钟,用于切换左右声道的数据。LRCK为“1”表示正在传输的是右声道的数据,为“0”则表示正在传输的是左声道的数据。LRCK的频率等于采样频率。
3.SCLK,也叫位时钟(BCLK)。1个脉冲对应数字音频的每一位数据。SCLK的频率=2×采样频率×采样位数。
4.MCLK,称为主时钟,也叫系统时钟(Sys Clock),是采样频率的256倍或384倍。它可以使系统间能够更好地同步。
I2S总线的性能主要由以下指标决定:
1.采样频率。根据上面对narrowband、wideband、allband的讨论,以及采样定理可知,采样频率最低为8kHz,超过48kHz可以算是allband。
2.采样位数。越大越好。目前数字功放(如TI TAS5731M)已经可以支持24bit和32bit,但wifi芯片基本还是16bit的。
I2S总线的时序标准分为三种:
1.I2S。
2.Left-Justified
3.Right-Justified
I2S总线在硬件测试时,可播放1KHz正弦波的wav文件。这个wav文件的频率,在人的声觉最敏感的范围(1KHz~4KHz)内,同时也便于示波器观察模拟端的输出信号。
文件后缀名与编码格式
| 文件后缀名 | 音频编码(空表示编码格式和文件后缀名一致) | 视频编码(空表示该格式没有视频数据) |
|---|---|---|
| .aac .ac3 .ape .mp2 .mp3 .flac .wma | ||
| .au | pcm_s16be | |
| .wav | pcm_s16le pcm_float | |
| .ogg | vorbis | |
| .m4a | mpeg4 aac | |
| .3gp | mpeg4 | amr_nb |
| .3g2 | mpeg4 | mpeg4 aac |
| .asf | msmpeg4 | mp3 |
| .mov | mpeg4_qt | mpeg4 aac_qt |
| .rm | rv10 | ac3 |
| .vob | mpeg2 | ac3 |
| .wmv | wmv | wma |
常用格式中的.avi .mp4,由于支持的编码格式众多,且没有主要的使用格式,故不列出。
术语
Pre-emphasis,预加重。与之对应的是De-emphasis去加重。是一项关于噪声整形的技术。
并行计算
概述
并行计算的必要性:
美国Sandia国家实验室一项模拟测试证明:由于存储机制和内存带宽的限制,16核、32核甚至64核处理器对于超级计算机来说,不仅不能带来性能提升,甚至可能导致效率的大幅度下降。
常见并行计算框架
| 名称 | 优点 | 缺点 |
|---|---|---|
| CUDA | 生态系统良好,发展成熟。 | 只能NV的卡。 |
| OpenCL | 跨平台,很容易异构计算。 | 大家都把它当作干儿子,没人认真写它的驱动。 |
| C++ AMP | 基于Direct compute,易于使用。 | Windows Only。 |
| OpenMP | 移植改动少 | CPU多线程而已,和GPU无关。 |
| Metal | for iOS | - |
其他的并行计算框架还有:OpenACC、AMD stream。
NVIDIA相关产品线:
Tesla产品专为数据中心与工作站计算应用而设计。
Quadro产品专为专业图形与工程应用而设计。
GeForce产品专为互动游戏与消费类应用而设计。
OpenCL vs CUDA
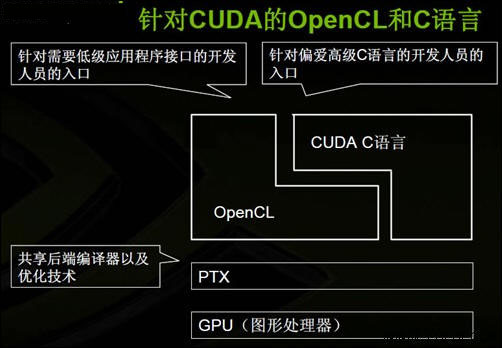
教程
http://blog.csdn.net/augusdi/article/details/12833235
这是一篇转帖的CUDA教程,原帖比较分散,不好看。














 1730
1730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









