







 本文深入解析Spark在Standalone模式下如何利用ZooKeeper和Curator实现Master的高可用(HA)。内容涵盖Master重启策略、集群启动参数配置、Curator简化ZooKeeper使用、ZooKeeperLeaderElectionAgent的实现及其设计理念。
本文深入解析Spark在Standalone模式下如何利用ZooKeeper和Curator实现Master的高可用(HA)。内容涵盖Master重启策略、集群启动参数配置、Curator简化ZooKeeper使用、ZooKeeperLeaderElectionAgent的实现及其设计理念。
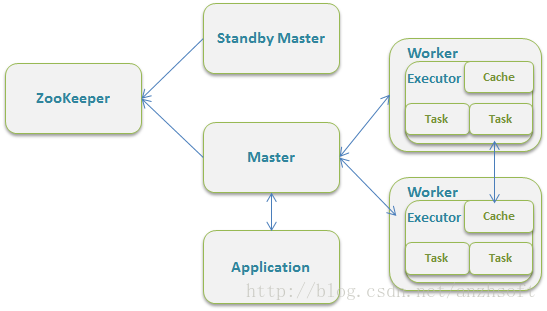
如果Spark的部署方式选择Standalone,一个采用Master/Slaves的典型架构,那么Master是有SPOF(单点故障,Single Point of Failure)。Spark可以选用ZooKeeper来实现HA。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master但是只有一个是Active的,其他的都是Standby,当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
1. Master的重启策略
Master在启动时,会根据启动参数来决定不同的Master故障重启策略:
- ZOOKEEPER实现HA
- FILESYSTEM:实现Master无数据丢失重启,集群的运行时数据会保存到本地/网络文件系统上
- 丢弃所有原来的数据重启
Master::preStart()可以看出这三种不同逻辑的实现。
override def preStart() {
logInfo("Starting Spark master at " + masterUrl)
...
//persistenceEngine是持久化Worker,Driver和Application信息的,这样在Master重新启动时不会影响
//已经提交Job的运行
persistenceEngine = RECOVERY_MODE match {
case "ZOOKEEPER" =>
logInfo("Persisting recovery state to ZooKeeper")
new ZooKeeperPersistenceEngine(SerializationExtension(context.system), conf)
case "FILESYSTEM" =>
logInfo("Persisting recovery state to directory: " + RECOVERY_DIR)
new FileSystemPersistenceEngine(RECOVERY_DIR, SerializationExtension(context.system))
case _ =>
new BlackHolePersistenceEngine()
}
//leaderElectionAgent负责Leader的选取。
leaderElectionAgent = RECOVERY_MODE match {
case "ZOOKEEPER" =>
context.actorOf(Props(classOf[ZooKeeperLeaderElectionAgent], self, masterUrl, conf))
case _ => // 仅仅有一个Master的集群,那么当前的Master就是Active的
context.actorOf(Props(classOf[MonarchyLeaderAgent], self))
}
}RECOVERY_MODE是一个字符串,可以从spark-env.sh中去设置。
val RECOVERY_MODE = conf.get("spark.deploy.recoveryMode", "NONE")如果不设置spark.deploy.recoveryMode的话,那么集群的所有运行数据在Master重启是都会丢失,这个结论是从BlackHolePersistenceEngine的实现得出的。
private[spark] class BlackHolePersistenceEngine extends PersistenceEngine {
override def addApplication(app: Application 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5721
5721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









