






声明:
1,本篇为个人对《2012.李航.统计学习方法.pdf》的学习总结。不得用作商用,欢迎转载,但请注明出处(即:本帖地址)。
2,因为本人在学习初始时有非常多数学知识都已忘记。所以为了弄懂当中的内容查阅了非常多资料,所以里面应该会有引用其它帖子的小部分内容。假设原作者看到能够私信我。我会将您的帖子的地址付到以下。
3,假设有内容错误或不准确欢迎大家指正。
4,假设能帮到你,那真是太好了。
介绍
CART是在给定输入变量X条件下,输出随机变量Y的条件概率分布的学习方法。
CART如果决策树是二叉树,内部节点特征取值为“是”或“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。
这样决策树等价于递归的二分每一个特征(即使数据有多个取值,也把数据分成两部分)
CART算法由下面两步组成:
1)决策树生成:基于训练数据集生成决策树。生成的决策树要尽量大。
2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树。这是用损失函数最小作为剪枝的标准。
CART生成
决策树的生成即:递归构建二叉决策树的过程
对回归树:用平方误差最小化准则。进行特征选择,生成二叉树
对分类树:用基尼指数最小化准则,进行特征选择,生成二叉树
PS:基尼指数(Gini)代表了某一集合的不确定性,Gini越大。样本集合的不确定性就越大。这点和熵相似。
这里总结分类树。
分类树的生成 – 基尼指数
首先,须要注意。在计算概率分布的基尼指数时须要考虑不同的情况:
情况1:
如果有N个类,样本点属于第k个类的概率为Pk,则其基尼指数为:
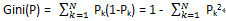
情况2:
对于二分类问题,若样本属于第一个类的概率为P,则概率分布的Gini为:
Gini(P)= 2P(1-P)
情况1的样例:
对于给定的样本集合D,Ck是D中属于第k个类的样本子集,N是类的个数,则GIni为:
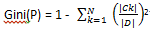
在上面2种情况的基础上:
若样本集合D依据特征A是否属于某一可能是a被切割成D1和D2两部分,即:
D1= { (x, y)∈D | A(x) = a }
D2= D - D1
那么在特征A的条件下,集合D的Gini为:
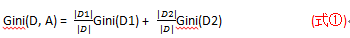
即:经A = a分隔后集合D的不确定性。
CART生成算法
描写叙述:
输入:
训练数据D。停止计算的条件
输出:
CART决策树
解:
依据训练数据集,从根节点開始。递归的对每一个节点进行下面操作来构建二叉决策树。
1。从节点的训练数据集D计算现有特征对该数据集的基尼指数(Gini)。此时,对每个特征A,对其可能取得每个值a,依据“样本A = a的结果是‘是’或‘否’”将D切割成D1。D2两部分。利用式①计算A = a 时的Gini。
2,在全部可能的特征A以及它们全部可能的切分点a中选择Gini最小的特征及其相应的切分点作为最优特征和最优切分点,然后根据最优特征与最优切分点从现节点生成两个子结点,最后将训练数据集根据特征分配到两个子结点中去。
3,对两个子结点递归的调用上面两步直至满足停止条件。
4。生成CART决策树。
PS:算法的停止条件是“节点的样本个数 < 预定阈值”或“样本集合的Gini < 预定阈值(样本基本属于同一类)”或“无很多其它特征”。
样例:
对“贷款申请样本数据表”,应用CART算法生成决策树。
(贷款申请样本数据表)
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别(是否能贷到款) |
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 很好 | 是 |
| 10 | 中年 | 否 | 是 | 很好 | 是 |
| 11 | 老年 | 否 | 是 | 很好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 很好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
解:
我们先对上表中的各个种类和特征做一个标记:
A1、A2、A3、A4 分别代表:年龄、有无工作、有无房子、信贷情况
1、2、3:表示年龄的青、中、老年
1、2:表示有房、有工作 和 无房、无工作
1、2、3:表示信贷情况很好、好和一般
1。求A1的Gini:

同理:
Gini(D,A1 = 2) = 0.48
Gini(D,A1 = 3) = 0.44
因为Gini(D, A1= 1) 和Gini(D, A1 = 3) 相等且最小。所以A1 = 1和A1 = 3均可作为A1的最优切分点。
2,而A2和A3仅仅有两个特征,那假设要用A2或A3来分类样本集合的话,那切分点就无疑仅仅有一个了,即A2和A3仅仅有一个切分点。
只是尽管A2和A3仅仅有一个切分点。但其Gini还是要计算的,由于要比較全部特征的Gini,从中选一个最小的作为第一次分类的最优特征和最优切分点。
于是:
Gini(D,A2 = 1) = 0.32
Gini(D,A3 = 1) = 0.27
3,同理A4的Gini例如以下:
Gini(D,A4 = 1) = 0.36
Gini(D,A4 = 2) = 0.47
Gini(D,A4 = 3) = 0.32
对A4来说,Gini(D, A4= 3) 是A4的最优切分点。
4, ∵ 在A1,A2。A3。A4中Gini(D, A3 =1) = 0.27最小
∴ 选择A3为最优特征。A3 = 1为最优切分点。
∴ 生成根节点A3和切分后的两个子结点(由于对A3来说,全部有房子的都能贷到款。所以对于切分后的两个子结点中的“有房子”这个节点来说已不用在切分(也没法在切分),所以这个节点是叶子节点)
5,对还有一个节点(无房子的那个节点)继续使用上面4步在A1,A2,A3中选择最优特征和最优切分点,结果是A2 = 1。且在此计算得知,全部节点均为叶子节点(均被全然分类– 无房子的样本中:有工作的全贷到款,没工作的全贷不到。
PS:这里没使用预定阈值。所以结束条件为:特征全被使用/样本数据被全然分类)
CART剪枝
有时由于学习到的决策树过于复杂(分的过于细),所以我们须要对决策树进行剪枝,即:通过在底端剪去一些子树。使决策树变小(变简单)。
剪枝算法有:
减少错误剪枝REP(ReducedError Pruning)
悲观错误剪枝PEP(Pessimistic ErrorPruning)
基本错误剪枝REP(Err-Based Pruning)
代价-复杂度剪枝CCP(Cost-ComplexityPruning)
最小错误剪枝MEP(Minimum ErrorPruning)
最小期望误判成本MECM(MininumExpected Costof Misclassification)
最小描写叙述长度MPL(MininumDescription Length)
这里总结代价-复杂度剪枝CCP(Cost-ComplexityPruning)。
代价-复杂度剪枝
就像CART生成算法使用基尼指数作为推断标准一样,这个算法使用“误差增益值”作为推断标准。
于是。又到记公式的时间了,Yeeee….(个鬼啊),对于决策树T的随意内部节点:
误差增益值

t:决策树T的随意部位节点
|NTt|:子树中包括的叶子节点个数。
(注意:是叶子节点)
R(t ):节点t的误差代价(假设该结点被剪枝)
R(t ) = r( t ) * P( t )
r(t ):节点t上的数据占全部数据的比例
eg:某节点的元素中有a个属于目标类,b个不属于,则r( t )= b / (a + b)
P(t ):节点t上的数据占全部数据的比例
eg:某节点有x个元素,全部的节点一共同拥有y个元素。则P( t ) = x / y
R(Tt ):子树的误差代价,假设该节点不被剪枝。那它等于子树Tt上全部叶子节点的误差代价之和。
用一个样例说明下上面的公式吧。
一个决策树中一共同拥有60个元素,而当中的一个非叶子结点T4。例如以下图所看到的,求其不属于类1的误差增益值
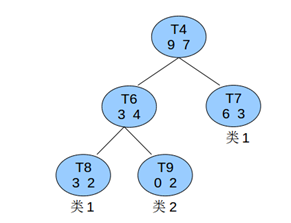
PS:上图说明:
节点T7:6个元素属于类1、3个不属于
节点T8:3个元素属于类1、2个不属于
节点T9:2个元素属于类1、0个不属于
解:
1,求R( t )
对节点T4,由于全部的数据一共60条。所以:
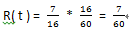
2。求 |NTt|
∵ 子树T4共同拥有3个叶子节点:T7、T8、T9
∴ |NTt| = 3
3,求R( Tt )
∵ R( Tt ) = 子树Tt上全部叶子节点的误差代价之和
∴
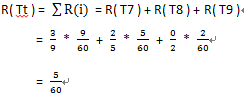
4,求g( t )
综上:
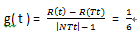
上面是求一个非叶子节点的过程,面对实际的决策树就是递归求出全部非叶子结点的g( t ) 后找到最小的那个非叶子节点,然后令其左右孩子为NULL。
PS:当有多个非叶子结点的g(t ) 同一时候最小时,取|NTt|最大的那个进行剪枝。
于是,CART剪枝算法例如以下。
CART剪枝算法
输入:CART算法生成的决策树T0。
输出:最优决策树Ta。
解:
1,设k = 0,T = T0
2,设a = +∞
3,自下而上的对各内部节点t计算g(t),然后令a =min(a, g(t) )
4,自上而下的訪问内部节点t,若有g(t) = a,则进行剪枝。并对叶子节点t以多数表决法来决定其类,得到树T。
5,设k = k + 1。ak = a。Tk = T
6,若T不是由根节点单独构成的树,则返回步骤4
7,使用交叉验证法再子树序列T0、T1、…、Tn中选最优子树Ta。
#-*-coding:utf-8-*-
# LANG=en_US.UTF-8
# CART 算法
# 文件名称:CART.py
#
import sys
import math
import copy
dict_all = {
# 1: 青年;2:中年;3:老年
'_age' : [
1, 1, 1, 1, 1,
2, 2, 2, 2, 2,
3, 3, 3, 3, 3,
],
# 0:无工作;1:有工作
'_work' : [
0, 0, 1, 1, 0,
0, 0, 1, 0, 0,
0, 0, 1, 1, 0,
],
# 0:无房子;1:有房子
'_house' : [
0, 0, 0, 1, 0,
0, 0, 1, 1, 1,
1, 1, 0, 0, 0,
],
# 1:信贷情况一般。2:好;3:很好
'_credit' : [
1, 2, 2, 1, 1,
1, 2, 2, 3, 3,
3, 2, 2, 3, 1,
],
}
# 0:未申请到贷款;1:申请到贷款
_type = [
0, 0, 1, 1, 0,
0, 0, 1, 1, 1,
1, 1, 1, 1, 0,
]
# 二叉树结点
class BinaryTreeNode( object ):
def __init__( self, name=None, data=None, left=None, right=None, father=None ):
self.name = name
self.data = data
self.left = left
self.right = left
self.father = father
# 二叉树遍历
class BTree(object):
def __init__(self,root=0):
self.root = root
# 中序遍历
def inOrder(self,treenode):
if treenode is None:
return
self.inOrder(treenode.left)
print treenode.name, treenode.data
self.inOrder(treenode.right)
# 获得种类中中每个特征的个数,以及该特征中_type = 1的个数 和 其它特征中_type = 1的个数
# 输入:字典中的当前种类的字典。列表 _type。待分析种类列表中的元素序号
# 输出字典:{ '特征': [特征的个数, 该特征中_type = 1(能贷到款)的个数, 其它种特征type = 1的个数] }
# eg,对于 _age:
# 由于其青中老年个 5 个,且青年中能带到款的有2个,中年和老年能贷到款的分别为3个和4个,所以输出:
# {'1': [5, 2, 7], '2': [5, 3, 6], '3': [5, 4, 5]}
def get_value_type_num( _data, _type_list, num_list ):
value_dict = {}
tmp_type = ''
tmp_item = ''
for num in num_list:
item = str( _data[num] )
if tmp_item != item:
if item in value_dict.keys():
value_dict[item][0] = value_dict[item][0] + 1
if _type_list[num] == 1:
value_dict[item][1] = value_dict[item][1] + 1
else:
if _type_list[num] == 1:
value_dict[item] = [1.0, 1.0, 0.0]
else:
value_dict[item] = [1.0, 0.0, 0.0]
tmp_item = item
else:
value_dict[item][0] = value_dict[item][0] + 1
if _type_list[num] == 1:
value_dict[item][1] = value_dict[item][1] + 1
for num1 in xrange( len(value_dict) ):
for num2 in xrange( len(value_dict) ):
if num1 == num2: continue
value_dict[value_dict.keys()[num1]][2] += value_dict[value_dict.keys()[num2]][1]
return value_dict
# 获得种类中不同特征包括的元素序号
# 如:相应 dict_all 中的 _age,其包括青中老年。若 num_list 为 [0..15]。则输出:
# {'1': [0, 1, 2, 3, 4], '2': [5, 6, 7, 8, 9], '3': [10, 11, 12, 13, 14]}
def get_value_type_no( data, data_type, num_list ):
value_dict = {}
tmp_item = ''
for num in num_list:
item = str( data[data_type][num] )
if tmp_item != item:
if item in value_dict.keys():
value_dict[item].append( num )
else:
value_dict[item] = [num,]
else:
value_dict[item].append( num )
return value_dict
# 使用 gini 获得最优切分点
def get_cut_point_by_gini( _dict_all, _type_list, num_list, threshold ):
target_type = ''
target_feature = ''
target_gini = 1000000.0
for data_key in _dict_all:
value_dict = get_value_type_num( _dict_all[data_key], _type_list, num_list )
tmp_feature = ''
gini = 1000000.0
# 通过计算当前种类的每个特征的 gini 值,来获得该种类中 gini 最小的那个特征
for value_key in value_dict.keys():
all_feature_num = len(_dict_all[data_key])
this_feature_num = value_dict[value_key][0]
other_feature_num = all_feature_num - this_feature_num
this_feature_yes_num = value_dict[value_key][1]
other_feature_yes_num = value_dict[value_key][2]
# 计算 gini
tmp_gini = float( '%.2f' % \
( \
(
( this_feature_num / all_feature_num ) * \
2 * \
( this_feature_yes_num / this_feature_num ) * \
( 1 - this_feature_yes_num / this_feature_num ) \
) + \
(
( other_feature_num / all_feature_num ) * \
2 * \
( other_feature_yes_num / other_feature_num ) * \
( 1 - other_feature_yes_num / other_feature_num ) \
) \
) )
# 获得该种类中 gini 最小的那个特征
if float(gini) - tmp_gini > 0.0:
gini = tmp_gini
tmp_feature = value_key
if gini < threshold:
return data_key, tmp_feature, 'over'
# 通过对照所有种类中 gini 最小的特征,来获得 gini 最小的特征的种类, 该种类以及该种类的特征就是切分点
if float(target_gini) - float(gini) > 0.0:
target_type = data_key
target_feature = tmp_feature
return target_type, target_feature, 'continue'
# CART 算法
def CART( data, type_list, threshold ):
# 进行分类
def classify( root, note_name, note_data, note_type ):
# 将'特征可能值名字'追加到 root.name 中
# 将[样本序号的列表]合并到 root.data 中
root.name.append( note_name )
root.data.extend( note_data )
# note_type=='exit' 意味着当前的数据所有属于某一类,不用在分类了
if not data or note_type == 'exit':
return
target_type, target_feature, step = get_cut_point_by_gini( data, type_list, note_data, threshold )
feature_dict = get_value_type_no( data, target_type, note_data )
# 从样本集合中将该特征删除
del data[target_type]
# 准备左子节点和右子节点,节点的 name 和 data 是个空列表
root.left = BinaryTreeNode( [], [] )
root.right = BinaryTreeNode( [], [] )
# 计算“特征字典”中各个集合中是属于“能贷贷款”的多还是“不能贷贷款”的多
# 假设是前者:
# 递归调用 classify,形成左子节点
# 假设是后者:
# 递归调用 classify。形成右子节点
for key in feature_dict.keys():
num_yes = 0; num_no = 0
for num in feature_dict[key]:
if type_list[num] == 1:
num_yes = num_yes + 1
elif type_list[num] == 0:
num_no = num_no + 1
else:
print 'ERROR: wrong type in _type'
exit()
note_type = 'not_exit'
if num_yes == 0 or num_no == 0 or step == 'over':
note_type = 'exit'
if key == target_feature:
classify( root.left, '%s:%s' % (target_type, key), feature_dict[key], note_type )
else:
classify( root.right, '%s:%s' % (target_type, key), feature_dict[key], note_type )
return root
tmp_list = []
for num in xrange( len(dict_all[dict_all.keys()[0]]) ):
tmp_list.append( num )
return classify( BinaryTreeNode( [], [] ), 'root', tmp_list, 'not_exit' )
class cost_complexity_pruning_parm( object ):
def __init__( self, sum_num ):
# 一共同拥有多少个元素
self.sum_num = sum_num
# 某个节点的元素数
self.node_num = 0.0
# 某节点的叶子节点数量
self.leaf_node_num = 0.0
# 某节点的"错误分类"的元素数量
self.node_data_error_num = 0.0
# R(Tt)
self.Rtt = 0.0
# 节点的误差率增益值 g(t) 的字典,格式是{'节点名字': 节点的误差率增益值}
self.error_rate_gain_dict = {}
# 计算 R(Tt)
# 參数:self, 该节点的"错误分类"的元素数量, 该节点的元素数
def count_Rtt( self, node_item_num, node_err_num ):
self.Rtt = self.Rtt + ( (node_err_num/node_item_num) * (node_item_num/self.sum_num) )
# 制作误差率增益值 g(t) 的字典
# g(t) = R(t) - R(Tt) / ( |NTt| - 1 )
# 參数:self, key, 该节点的"错误分类"的元素数量, 该节点的元素数
def make_error_rate_gain_value_dict( self, key, node_item_num, node_err_num ):
rt = node_err_num / self.sum_num
pt = node_item_num / self.sum_num
Rt = rt * pt
NTt = self.leaf_node_num
self.error_rate_gain_dict[key] = float( '%.3f' % float((Rt-self.Rtt)/(NTt-1)) )
def print_error_rate_gain( self ):
print self.error_rate_gain_dict
def get_error_rate_gain_dict( dict_all_pruning, type_list, tree, cls ):
# 对某个节点求其误差率增益值
def analyze_node( node, node_name, cls ):
# 假设是叶子节点。则叶子节点数 + 1,并计算 R(Tt)
if not node.left and not node.right:
cls.leaf_node_num = cls.leaf_node_num + 1
dict_key = node.name[0].split(':')[0]
value_dict = get_value_type_num( dict_all_pruning[dict_key], type_list, node.data )
dict_key = node.name[0].split(':')[1]
cls.count_Rtt( value_dict[dict_key][0], value_dict[dict_key][0] - value_dict[dict_key][1] )
return
# 兴许遍历
analyze_node( node.left, None, cls )
analyze_node( node.right, None, cls )
# 假设遍历到 back_order 传进来的 node。则计算其“误差率增益值”
if node.name[0] == node_name:
dict_key = node.name[0].split(':')[0]
# 获得 get_value_type_num 返回的字典(里面包括了该节点的元素总数和"正确分类"的元素数)
value_dict = get_value_type_num( dict_all_pruning[dict_key], type_list, node.data )
# 计算"错误分类"的元素数
dict_key = node.name[0].split(':')[1]
cls.make_error_rate_gain_value_dict( node.name[0], value_dict[dict_key][0], value_dict[dict_key][0] - value_dict[dict_key][1] )
return cls.leaf_node_num
# 兴许遍历决策树
def back_order( node, cls ):
# 假设是叶子节点。则返回
if not node.left and not node.right: return
back_order( node.left, cls )
back_order( node.right, cls )
# 假设是根节点,则返回
if node.name[0] == 'root': return
cls.leaf_node_num = 0
# 反之。求该结点的误差率增益值
analyze_node( node, node.name[0], cls )
back_order( tree.root, cls )
def cost_complexity_pruning( dict_all_pruning, type_list, tree, cls ):
# 进行剪枝
def pruning( node, target_node_name ):
if not node.left and not node.right: return
if node.name[0] == target_node_name:
node.left = None
node.right = None
return
pruning( node.left, target_node_name )
pruning( node.right, target_node_name )
# 获得误差率增益值 g(t) 的字典
get_error_rate_gain_dict( dict_all_pruning, type_list, tree, cls )
#cls.print_error_rate_gain()
# 找出误差率增益值最小的节点
min_error_rate_gain = 10000.0
min_error_rate_gain_node = ''
for key in cls.error_rate_gain_dict.keys():
error_rate_gain = cls.error_rate_gain_dict[key]
if error_rate_gain < min_error_rate_gain:
min_error_rate_gain = error_rate_gain
min_error_rate_gain_node = key
pruning( tree.root, min_error_rate_gain_node )
# 阈值
# 假设使用 threshold = 0.3。那在使用 house 将样本数据分类后就停止了
# threshold = 0.3
threshold = 0.1
dict_all_cart = copy.deepcopy( dict_all )
root = CART( dict_all_cart, _type, threshold )
bt = BTree( root )
bt.inOrder( bt.root )
print '\n--------------\n'
# 这一步应该使用训练数据
dict_all_pruning = copy.deepcopy( dict_all )
cost_complexity_pruning( dict_all_pruning, _type, bt, cost_complexity_pruning_parm(len(dict_all_pruning[dict_all_pruning.keys()[0]])) )
bt.inOrder( bt.root )
# 剪枝前
# root
# / \
# house:1 house:0
# / \
# work:1 work:0
#
# 剪枝后(由于仅仅有一个非叶子节点"house:0",所以仅仅能剪这个节点了)
# root
# / \
# house:1 house:0
# 当然,这里剪这个不适合。由于剪枝前的决策树既不复杂也全然划分了样本数据,只是这里仅仅是实现剪枝算法,所以不考虑决策树适不适合剪枝。
# 顺便一提,"剪枝前的决策树在未用完种类的情况下全然划分了样本数据"能够作为适不适合剪枝的推断条件之中的一个。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









