






序言


在这篇文章里,我没有介绍 ANTLR 的各种使用或语言细节,我觉得这些东西网络上有大把中 / 英文的资料能够參考,我所关注的是一个大的方向和其最核心的内容。对于那些不想深入了解 ANTLR 实现原理或不想研究其代码而仅仅想尽快让它在自己的project中起作用的人来说,依旧足够了,祝各位 ANTLR 之旅愉快 — 像我一样 J 。
有的时候,我还真是怀疑过上本科时候学的那些原理课究竟是不是在浪费时间。比方学完操作系统原理之后我们并不能自己动手实现一个操作系统;学完数据库原理我们也不能弄出个像样的DBMS出来;相同,学完编译原理之后我们好像就仅仅能看着一大堆符号,表和下推自己主动机发呆,然后带着极其虔诚的心向从事编译器实现工作前辈致敬,先前些许对某些编译器小Bug不满的心情从此不翼而飞。
早在数年前我做一个有关DBMS的模拟试验的时候,当中就有一部分要求对SQL语言的WHERE语句进行编译,提取出实用的形式,并保证运算符(AND,OR和括号)各自的优先级。当时我全然是手工用编译原理中讲到的知识作了一个小编译器,历时数周,筋疲力尽。而我近期的一个项目要求将一个自己定义的查询语言(简化的改动版SQL)进行编译并以查询包的形式发送给传感器网络。这时我学乖了,不再什么都从轮子造起了
J,開始的时候本来想用YACC/LEX作为底层编译器,但由于整个应用程序是纯Java的,基于可移植性考虑,也由于不想和下面推自己主动机为原理的YACC/LEX生成的一大堆整数表打交道,我选择了还有一个开源的LL(K)语法/词法分析器—ANTLR。
1 ANTLR简单介绍
ANTLR—
A,其前身是PCCTS,它为包含Java,C++,C#在内的语言提供了一个通过语法描写叙述来自己主动构造自己定义语言的识别器(recognizer),编译器(parser)和解释器(translator)的框架。ANTLR能够通过断言(Predicate)解决识别冲突;支持动作(Action)和返回值(Return Value)来;更棒的是,它能够依据输入自己主动生成语法树并可视化的显示出来(这一点我将在以下的样例中演示)。由此,计算机语言的翻译变成了一项普通的任务—在这之前YACC/LEX显得过于学院派,而以LL(k)为基础的ANTLR尽管在效率上还略有不足,可是经过近些年来的升级改动,使得ANTLR足以应付现存的绝大多数应用。感谢Terence Parr博士和他的同事们十几年来的出色工作,他们为编译理论的基础和语言工具的构造做了大量基础性工作,也直接导致了俄ANTLR的产生。nother
Tool for
Language
Recognition
词法分析器又称为Scanner,Lexical analyser和Tokenizer。程序设计语言通常由keyword和严格定义的语法结构组成。编译的终于目的是将程序设计语言的高层指令翻译成物力机器或虚拟机能够运行的指令。此法分析器的工作是分析量化那些本来毫无意义的字符流,将他们翻译成离散的字符组(也就是一个一个的Token)括keyword,标识符,符号(symbols)和操作符供语法分析器使用。
编译器又称为Syntactical analyser。在分析字符流的时候,Lexer不关心所生成的单个Token的语法意义及其与上下文之间的关系,而这就是Parser的工作。语法分析器将收到的Tokens组织起来,并转换成为目标语言语法定义所同意的序列。
不管是Lexer还是Parser都是一种识别器,Lexer是字符序列识别器而Parser是Token序列识别器。他们在本质上是相似的东西,而仅仅是在分工上有所不同而已。
ANTLR将上述两者结合起来,它同意我们定义识别字符流的词法规则和用于解释Token流的词法分析规则。然后,ANTLR将依据用户提供的语法文件自己主动生成对应的词法/语法分析器。用户能够利用他们将输入的文本进行编译,并转换成其它形式(如AST—Abstract Syntax Tree,抽象的语法树)。
2 ANTLR的使用
到
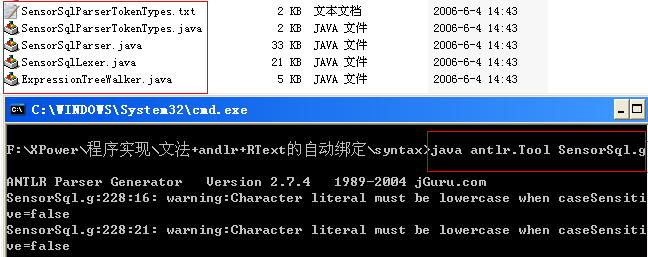
http://www.antlr.org/下载最新版本号的ANTLR开发包和源代码(比如版本号2.7.5)。将antlr-2.7.5.jar所在文件夹配置到你的环境变量中,写好语法文件(比如SensorSQL.g),执行命令“java antlr.Tool SensorSQL.g”就能够获得自己主动生成语法/词法分析器。
2.2 ANTLR语法文件解析
以下我们对图中所描写叙述的ANTLR语法文件做一些具体的分析。为了更好的使用ANTLR,你还能够下载ANTLR的Eclipse插件来帮助你完毕工作。
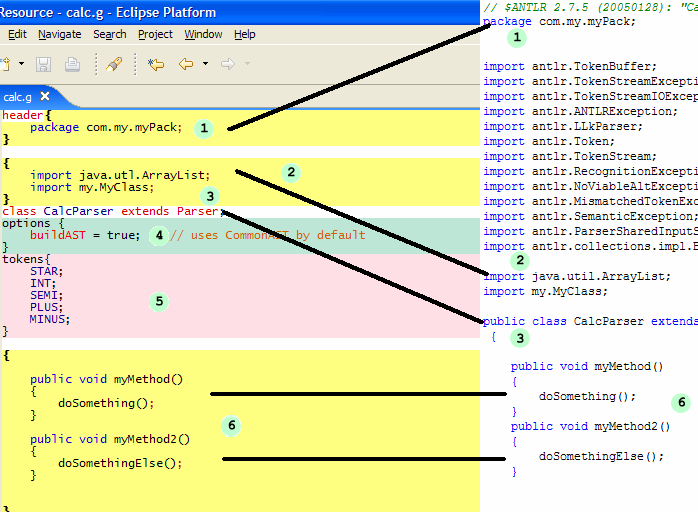
1. header域:全部出如今这里的部分,都会出如今由ANTLR编译之后生成的Java文件的最顶部。在本例中你能够将包名和其它信息放到这一区域中,生成的结果如由面相应代码部分所看到的。
2. 你在这一部分所提供的内容对于文件里的每一个语法都是唯一的。这一区域的内容将出如今实际的类定义之前。也就是说,两个import仅属于类CalcParser,而不属于在同一个文件里定义的其它类(如CalcLexer)
3. 这里是语法定义部分,你相同能够将它看成是类定义。
4. 在Option域中,你能够为你的语法提供可选项。比如是否建立缺省的抽象语法树,指定LL(K)中的參数k的值(缺省为1)等等,更具体的參数请參阅ANTLR自带的手冊。
5. Token部分用来声明那些在词法分析器中没有被声明的“想象的”token。这些信息通经常使用在TreeParser中指定“想象”的节点。
6. 这是还有一个Action区,ANTLR将会忠实地将这一区域内的信息放置到类的定义其中,相当于类的成员方法,主要为用户提供一种在Parser种定制可扩展方法的途径。
2.3 ANTLR规则(RULE)解析
在ANTLR的语法文件里,一个规则的定义是与一个由ANTLR生成的Java源文件相相应的。
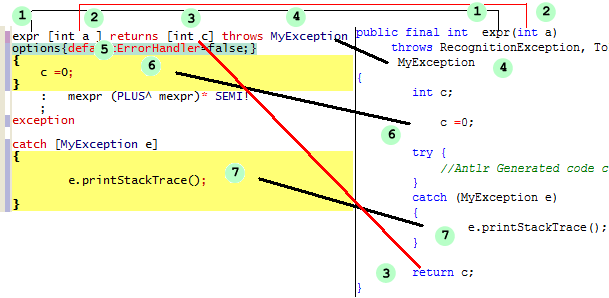
1,2,3,4:正如你所示那样,我们能够在一个规则定义中作与一个函数等价的全部事情。我们能够为规则指定參数(像上面的int a),制定返回值(int c),甚至抛出一个异常。从右半面我们能够清楚地看到,全部在规则中定义的内容都被忠实而准确的翻译到Java源文件的对应位置。
5:这一可选的部分为我们提供了指定某些可选參数的能力。比如图中所看到的代表告诉ANTLR在生成代码的时候不要生成缺省的错误处理部分,这部分将由用户自己负责。
7:在异常处理部分,我们能够指定自己定义的异常处理方法。像这里就不过打印错误栈信息。
3 ANTLR语法实例—SensorSQL
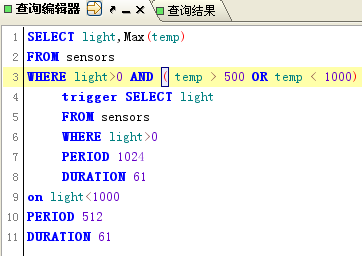
SensorSQL是一个自己定义的简化版SQL语言,鉴于篇幅所限,它所支持的语法定义这里就不具体列出了,我仅仅是给出查询的演示样例:
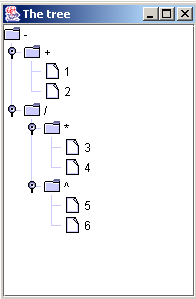
通常,编译一个查询的目的是要把它转化成某种被查询设备能够理解的形式。通常的做法有两种,一种是像在上一节中提到的那样,写好具体的语法规则,在ANTLR生成对应的Java文件之后,就能够直接使用其执行结果。这种样例有非常多,当中最典型的就是对于算数表达式的解析了。对于形如1+2-3*4/5^6这种表达式,仅仅要写好语法规则,就能够在解析过程中直接得到运算结果:首先ANTLR将其编译成逆波兰结构-- ( - ( + 1 2 ) ( / ( * 3 4 ) ( ^ 5 6 ) ) ) ;在生成语法树的过程中,同步计算表达式的值,即相似于2.3节中看到的表达式计算。结果例如以下:
只是这样作有一个缺点,就是在非常多情况下,你可能并不知道要用什么样的方法来处理。所以当真正要開始写处理代码的时候,就要受限于已有的Parser/Lexer中的代码。一旦要有所改动,就要又一次编译语法文件,生成新的Java代码,不胜繁琐。并且,一旦处理过程有误,就要重复调试改动Antlr生成的代。自己主动生成的代码嘛,结构着实也不怎么样,调试的时候也麻烦。所以假设效率同意的话,就没有必要让Antlr作额外的工作,干脆就专心于做他的语法分析也就是了,其它的工作等到生成语法树之后再怎么遍历或者折腾都能够嘛
J。
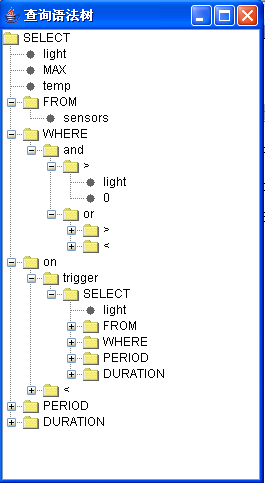
上图就是我刚才演示的SensorSQL语法分析之后产生的结果。在产生这个结果之后,我须要将每个语法元素翻译成字节序列打包发送给传感器网络。这时候,为了保证Where语句中的优先级,你就能够依照ANTLR文档中关于生成语法树的一章,生成相似于我这种结构,然后仅仅需前序遍历这颗语法树的Where部分就能够达到目的,至于其它部分,顺序遍历一遍就好了。
4 ANTLR Studio
有了前面的基础之后,我们就能够開始真正的工作了。只是用“记事本或Editplus+命令行”或者干脆写个ANT脚本也不是不能够,可是总认为在集成化IDE满天飞的时代用这个方式有点过于原始,幸好Placid System 为我们提供了一个Eclipse插件来使我们有机会直接走出原始社会。下载地址为:
http://www.placidsystems.com/,眼下最新版本号是1.1.0。唯一令人遗憾的是这个插件尽管功能非常完好,却是要收费的,否则仅仅有11天的试用期。
4.1 ANTLR Studio插件的安装
Eclipse下插件的安装自不必多说,要注意的是从Placid System站点上提供的license文件,下载之后它的名字为license.lic.txt,要把它的后缀名.txt去掉,然后放到ECLIPSE_DIR/plugins/AntlrStudio_x.x.x 文件夹(这里 x.x.x 是版本, 比如 - 1.1.0)。成功安装之后在Eclipse的工具栏上会出现一个词法分析器的导航button:
当右键单点击你的project时,你会发现控制是否使用ANTLR Studio的开关:
当打开一个文法文件之后,能够看到例如以下界面:
在右面的大纲窗体,列有全部Parser和Lexer的元素,能够看到Protected Token(比如Number)和其它普通的Token是不一样的;在左面,不同的区域是用不同的颜色块加亮来区分的。
4.2 功能介绍
ANTLR Studio在Eclipse Help提供了比較详尽的文档描写叙述,所以这里我仅仅介绍一些1.1.0版本号的新功能。
l 全然支持ANTLR 2.7.6,并支持将之前的project自己主动升级到1.1.0版本号。
l Syntax Diagram View,能够方便的查看所输入的语法结构。
l 改进了Debug功能,能够调试比較大的文法文件。而在这之前,假设一个文法文件非常大的话,ANTLR Studio就会抛出异常。
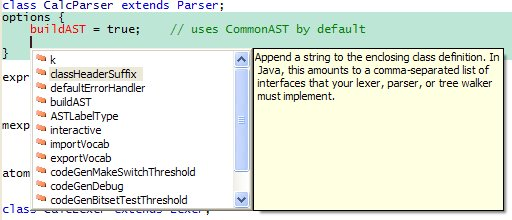
l 支持自己主动的代码补全功能,提供一个ANTLR文档的比較全面的提示信息(例如以下所看到的)。
4.2.1 语法图表视图(Syntax Diagram View)
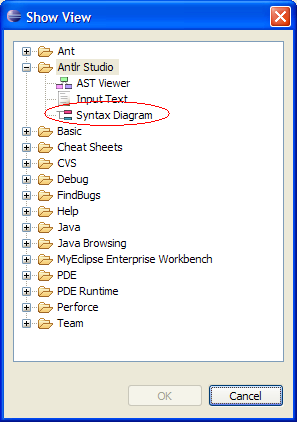
在
Window->Show View->Other
中选择显示这个视图之后,你就能够使用这个非常酷的功能了
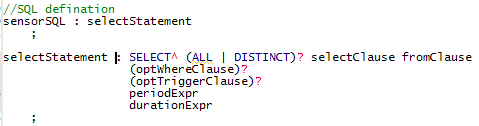
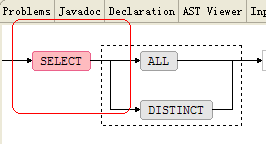
利用这个视图,你能够非常easy的看到你定义语法的语法结构,比如,我的SELECT语句定义例如以下
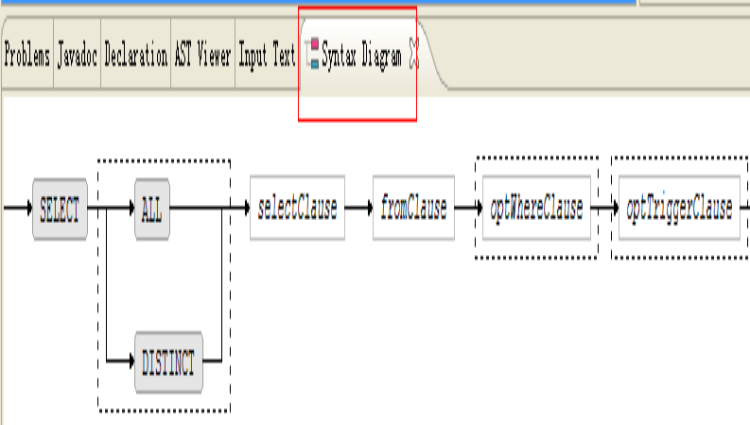
你仅仅须要将光标标放到selectStatement规则的任何位置,就能够在Syntax Diagram View中看到:
于是完整的语法结构清晰的显示在了我们面前。这时你仅仅须要将光标放到脱字符号(^)上面(注:脱字符号用于指明在生成语法树的时候,脱字符号所在的SubRule要作为树或子树的根节点):就会看到:
相应的SubRule被加亮成粉红色,而假设你的光标放到的位置是一个Token的话就会变成淡蓝色,简直太酷了。
4.2.2 增强的Debug功能
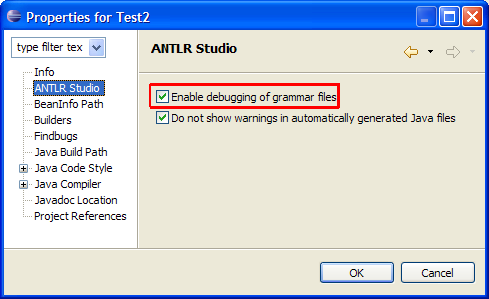
想要启动或关闭ANTLR Studio的Debug功能,须要完毕下面步骤:
l 在project中启用/取消ANTLR Studio
l 右键单击project,打开“属性”中的
ANTLR Studio
选项卡。
l 选择/取消'Enable debugging in grammar files'
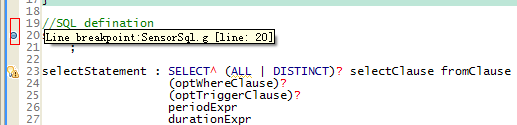
做完这些后,我们就能够痛快的使用其Debug功能了。与调试其它Java文件一样,我们能够在语法文件的任何位置插入断点:
当程序执行至断点之后,我们相同能够像调试普通应用程序一样使用诸如“跳过”,“继续”等Java应用程序的Debug方式来进行,十分的方便和顺手。
在这篇文章里,我没有介绍 ANTLR 的各种使用或语言细节,我觉得这些东西网络上有大把中 / 英文的资料能够參考,我所关注的是一个大的方向和其最核心的内容。对于那些不想深入了解 ANTLR 实现原理或不想研究其代码而仅仅想尽快让它在自己的project中起作用的人来说,依旧足够了,祝各位 ANTLR 之旅愉快 — 像我一样 J 。















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









