






原文:http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/
作者:Ilya Katsov
相当长一段时间以来。大数据社区已经普遍认识到了批量数据处理的不足。
非常多应用都对实时查询和流式处理产生了迫切需求。近期几年,在这个理念的推动下。催生出了一系列解决方式。Twitter Storm,Yahoo S4,Cloudera Impala,Apache Spark和Apache Tez纷纷增加大数据和NoSQL阵营。本文尝试探讨流式处理系统用到的技术,分析它们与大规模批量处理和OLTP/OLAP数据库的关系。并探索一个统一的查询引擎怎样才干同一时候支持流式、批量和OLAP处理。
在Grid Dynamics,我们面临的需求是构建一个流式数据处理系统。每天须要处理80亿事件,并提供容错能力和严格事务性,即不能丢失或反复处理事件。
新系统是现有系统的补充和继任者。现有系统基于Hadoop,数据处理延迟高,并且维护成本太高。
此类需求和系统相当通用和典型。所以我们在下文将其描写叙述为规范模型,作为一个抽象问题陈述。
下图从高层次展示了我们的生产环境概况:
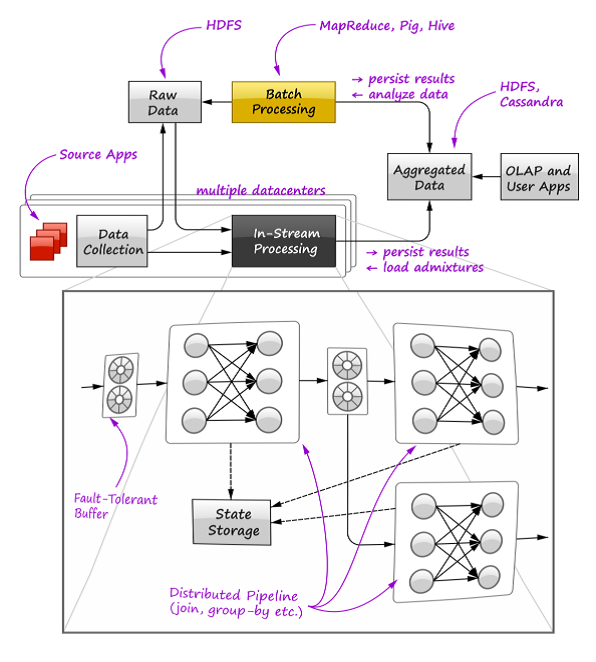
这是一套典型的大数据基础设施:多个数据中心的各个应用程序都在生产数据,数据通过数据收集子系统输送到位于中心设施的HDFS上,然后原始数据通过标准的Hadoop工具栈(MapReduce,Pig,Hive)进行汇总和分析,汇总结果存储在HDFS和NoSQL上,再导出到OLAP数据库上被定制的用户应用訪问。我们的目标是给全部的设施配备上新的流式处理引擎(见图底部)。来处理大部分密集数据流。输送预汇总的数据到HDFS,降低Hadoop中原始数据量和批量job的负载。
流式处理引擎的设计由下面需求驱动:
- SQL-like功能:引擎能运行SQL-like查询,包含在时间窗体上的join和各种聚合函数。用来实现复杂的业务逻辑。
引擎还能处理从汇总数据中载入的相对静态数据(admixtures)。
更复杂的多道次数据挖掘算法不在短期目标范围内。
- 模块化和灵活性:引擎绝不仅是简单运行SQL-like查询,然后对应的管道就被自己主动创建和部署,它应该能通过连接各模块。非常方便地组合出更复杂的数据处理链。
- 容错:严格容错是引擎的基本需求。如草图中,一种可能的设计是使用分布式数据处理管道来实现join、汇总或者这些操作组成的链,再通过容错的持久化buffer来连接这些管道。利用这些buffer,能够实现公布/订阅的通信方式。能够非常方便地添加或者移除管道,这样最大程度提升了系统的模块化。
管道也能够是有状态的。引擎的中间件提供持久化存储来启用状态检查点机制。
全部这些主题将在本文兴许章节进行讨论。
- 和Hadoop交互:引擎应该能接入流式数据和来自Hadoop的数据。作为HDFS之上的定制化查询引擎提供服务。
- 高性能和便携性:即使在最小规模的集群上,系统也能每秒传递成千上万次消息。引擎理应是紧凑高效的,能够被部署在多个数据中心的小规模集群上。
为了弄明确怎样实现这样一个系统,我们讨论下面主题:
- 首先,我们讨论流式数据处理系统。批量处理系统和关系型查询引擎之间的关系,流式处理系统可以大量用到其它类型系统中已经应用的技术。
- 其次,我们介绍一些在构建流式处理框架和系统中用到的模式和技术。
此外,我们调研了当下新兴技术,提供一些实现上的小贴士。
The article isbased on a research project developed at Grid Dynamics Labs. Much of the creditgoes to Alexey Kharlamov and Rafael Bagmanov who led the project and othercontributors: Dmitry Suslov, Konstantine Golikov, Evelina Stepanova, AnatolyVinogradov, Roman Belous, and Varvara Strizhkova.
分布式查询处理基础
分布式流式数据处理显然和分布式关系型数据库有联系。很多标准查询处理技术都能应用到流式处理引擎上来,所以理解分布式查询处理的经典算法,理解它们和流式处理以及其它流行框架比方MapReduce的关系,是很实用的。
分布式查询处理已经发展了数十年,是一个非常大的知识领域。我们从一些主要技术的简明概述入手,为下文的讨论提供基础。
分区和Shuffling
分布式和并行查询处理重度依赖数据分区,将大数据打散分成多片让各个独立进程分别进行处理。
查询处理可能包含多步。每一步都有自己的分区策略。所以数据shuffling操作广泛应用于分布式数据库中。
虽然用于选择和投射操作的最优分区须要一定技巧(比方在范围查询中),但我们能够如果在流式数据过滤中,使用哈希分区在各处理器中分发数据足以行得通。
分布式join不是那么简单,须要深入研究。在分布式环境中。并行join通过数据分区实现,也就是说,数据分布在各个处理器中,每一个处理器执行串行join算法(比方嵌套循环join或者排序-合并join或者哈希join)处理部分数据。终于结果从不同处理器获取合并得来。
分布式join主要採用两种数据分区技术:
- 不相交数据分区
- 划分-广播join
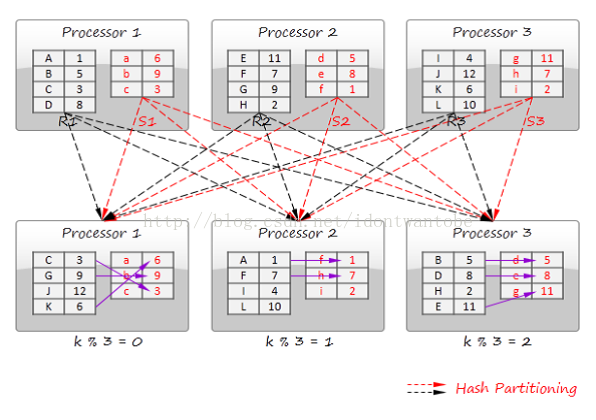
不相交数据分区技术使用join key将数据shuffle到不同分区,分区数据互不重叠。
每一个处理器在自己分区数据上运行join操作,不同处理器的结果简单拼接产生终于结果。考虑R和S数据集join的样例。它们以数值键k进行join,以简单的取模函数进行分区。
(如果数据基于某种策略。已经分布在各个处理器上):
下图演示了划分-广播join算法。数据集R被划分成多个不相交的分区(图中的R1,R2和R3)。数据集S被拷贝到全部的处理器上。在分布式数据库中。划分操作本身通常不包括在查询过程中,由于数据初始化已经分布在不同节点中。
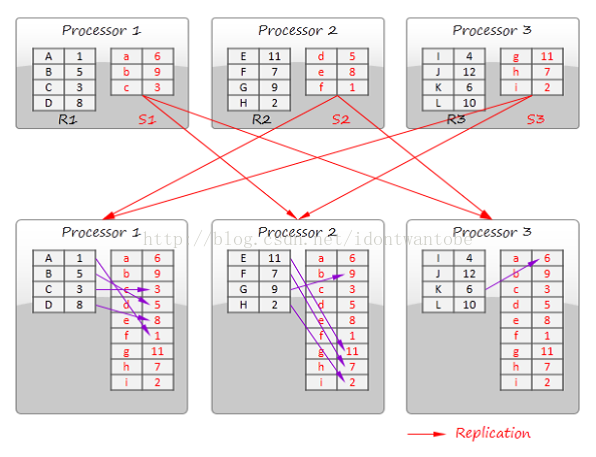
这样的策略适用于大数据集join小数据集,或者两个小数据集之间join。流式数据处理系统能应用这样的技术,比方将静态数据(admixture)和数据流进行join。
Group By处理过程也依赖shuffling。本质上和MapReduce是类似的。考虑下面场景,数据集依据字符字段分组,再对每组的数值字段求和:

在这个样例中。计算过程包括两步:本地汇总和全局汇总。这基本和Map/Reduce操作相应。本地汇总是可选的。原始数据能够在全局汇总阶段传输、shuffle、汇总。
本节的总体观点是。上面的算法都天然能通过消息传递架构模式实现。也就是说,查询运行引擎能够看做是由消息队列连接起来的分布式网络节点组成。概念上和流式处理管道是类似的。
管道
前一节中。我们注意到非常多分布式查询处理算法都类似消息传递网络。
可是。这不足以说明流式处理的高效性:查询中的全部操作应该形成链路,数据流平滑通过整个管道,也就是说。不论什么操作都不能堵塞处理过程,不能等待一大块输入而不产生不论什么输出。也不用将中间结果写入硬盘。
有一些操作比方排序,天然不兼容这样的理念(显而易见,排序在处理完输入之前都不能产生不论什么输出),但管道算法适用于非常多场景。一个典型的管道例如以下图所看到的:
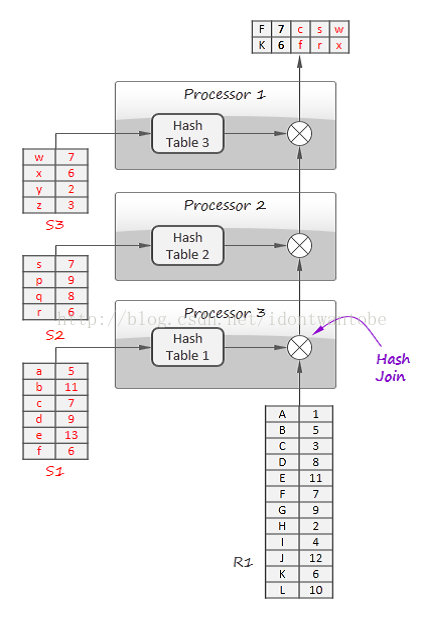
在这个样例中,使用三个处理器哈希join四个数据集:R1,S1。S2和S3。首先并行给S1,S2和S3建立哈希表,然后R1元组逐个流过管道,从S1。S2和S3哈希表中查找相匹配记录。流式处理天然能使用该技术实现数据流和静态数据的join。
在关系型数据库中,join操作还会使用对称哈希join算法或其它高级变种。
对称哈希join是哈希join算法的泛化形式。正常的哈希join至少须要一个输入全然可用才干输出结果(当中一个输入用来建立哈希表),而对称哈希join为两个输入都维护哈希表,当数据元组抵达后。分别填充:
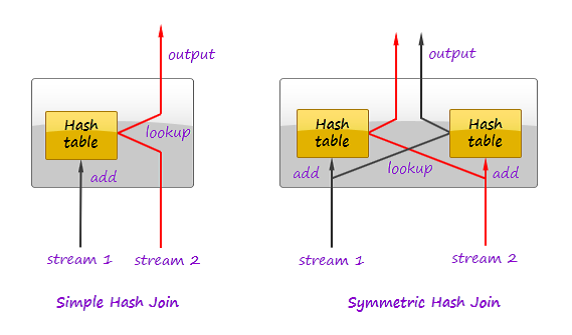
元组抵达时,先从另外一个数据流相应的哈希表查找。假设找到匹配记录,则输出结果。然后元组被插入到自身数据流相应的哈希表。
当然。这样的算法对无限流进行全然join不是太有意义。非常多场景下。join都作用于有限的时间窗体或者其它类型的缓冲区上。比方用LFU缓存数据流中最经常使用的元组。
对称哈希join适用于缓冲区大过流的速率,或者缓冲区被应用逻辑频繁清除,或者缓存回收策略不可预见的场景。在其它情况下。使用简单哈希join已足够。由于缓冲区始终是满的,也不会堵塞处理流程:
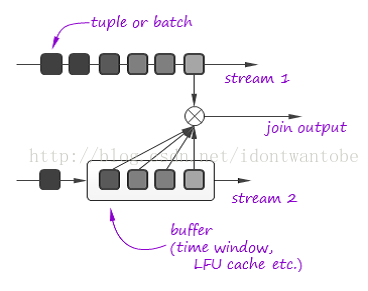
值得注意的是。流式处理往往须要採用复杂的流关联算法,记录匹配不再是基于字段相等条件,而是基于评分度量,在这样的场景下。须要为两个流维护更为复杂的缓存体系。
流式处理模式
前一节中,我们讨论了一些在大规模并行流处理中用到的标准查询技术。
从概念层面上来看,似乎一个高效分布式数据库查询引擎能胜任流式处理,反之亦然,一个流式处理系统也应该能充当分布式数据库查询引擎的角色。Shuffling和管道是分布式查询处理的关键技术,并且通过消息传递网络可以自然而然地实现它们。
然而真实情况没那么简单。
在数据库查询引擎中。可靠性不是那么关键,由于一个仅仅读查询总是可以被又一次执行,而流式系统则必须重点关注消息的可靠处理。在本节中,我们讨论流式系统保证消息传递的技术。和其它一些在标准查询处理中不那么典型的模式。
流回放
在流式处理系统中,时光倒流和回放数据流的能力至关重要。由于下面原因:
- 这是确保数据正确处理的唯一方式。即使数据处理管道是容错的,也难以确保数据处理逻辑是无缺陷的。人们总是面临修复和又一次部署系统的需求,须要在新版本号的管道上回放数据。
- 问题调查须要即席查询。假设发生了问题,人们可能须要增加日志或者改动代码,在产生问题的数据上重跑系统。
- 即使错误不常发生。即使系统整体上是容错的,流式处理系统也必须设计成在错误发生时可以从数据源中又一次读取特定消息。
因此,输入数据通常通过缓冲区从数据源流入流式管道,同意client在缓冲区中前后移动读取指针。
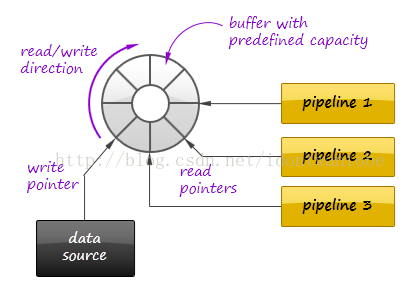
Kafka消息队列系统就实现了这样一个缓冲区,支持可扩展分布式部署和容错,同一时候提供高性能。
流回放要求系统设计至少考虑下面需求:
- 系统可以存储提前定义周期内的原始数据。
- 系统可以撤销一部分处理结果。回放相应的输入数据。产出新版本号结果。
- 系统可以高速倒回,回放数据。然后追上源源不断的数据流进度。
血缘跟踪
在流式系统中,事件流过一连串的处理器直到终点(比方外部数据库)。每一个输入事件产生一个由子事件节点(血缘)构成的有向图,有向图以终于结果为终点。
为了保障数据处理可靠性,整个图都必须被成功处理,并且在失败的情况下能重新启动处理过程。
实现高效血缘跟踪是一个难题。我们先介绍Twitter Storm是怎样跟踪消息,保障“至少一次”消息处理语义:
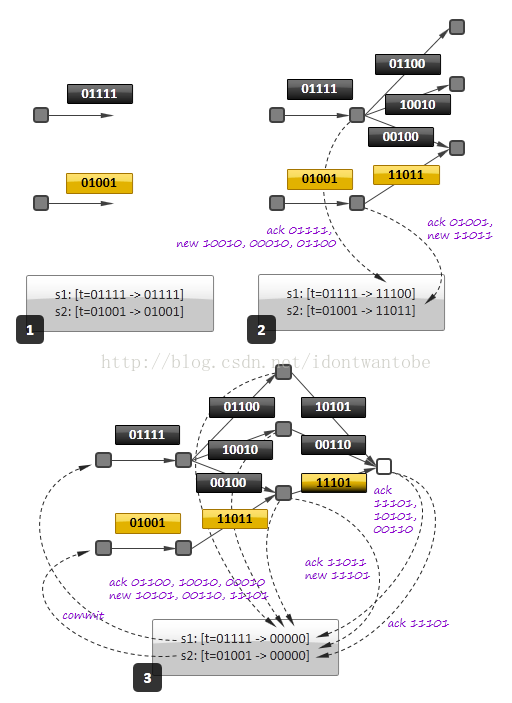
- 数据源(数据处理图的首个节点)发射的全部事件都标记上一个随机的eventID。框架为每一个数据源的初始事件都维护了一个[eventIDàsignature]的键值对集合。当中signature以eventID初始化。
- 下游节点接收到初始事件后。能产生0个或者多个事件,每一个事件携带自身的随机eventID和初始事件的eventID。
- 假设事件被图中下一个节点成功接收和处理。这个节点会更新初始事件的signature,规则是将初始signature与a)输入事件的ID和b)产生的全部事件的ID做异或。如图中第二部分,事件01111产生事件01100,10010和00010。所以事件01111的signature变成11100(=01111(初始值)xor 01111 xor 01100 xor 10010 xor 00010)。
- 一个事件也能基于多个输入事件生成。
这样的情况下。事件关联到多个初始事件,携带多个初始ID(图中第三部分黄色背景事件)。
- 事件的signature变为0代表事件被成功处理。最后一个节点确认图中的最后一个事件成功处理,并且不再往下游发送新的事件。
框架给事件源节点发送提交消息(如图第三部分)。
- 框架定期遍历初始事件表,查找尚未全然处理的事件(即signature不为0的事件)。这些事件被标记为失败。框架请求源节点回放事件。(译者注:Storm消息回放不是自己主动的,能够在消息发送时加上消息ID參数,然后依据失败的消息ID自行处理回放逻辑,一般Spout对接消息队列系统,利用消息队列系统的回放功能。)
- 值得注意的是,因为异或操作的可交换特性,signature的更新顺序无关紧要。在下图中。第二部分中的确认操作能够发生在第三部分之后,这让全然的异步处理成为可能。
- 还须要注意的是该算法不是严格可靠的——一些ID的组合可能偶然导致signature变为0。
可是64位长的ID足以保证极低的错误概率,出错概率大概是2^(-64),在大多数应用中这都是能够接受的。算法的主要长处是仅仅须要少量内存就能够保存下signature表。
以上实现非常优雅,具有去中心化特性:每一个节点独立发送确认消息。不须要一个中心节点来显式跟踪血缘。
然而。对于维护了滑动窗体或其它类型缓冲区的数据流,实现事务处理变得比較困难。比方,滑动窗体内可能包括成千上万个事件。非常多事件处于未提交或计算中状态,须要频繁持久化,管理事件确认过程难度非常大。
Apache Spark[3]使用的是第二种实现方法,其想法是把终于结果看作是输入数据的处理函数。为了简化血缘跟踪,框架分批处理事件,结果也是分批的,每一批都是输入批次的处理函数。
结果能够分批并行计算,假设某个计算失败,框架仅仅要重跑它即可。考虑下面样例:
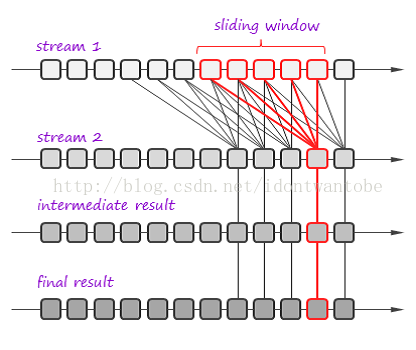
在这个样例中,框架在滑动窗体上join两个流。然后结果再经过一个处理阶段。框架把流拆分成批次,每一个批次指定ID,框架随时都能依据ID获取对应批次。
流式处理被拆分为一系列事务,每一个事务处理一组输入批次,使用处理函数转换数据,并保存结果。在上图中,红色加亮部分代表了一次事务。假设事务失败,框架重跑它,最重要的是,事务是能够并行的。
这样的方式简洁而强大,实现了集中式事务管理,并天然提供“仅仅运行一次”消息处理语义。
这样的技术还同一时候适用于批量处理和流式处理,由于无论输入数据是否是流式的,都把它们拆分成一系列批次。
状态检查点
前一节,我们在血缘跟踪算法中使用签名(校验和)提供了“至少一次”消息传递语义。
该技术改善了系统的可靠性,但留下了至少两个开放式问题:
- 非常多场景都要求“仅仅运行一次”处理语义。比方,假设某些消息被发送两次。计数器管道会统计出错误的结果。
- 处理消息时。管道中的节点计算状态被更新。
计算状态须要持久化或者复制,以免节点失败时发生状态丢失。
Twitter Storm使用下面协议解决这些问题:
- 事件被分组成批次。每一个批次关联一个事务ID。
事务ID单调递增(比方。第一批事件ID为1,第二批ID为2。诸如此类)。假设管道处理某个批次时失败,这批数据以相同的事务ID又一次发送。
- 首先。框架通知管道中节点新事务启动。然后。框架发送这一批次数据通过管道。
最后。框架通知事务已完毕,全部的节点提交状态变更(比方更新到外部数据库)。
- 框架保证全部事务的提交是有序的,比方事务2不能先于事务1被提交。这保证了处理节点能够使用下面逻辑持久化状态变更:
- 最新的事务ID和状态被持久化
- 假设框架请求提交的当前事务ID和数据库中ID不同。状态被更新,比方数据库中的计数器被添加。由于事务的强有序性,所以每一个批次数据仅仅会更新一次。
- 假设当前事务ID和数据库中ID同样,那么这是这个批次数据的回放,节点会忽略这次提交。节点应该已经处理过这个批次。并更新过状态,而事务可能是由于管道中其它部分出错而失败。
- 有序提交对实现“仅仅运行一次”处理语义至关重要。然而,事务严格顺序处理不太可取,由于下游全部节点处理完毕之前,管道中的首个节点都处于空暇状态。通过并行处理事务过程,串行化提交能缓解这个问题。例如以下图所看到的:
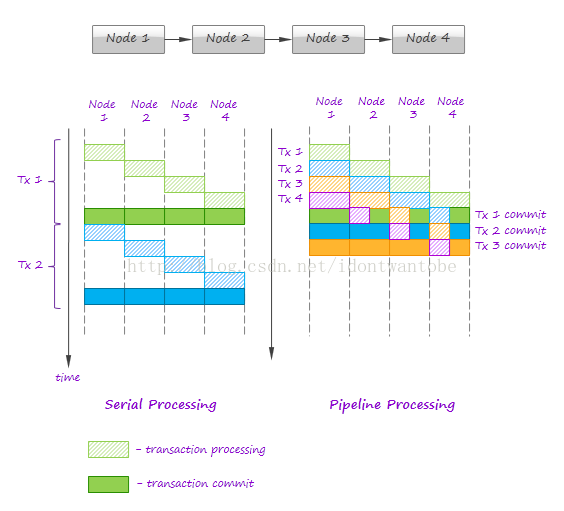
假设数据源是容错的,可以被回放,那么事务能保障“仅仅运行一次”处理语义。可是,即使使用大容量分批处理,持久化状态更新也会导致严重的性能退化。
所以。应该尽可能降低或者避免中间计算结果状态。
补充说明的是,状态写入也能通过不同方式实现。最直接的方式是在事务提交过程中,把内存中状态拷贝到持久化存储。
这样的方式不适用于大规模状态(比方滑动窗体等)。还有一种可选方式是存储某种事务日志,比方将原始状态转化为新状态的一系列操作日志(对滑动窗体来说,可以是一组加入和清理事件)。尽管这样的方式须要从日志中重建状态,灾难恢复变得更麻烦,但在非常多场景下。它都能提供更好的性能。
可加性和草图
中间和终于计算结果的可加性非常重要,能极大地简化流式数据处理系统的设计,实现,维护和恢复。可加性意味着大范围时间或者大容量数据分区的计算结果可以由更小的时间范围或者更小的分区结果组合而来。比方,每日PV量等于每小时PV量之和。
状态可加性同意将数据流切分处理,如我们在前一节讨论,每一个批次都可以被独立计算/重算,这有助于简化血缘跟踪和降低状态维护的复杂性。
实现可加性往往不轻松:
- 有一些场景,可加性确实非常easy。比方简单计数是可加的。
- 在一些场景下。须要存储一些附加信息来实现可加性。比方,系统统计网店每小时平均购买价格,虽然每日平均购买价格不等于对24个小时平均购买价格再求平均,可是。如果系统还存储了每一个小时的交易量,就能轻易算出每日平均购买价格。
- 在其它场景下。实现可加性非常困难甚至于不可能。比方,系统统计某个站点的独立訪客数据。如果昨天和今天都有100个独立用户訪问了站点。但这两天的独立訪问用户之和可能是100到200之间的不论什么值。
我们不得不维护用户ID列表。通过ID列表的交集和并集操作来实现可加性。
用户ID列表的大小和处理复杂性和原始数据相当。
草图(Sketches)是将不可加值转换为可加值的有效方法。在上面的样例中,ID列表能够被紧凑的可加性统计计数器取代。计数器提供近似值而不是精确值,但在非常多应用中都是能够接受的。草图在互联网广告等特定领域非常流行,能够被看做一种独立的流式处理模式。草图技术的深入综述请见[5]。
逻辑时间跟踪
流式计算中一般会依赖时间:汇总和Join一般作用在滑动时间窗体上;处理逻辑往往依赖事件的时间间隔等。显然,流式处理系统应该有自己的时间视图,而不应该使用CPU挂钟时间。由于发生问题时,数据流和特定事件会被回放。所以实现正确的时间跟踪并不简单。
通常。全局的逻辑时间概念能够通过下面方式实现:
- 原始系统产生的全部事件都应该标记上时间戳。
- 管道中的处理器处理流时,跟踪最大时间戳,假设持久化的全局时钟落后了,就把它更新为最大时间戳。其它处理器与全局时钟进行时间同步
- 在数据回放时。重置全局时钟。
持久化存储汇总
我们已经讨论了持久化存储能够用于状态检查点,但这不是流式系统引入外部存储的唯一作用。考虑使用Cassandra在时间窗体上join多个数据流的场景。
不用再维护内存中的事件缓冲区,我们能够把全部数据流的传入事件保存到Casandra中,使用join key作为row key,如图所看到的:
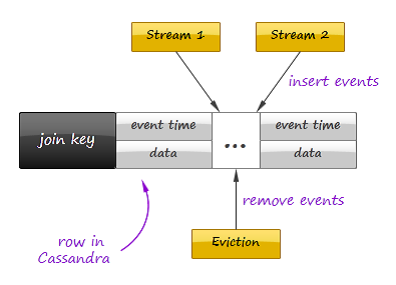
在还有一边,第二个处理器定期遍历数据记录。组装和发送join后的记录,清理超出时间窗体的事件。
Cassandra还能够依据时间戳排序事件来加速处理过程。
不对的实现会让整个流式数据处理过程功亏一篑——即使使用Cassandra或者Redis等高速存储系统,单独写入每条数据也会引入严重的性能瓶颈。
还有一方面,使用存储系统提供了更完好的状态持久化功能。假设应用批量写入等优化手段,在非常多场景下,也能达成可接受的性能目标。
滑动窗体聚合
流式数据处理常常处理 “过去10分钟流的某个数据值求和是多少” 等类似查询,即时间窗体上的连续查询。针对这类查询,最直接的解决方式是分别计算各个时间窗体的sum等聚合函数。非常显然,这样的方案不是最优的。由于两个连续的时间窗体实例具有高度相似性。
假设时刻T的窗体包括样本{s(0),s(1),s(2),...,s(T-1),s(T)},那么时刻T+1的窗体就包括{s(1),s(2),s(3)...,s(T),s(T+1)}。观察可知能够使用增量处理。
时间窗体之上的增量计算也被广泛应用在数字信号处理中。包含软件和硬件。典型样例是计算sum值。
假设当前时间窗体的sum值已知,那么下次时间窗体的sum值就能通过加上新的样本和减去窗体中最老的样本得出。
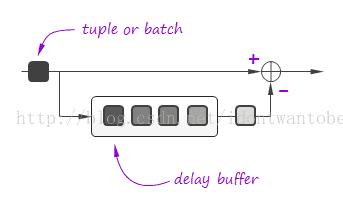
类似技术不仅能用于求和和乘积等简单聚合函数,也能用于更复杂的转换过程。比方。SDFT(滑动离散傅里叶变换)算法[4]就比对每一个窗体使用FFT(高速傅里叶变换)算法要高效得多。
查询处理管道:Storm, Cassandra, Kafka
如今回到文章一開始提出的实际问题上来。我们基于Storm,Kafka和Cassandra(这些组件应用了前文介绍的技术)设计和实现了自己的流式处理系统。在此。我们仅提供解决方式的简明概述——具体描写叙述全部实现上的坑和技巧的篇幅太长,可能须要单独一篇文章。

系统理所当然使用Kafka0.8。
Kafka作为分区、容错的事件缓冲区,能够实现流回放,能够轻松加入新的事件生产者和消费者。增强了系统的扩展性。Kafka读指针回溯的能力也使随机訪问传入的数据批次成为可能,对应地。能够实现Spark风格的血缘跟踪。也能够将系统输入指向HDFS处理历史数据。
如之前描写叙述。Cassandra用于实现状态检查点和持久化存储聚合。在非常多使用场景中。Cassandra也用于存储终于结果。
TwitterStorm是系统的基石。
全部的活动查询处理都执行于Storm的topologies中,topologies和Kafka、Cassandra进行交互。
一些数据流是简单的:数据抵达Kafka;Storm读取并处理。然后把结果存储在Cassandra或者其它地方。其它数据流更为复杂:一个Storm topology通过Kafka或Cassandra将数据传递给还有一个topology。上图展示了两个此类型数据流(红色和蓝色曲线箭头)。
迈向统一大数据处理平台
现有的Hive,Storm和Impala等技术让我们处理大数据时游刃有余,复杂分析和机器学习时使用批量处理。在线分析时使用实时查询处理,连续查询时使用流式处理。更进一步。Lambda架构还能有效整合这些解决方式。这给我们带来的问题是:将来这些技术和方法如何才干聚集成一个统一解决方式。本节我们讨论分布式关系查询处理,批量处理和流式处理最突出的共同点。合计出可以覆盖全部用户场景,从而在这个领域最具发展潜力的解决方式。
关键之处在于,关系型查询处理,MapReduce和流式处理都能通过shuffling和管道等同样的概念和技术来实现。同一时候:
- 流式处理必须保障严格的数据传递和中间状态持久化。
这些特性对于计算过程非常方便重新启动的批量处理不太关键。
- 流式处理离不开管道。对于批量处理,管道不那么关键甚至在有些场景下不适用。Apache Hive就是基于分阶段的MapReduce过程,中间结果被物化,没有全然利用上管道的长处。
以上两点暗示,可调的持久化策略(基于内存的消息传递或者存储在硬盘上)和可靠性是我们想象中统一查询引擎的显著特性。
统一查询引擎为高层的框架提供一组处理原语和接口。
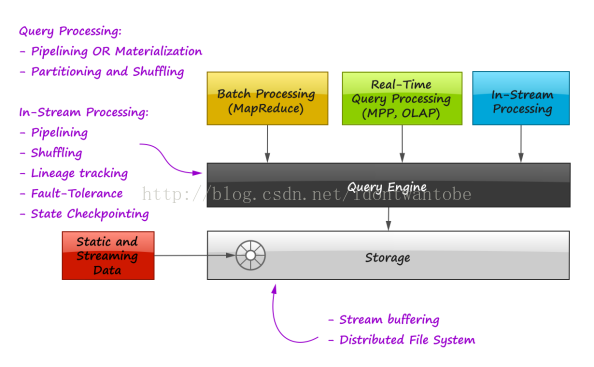
在新兴技术中,下面两者值得重点关注:
- Apache Tez[8],Stinger Initiative[9]的一部分。Apache Tez通过引入一组细粒度的查询处理原语来替代MapReduce框架。它的目标是让Apache Pig和Apache Hive等框架把查询语句和脚本分解成高效的查询处理管道,而不是一系列的MapReduce Job,后者通常非常慢。由于须要存储中间结果。
- Apache Spark[10].Spark项目可能是最先进和最有前途的统一大数据处理平台,它已经包括了批量处理框架。SQL查询引擎和流式处理框架。
References
- Wilschut and P. Apers,“Dataflow Query Execution in a Parallel Main-Memory Environment “
- T. Urhan and M. Franklin,“XJoin: A Reactively-Scheduled Pipelined Join Operator“
- M. Zaharia, T. Das, H. Li, S.Shenker, and I. Stoica, “Discretized Streams: An Efficient and Fault-TolerantModel for Stream Processing on Large Clusters”
- E. Jacobsen and R. Lyons, “The Sliding DFT“
- Elmagarmid, Data Streams Modelsand Algorithms
- N. Marz, “Big Data Lambda Architecture”
- J. Kinley, “The Lambda architecture: principles for architecting realtimeBig Data systems”
- http://hortonworks.com/hadoop/tez/
- http://hortonworks.com/stinger/
- http://spark-project.org/















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









