







https://antkillerfarm.github.io/
词向量
word2vec/doc2vec的缺点(续)
2.虽然我们一般使用word2vec/doc2vec来比较文本相似度,但是从原理来说,word2vec/doc2vec提供的是关联性(relatedness),而不是相似性(similarity)。这会带来以下问题:不但近义词的词向量相似,反义词的词向量也相似。因为它们和其他词的关系(也就是语境)是类似的。
3.由于一个词只有一个向量来表示,因此,无法处理一词多义的情况。
然而关联性并非都是坏事,有的时候也会起到意想不到的效果。比如在客服对话的案例中,客户可能会提供自己的收货地址,显然每个客户的地址都是不同的,但是有意思的是,这些地址的词向量是非常相似的。
总之,只利用无标注数据训练得到的Word Embedding在匹配度计算的实用效果上和主题模型技术相差不大,它们本质上都是基于共现信息的训练。
参考:
https://www.zhihu.com/question/22266868
Word2Vec如何解决多义词的问题?
All is Embedding
向量化是机器学习处理非数值数据的必经之路。因此除了词向量之外,还有其他的Embedding。比如Network Embedding。
https://mp.weixin.qq.com/s/wcFlZPbB5dl6C87kdfjmKw
NE(Network Embedding)论文小览
https://mp.weixin.qq.com/s/zTNX_LeVMeHhJG7kPewn2g
除了自然语言处理,你还可以用Word2Vec做什么?
参考
http://www.cnblogs.com/iloveai/p/word2vec.html
word2vec前世今生
http://www.cnblogs.com/maybe2030/p/5427148.html
文本深度表示模型——word2vec&doc2vec词向量模型
https://www.zhihu.com/question/29978268
如何用word2vec计算两个句子之间的相似度?
https://mp.weixin.qq.com/s/kGi-Hf7CX6OKcCMe7IC7zA
NLP之Wrod2Vec三部曲
RNN
RNN的基本结构
RNN是Recurrent Neural Network和Recursive Neural Network的简称。前者主要用于处理和时序相关的输入,而后者目前已经没落。本文只讨论前者。
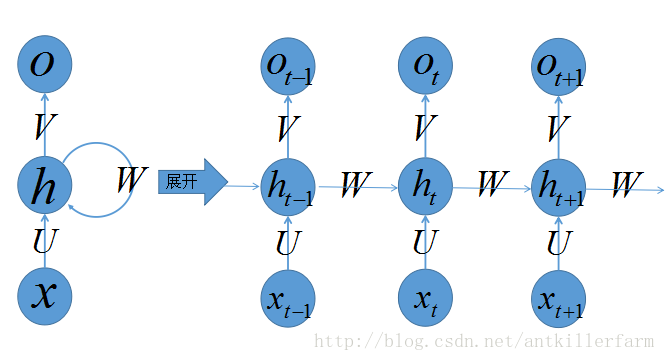
上图是RNN的结构图。其中,展开箭头左边是RNN的静态结构图。不同于之前的神经网络表示,这里的圆形不是单个神经元,而是一层神经元。权值也不是单个权值,而是权值向量。
从静态结构图可以看出RNN实际上和3层MLP的结构,是基本类似的。差别在于RNN的隐藏层多了一个指向自己的环状结构。
上图的展开箭头右边是RNN的时序展开结构图。从纵向来看,它只是一个3层的浅层神经网络,然而从横向来看,它却是一个深层的神经网络。可见神经网络深浅与否,不仅和模型本身的层数有关,也与神经元之间的连接方式密切相关。
虽然理论上,我们可以给每一时刻赋予不同的 U,V,W ,然而出于简化计算和稀疏度的考量,RNN所有时刻的 U,V,W 都是相同的。
RNN的误差反向传播算法,被称作Backpropagation Through Time。其主要公式如下:
从上式可以看出,三个误差梯度实际上都是时域的积分。
正因为RNN的状态和过去、现在都有关系,因此,RNN也被看作是一种拥有“记忆性”的神经网络。
RNN的训练困难
理论上,RNN可以支持无限长的时间序列,然而实际情况却没这么简单。
Yoshua Bengio在论文《On the difficulty of training recurrent neural networks》(http://proceedings.mlr.press/v28/pascanu13.pdf)中,给出了如下公式:
并指出当 η<1 时,RNN会Gradient Vanish,而当 η>1 时,RNN会Gradient Explode。
这里显然不考虑 η>1 的情况,因为Gradient Explode,直接会导致训练无法收敛,从而没有实用价值。
因此有实用价值的,只剩下 η<1 了,但是Gradient Vanish又注定了RNN所谓的“记忆性”维持不了多久,一般也就5~7层左右。
上述内容只是一般性的讨论,实际训练还是有很多trick的。
比如,针对 η>1 的情况,可以采用Gradient Clipping技术,通过设置梯度的上限,来避免Gradient Explode。
还可使用正交初始化技术,在训练之初就将 η 调整到1附近。
参考
http://blog.csdn.net/aws3217150/article/details/50768453
递归神经网络(RNN)简介
http://blog.csdn.net/heyongluoyao8/article/details/48636251
循环神经网络(RNN, Recurrent Neural Networks)介绍
循环神经网络
Backpropagation Through Time算法
https://baijia.baidu.com/s?old_id=560025
Tomas Mikolov详解RNN与机器智能的实现
https://sanwen8.cn/p/3f8sRTh.html
为什么RNN需要做正交初始化?
http://blog.csdn.net/shenxiaolu1984/article/details/71508892
RNN的梯度消失/爆炸与正交初始化
https://mp.weixin.qq.com/s/vHQ1WbADHAISXCGxOqnP2A
看大牛如何复盘递归神经网络!
https://mp.weixin.qq.com/s/0V9DeG39is_BxAYX0Yomww
为何循环神经网络在众多机器学习方法中脱颖而出?
https://mp.weixin.qq.com/s/-Am9Z4_SsOc-fZA_54Qg3A
深度理解RNN:时间序列数据的首选神经网络!
https://mp.weixin.qq.com/s/ztIrt4_xIPrmCwS1fCn_dA
“魔性”的循环神经网络
https://mp.weixin.qq.com/s/tIXJNkT9gIjGYZz7dekiNw
手把手教你写一个RNN
https://mp.weixin.qq.com/s/BqVicouktsZu8xLVR-XnFg
完全图解RNN、RNN变体、Seq2Seq、Attention机制
LSTM
本篇笔记主要摘自:
http://www.jianshu.com/p/9dc9f41f0b29
理解LSTM网络
LSTM结构图
为了解决原始RNN只有短时记忆的问题,人们又提出了一个RNN的变种——LSTM(Long Short-Term Memory)。其结构图如下所示:
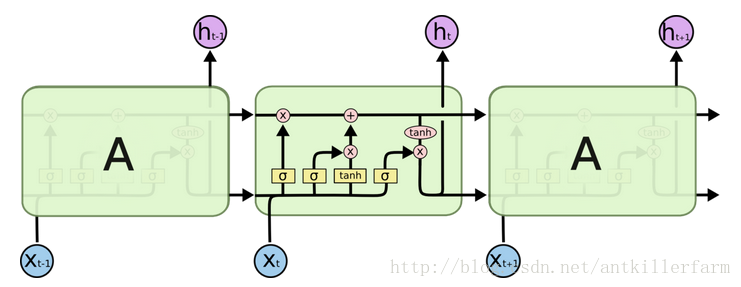
和RNN的时序展开图类似,这里的每个方框表示某个时刻从输入层到隐层的映射。
我们首先回顾一下之前的模型在这里的处理。
MLP的该映射关系为:
RNN在上式基础上添加了历史状态 ht−1 :
LSTM不仅添加了历史状态 ht−1 ,还添加了所谓的细胞状态 Ct−1 ,即上图中图像上部的水平横线。
步骤详解
神经网络的设计方式和其他算法不同,我们不需要指定具体的参数,而只需要给出一个功能的实现机制,然后借助误差的反向传播算法,训练得到相应的参数。这一点在LSTM上体现的尤为明显。
LSTM主要包括以下4个步骤(也可称为4个功能或门):
决定丢弃信息
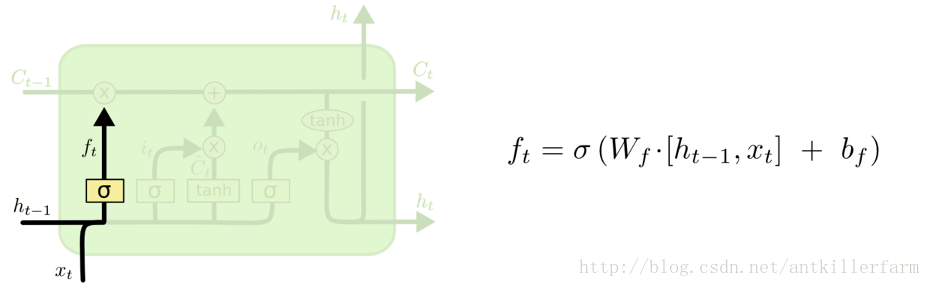
这一部分也被称为忘记门。
确定更新的信息
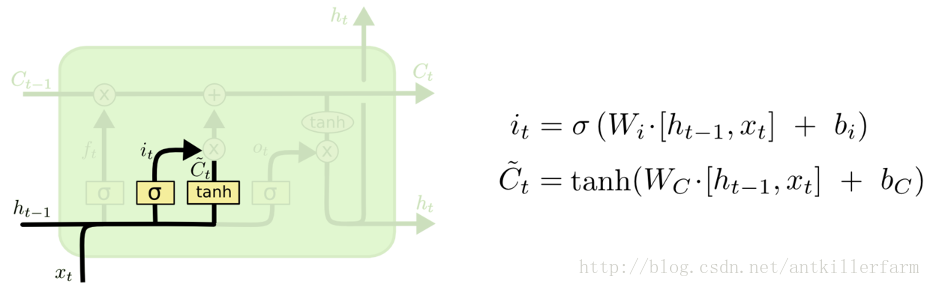
这一部分也被称为输入门。
更新细胞状态
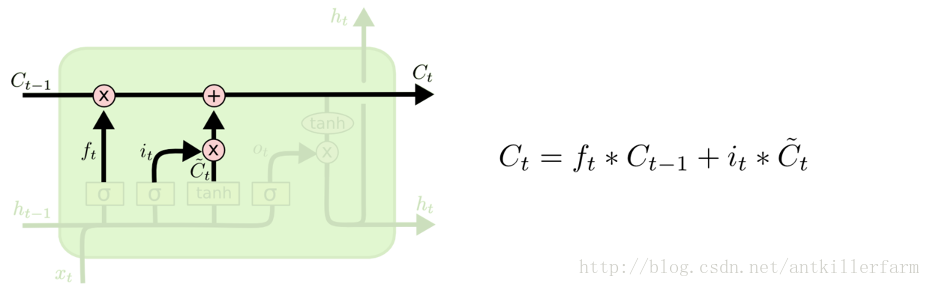
输出信息

显然,在这里不同的参数会对上述4个功能进行任意组合,从而最终达到长时记忆的目的。
注意:在一般的神经网络中,激活函数可以随意选择,无论是传统的sigmoid,还是新的tanh、ReLU,都不影响模型的大致效果。(差异主要体现在训练的收敛速度上,最终结果也可能会有细微影响。)
但是,LSTM模型的上述函数不可随意替换,切记。
LSTM的变体
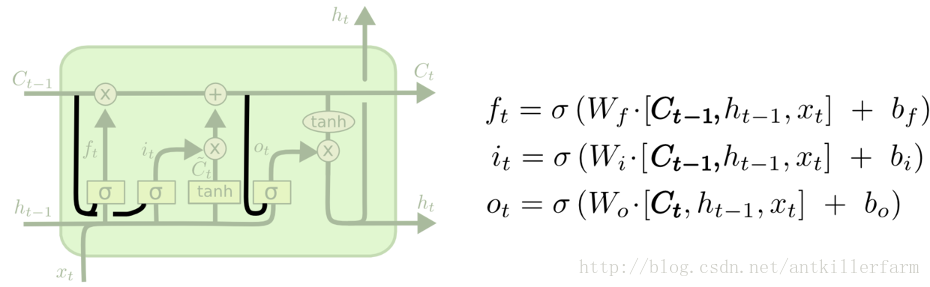
上图中的LSTM变体被称为peephole connection。其实就是将细胞状态加入各门的输入中。可以全部添加,也可以部分添加。
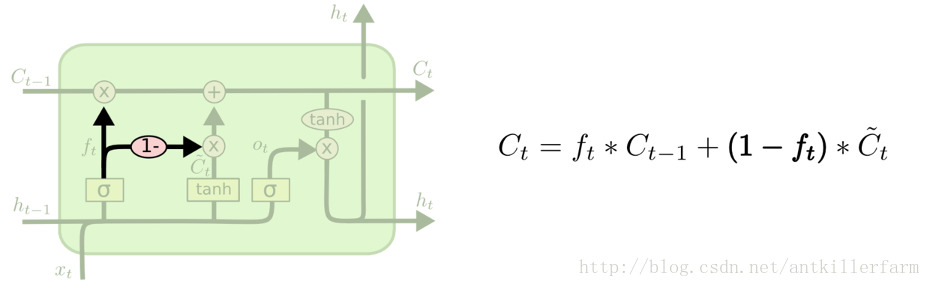
上图中的LSTM变体被称为coupled 忘记和输入门。它将忘记和输入门连在了一起。

上图是一个改动较大的变体Gated Recurrent Unit(GRU)。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
参考
http://www.csdn.net/article/2015-06-05/2824880
深入浅出LSTM神经网络
https://zhuanlan.zhihu.com/p/25821063
循环神经网络——scan实现LSTM
http://blog.csdn.net/a635661820/article/details/45390671
LSTM简介以及数学推导(FULL BPTT)
https://mp.weixin.qq.com/s/x3y9WTuVFYQb60eJvw02HQ
如何解决LSTM循环神经网络中的超长序列问题
https://mp.weixin.qq.com/s/IhCfoabRrtjvQBIQMaPpNQ
从任务到可视化,如何理解LSTM网络中的神经元
https://mp.weixin.qq.com/s/GGpaFZ0crP_NQ564d79hFw
LSTM、GRU与神经图灵机:详解深度学习最热门的循环神经网络
https://mp.weixin.qq.com/s/0bBTVjkfAK2EzQiaFcUjBA
LSTM入门必读:从基础知识到工作方式详解
https://mp.weixin.qq.com/s/jcS4IX7LKCt1E2FVzLWzDw
LSTM入门详解
神经元激活函数进阶
在《深度学习(一、二)》中,我们探讨了ReLU相对于sigmoid函数的改进,以及一些保证深度神经网络能够训练的措施。然而即便如此,深度神经网络的训练仍然是一件非常困难的事情,还需要更多的技巧和方法。
激活函数的作用
神经网络中激活函数的主要作用是提供网络的非线性建模能力,如不特别说明,激活函数一般而言是非线性函数。
假设一个神经网络中仅包含线性卷积和全连接运算,那么该网络仅能够表达线性映射,即便增加网络的深度也依旧还是线性映射,难以有效建模实际环境中非线性分布的数据。
加入非线性激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。因此,激活函数是深度神经网络中不可或缺的部分。
注意:其实也有采用线性激活函数的神经网络,亦被称为linear neurons。但是这些神经网络,基本只有学术价值而无实际意义。
ReLU的缺点
深度神经网络的训练问题,最早是2006年Hinton使用分层无监督预训练的方法解决的,然而该方法使用起来很不方便。
而深度网络的直接监督式训练的最终突破,最主要的原因是采用了新型激活函数ReLU。
但是ReLU并不完美。它在x<0时硬饱和,而当x>0时,导数为1。所以,ReLU能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。但随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为神经元死亡。
ReLU还经常被“诟病”的另一个问题是输出具有偏移现象,即输出均值恒大于零。偏移现象和神经元死亡会共同影响网络的收敛性。实验表明,如果不采用Batch Normalization,即使用MSRA初始化30层以上的ReLU网络,最终也难以收敛。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









