






前言
近期在学习使用Hive(版本号0.13.1)的过程中,发现了一些坑,它们也许是Hive提倡的比关系数据库更加自由的体现(同一时候引来一些问题)。也许是一些bug。总而言之,这些都须要使用Hive的开发者额外注意。本文旨在列举我发现的3个通过查询语句向表中插入数据过程中的问题,希望大家注意。
数据准备
为了验证接下来出现的问题,须要先准备两张表employees和staged_employees。并准备好測试数据。首先使用下面语句创建表employees:
create table employees (
id int comment 'id',
name string comment 'name')
partitioned by (country string, state string)
row format delimited fields terminated by ',';employees的结构比較简单,有id、name、country、state四个字段,当中country和state都是分区字段。特别须要提醒的是这里显示的给行格式指定了字段分隔符为逗号。因为默认的字段分隔符\001不便于笔者准备数据。然后创建表staged_employees:
create table staged_employees (
id int comment 'id',
user_name string comment 'user name')
partitioned by (cnty string, st string);staged_employees也有4个字段,除了字段名不同之外,和employees的4个字段的含义是同样的。
我们首先使用下面语句给employees的country等于US,state等于CA的分区载入一些数据:
load data local inpath '${env:HOME}/test.txt'
into table employees
partition (country = 'US', state = 'CA');再给employees的country等于CN。state等于BJ的分区载入一些数据:
load data local inpath '${env:HOME}/test2.txt'
overwrite into table employees
partition (country = 'CN', state = 'BJ');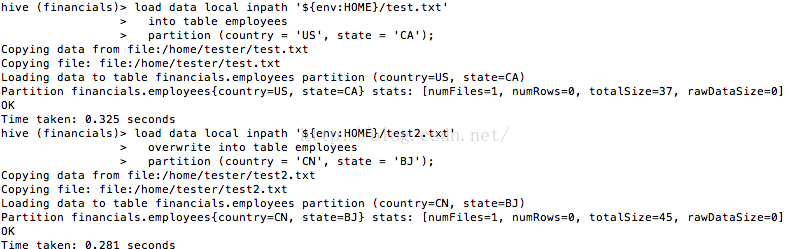
图1 给employees载入数据
最后我们看看employees中准备好的数据,如图2所看到的。

图2 employees中准备好的数据
INSERT OVERWRITE的歧义
因为staged_employees中还没有数据。所以我们查询employees的数据,并插入staged_employees中:
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select * from employees e
where e.country = 'US' and e.state = 'CA';
FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different ''CA'': Table insclause-0 has 2 columns, but query has 4 columns.仅仅有在读取数据时才会验证。因此在向表
staged_employees 插入数据时不会验证。而查询读取 employees表中的数据时会验证。我对sql进行了调整,调整后的清单例如以下:
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name from employees e
where e.country = 'US' and e.state = 'CA';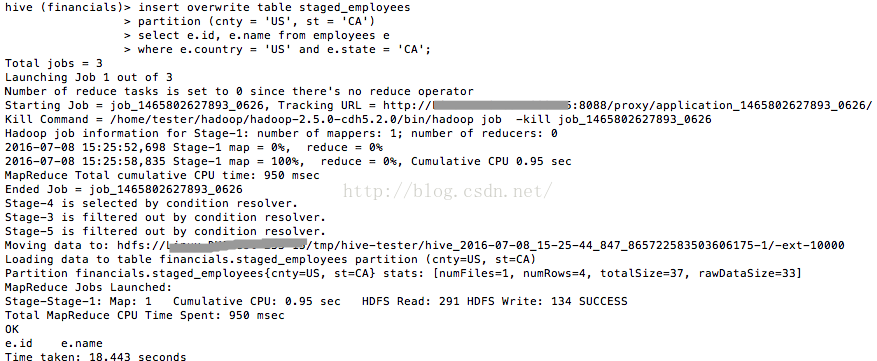
图4 正确运行insert overwrite
我们看看staged_employees表中,如今有哪些数据(如图5所看到的):

图5 staged_employees中的数据
熟悉MySQL等关系型数据库的同学可能要格外注意此问题了。
FROM ... INSERT ... SELECT的歧义
本节正式開始之前,向employees表中再载入一些数据:
load data local inpath '${env:HOME}/test3.txt'
into table employees
partition (country = 'CA', state = 'ML');
图6 载入新的数据
这时表employees的数据如图7所看到的。
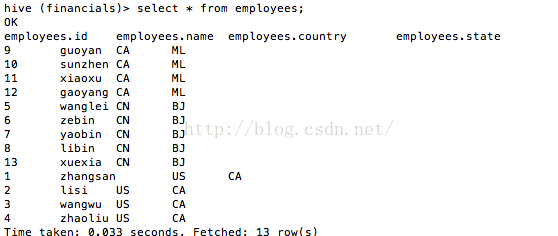
图7
Hive提供了一种特别的INSERT语法。我们最好还是先看看其使用方式,sql例如以下:
from employees e
insert into table staged_employees
partition (cnty = 'CA', st = 'ML')
select * where e.country = 'CA' and e.state = 'ML';
图8 SemanticException [Error 10044]
能够看到这里再次出现了之前提到的问题,我们依旧依照之前的方式进行改动,sql例如以下:
from employees e
insert into table staged_employees
partition (cnty = 'CA', st = 'ML')
select e.id, e.name where e.country = 'CA' and e.state = 'ML';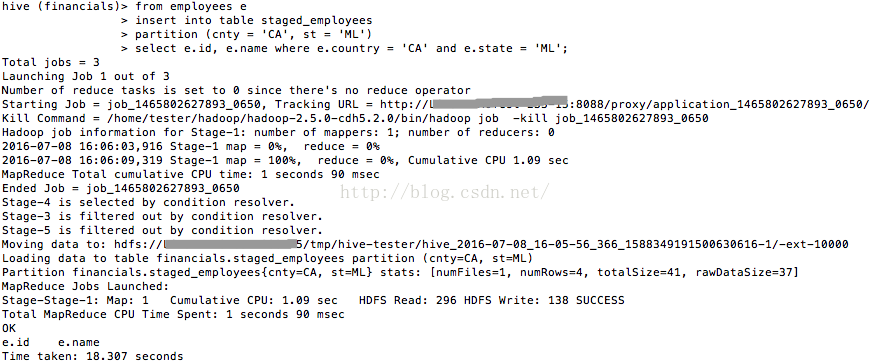
图9
如今来看看staged_employees中的数据(如图10所看到的),看来的确将分区数据插入了。
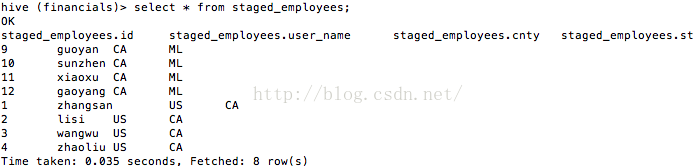
图10 staged_employees中的数据
FROM ... INSERT ... SELECT存在bug
我们继续使用FROM ... INSERT ... SELECT语法向staged_employees中插入数据,sql例如以下:
from employees e
insert into table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA';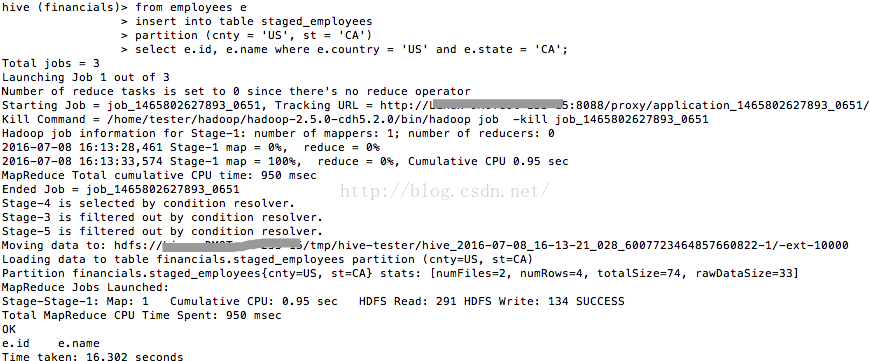
图11
我们看看这时staged_employees中的数据。如图12所看到的。

图12
的确印证了,INSERT INTO是用于追加的。
我们将sql进行调整,即将INSERT INTO改为INSERT OVERWRITE:
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA';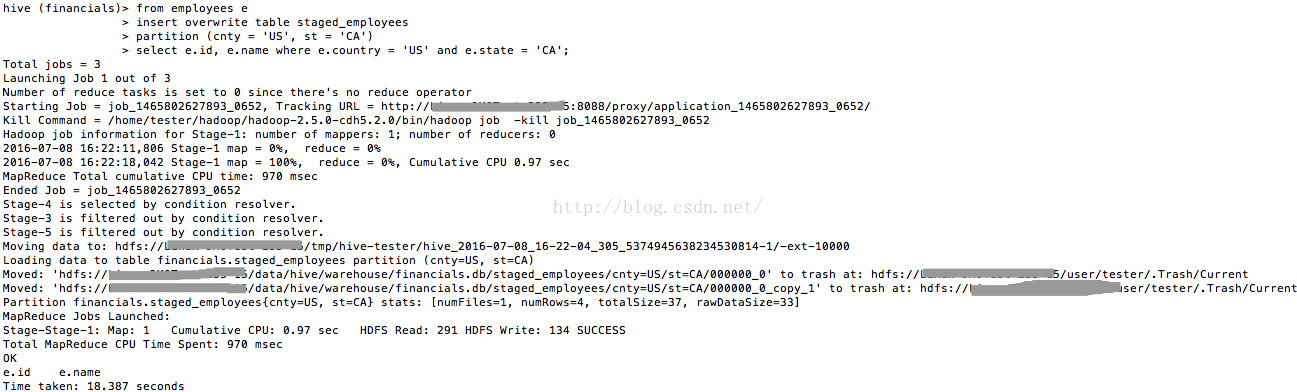
图13
我们看看这时staged_employees中的数据,如图14所看到的。
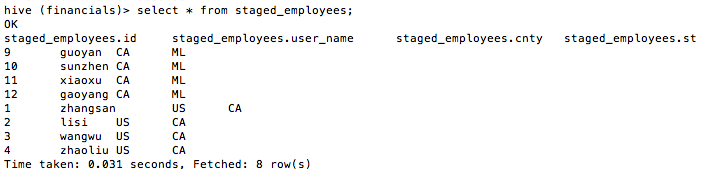
图14
这说明INSERT OVERWRITE是用于覆盖的。
依据官方文档说明,这样的FROM ... INSERT ... SELECT语法中的INSERT ... SELECT是能够有多个的。于是我编写下面sql,用来向表staged_employees中覆盖“country等于CA。state等于ML”分区的数据。而且覆盖“country等于US。state等于CA”分区的数据。
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA'
insert overwrite table staged_employees
partition (cnty = 'CA', st = 'ML')
select e.id, e.name where e.country = 'CA' and e.state = 'ML';运行以上sql的过程如图15所看到的。
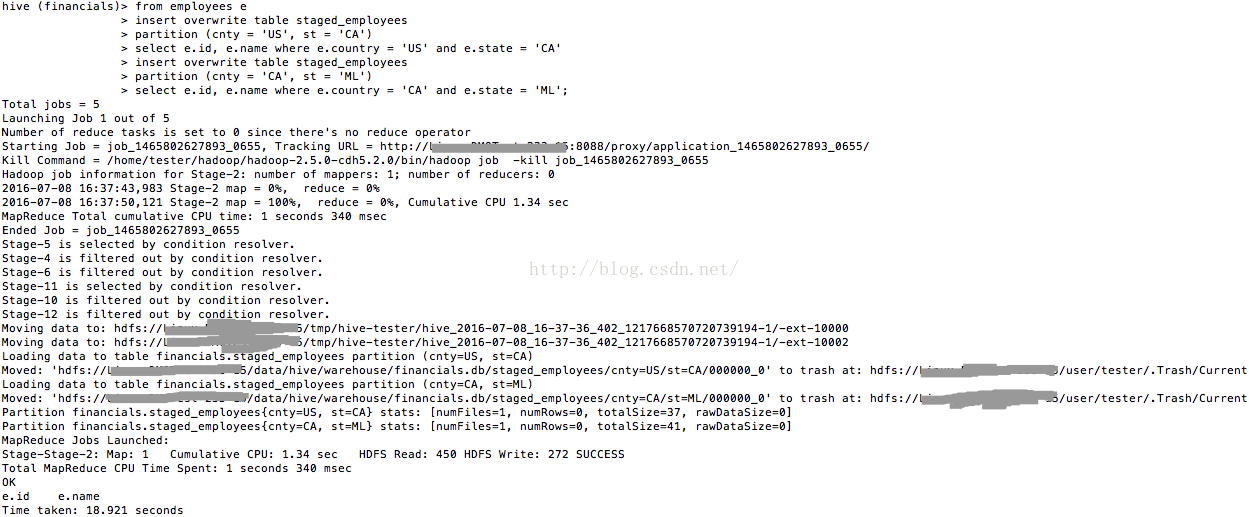
图15
因为都是覆盖更新,所以staged_employees中的数据并未发生改变。
依据官方文档。以上sql中还能够将INSERT OVERWRITE和INSERT INTO进行混用,sql例如以下:
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA'
insert into table staged_employees
partition (cnty = 'CN', st = 'BJ')
select e.id, e.name where e.country = 'CN' and e.state = 'BJ';这段sql将覆盖“country等于US。state等于CA”分区的数据。而且追加“country等于CN,state等于BJ”分区的数据。
运行这段sql的过程如图16所看到的。

图16
最后。我们来看看staged_employees中的数据,如图17所看到的。
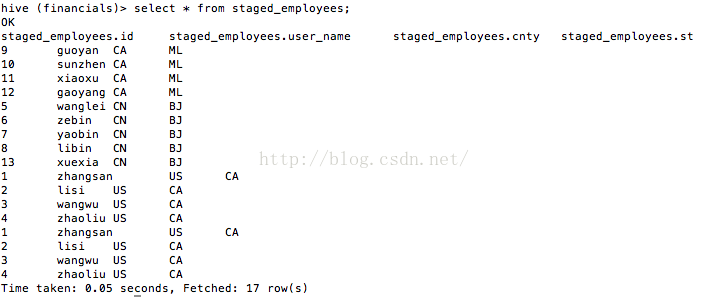
图17
从图17中看到,“country等于CN。state等于BJ”分区的数据如我们所愿追加到表staged_employees中了。“country等于US。state等于CA”分区的数据并没有被覆盖。而是追加。
这非常明显是一个bug,希望大家注意!
后记:个人总结整理的《深入理解Spark:核心思想与源代码分析》一书如今已经正式出版上市,眼下京东、当当、天猫等站点均有销售,欢迎感兴趣的同学购买。

京东:http://item.jd.com/11846120.html
当当:http://product.dangdang.com/23838168.html














 9048
9048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









