







PnP(pespective-n-point)问题,就是已知的n个空间3D点与图像2D点对应的点对,计算相机位姿、或者物体位姿,二者是等价的。
有个通俗,但很有用的解释:
以下讨论中设相机位于点Oc,P1、P2、P3……为特征点。
Case1:当N=1时
当只有一个特征点P1,我们假设它就在图像的正中央,那么显然向量OcP1就是相机坐标系中的Z轴,此事相机永远是面对P1,于是相机可能的位置就是在以P1为球心的球面上,再一个就是球的半径也无法确定,于是有无数个解。
Case2:当N=2时
现在多了一个约束条件,显然OcP1P2形成一个三角形,由于P1、P2两点位置确定,三角形的变P1P2确定,再加上向量OcP1,OcP2从Oc点射线特征点的方向角也能确定,于是能够计算出OcP1的长度=r1,OcP2的长度=r2。于是这种情况下得到两个球:以P1为球心,半径为r1的球A;以P2为球心,半径为r2的球B。显然,相机位于球A,球B的相交处,依旧是无数个解。
Case3:当N=3时
与上述相似,这次又多了一个以P3为球心的球C,相机这次位于ABC三个球面的相交处,终于不再是无数个解了,这次应该会有4个解,其中一个就是我们需要的真解了。
Case4:当N大于3时
N=3时求出4组解,好像再加一个点就能解决这个问题了,事实上也几乎如此。说几乎是因为还有其他一些特殊情况,这些特殊情况就不再讨论了。N>3后,能够求出正解了,但为了一个正解就又要多加一个球D显然不够"环保",为了更快更节省计算机资源地解决问题,先用3个点计算出4组解获得四个旋转矩阵、平移矩阵。根据公式:
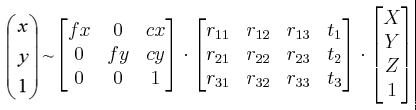
将第四个点的世界坐标代入公式,获得其在图像中的四个投影(一个解对应一个投影),取出其中投影误差最小的那个解,就是我们所需要的正解。
不同算法的差别在于求解方式,如迭代逼近,还是牛顿优化,还是参考点验证等。
基于视觉的姿态估计根据使用的摄像机数目分为单目视觉和多目视觉。根据算法又可以分为基于模型的姿态估计和基于学习的姿态估计。这里主要指n点对位姿计算算法,因此,单目,且基于针孔畸变模型。
OpenCV中有solvePnP以及solvePnPRansac用来实现已知平面四点坐标确定摄像头相对世界坐标系的平移和旋转。cvPOSIT基于正交投影,用仿射投影模型近似透视投影模型,不断迭代计算出估计值。此算法在物体深度相对于物体到相机的距离比较大的时候,算法可能不收敛。
从世界坐标系到相机坐标系的转换,需要矩阵[R|t],其中R是旋转矩阵,t是位移向量。如果世界坐标系为X,相机坐标系对应坐标为X‘,那么X' = [R|t]*X。从相机坐标系到理想屏幕坐标系的变换就需要内参数矩阵C。那么理想屏幕坐标系L = C*[R|t]*X。如何获得[R|t],大致是已知模板上的几个关键点在世界坐标系的坐标即X已知,然后在摄像头捕获的帧里获得模板上对应点在屏幕坐标系的坐标即L已知,通过求解线性方程组得到[R|t]的初值,再利用非线性最小二乘法迭代求得最优变换矩阵[R|t],这属于最一般的迭代法计算。
相机姿态估计的问题就是寻找相机的外参数,即是最小化误差函数的问题。误差函数有的基于image-space,有的基于object-space(P3P,AP3P,EPnP等就是基于物体空间的)。
RPP算法基于object-space为误差函数提供了一种可视化的方法。误差函数有两个局部极小值。在无噪声条件下,第一个局部极小值跟正确的姿态对应。另外的误差函数的极小值就是标准姿态估计算法为什么会抖动的原因。由于姿态估计算法最小化误差函数总是要使用迭代算法,因此需要一个初值。如果初值接近第二个局部极小值,那么迭代算法就收敛到错误的结果,后面详细介绍,估计第一个姿态,RPP算法使用任何已知的姿态估计算法,在这里里,使用迭代算法。从第一个姿态使用P3P算法估计第二个姿态。这个姿态跟误差函数的第二个局部极小值接近。使用估算的第二个姿态作为初值,使用迭代算法获得第二个姿态。最终正确的姿态是有最小误差的那个。
这类问题最终都是解线性方程组AX=b的问题。当b∈R(A)时,x=A的广义逆*b;当b∈不R(A)时,能否是Ax接近b呢,即是否有x使||Ax-b||最小,习惯上用2-范数即欧式范数来度量。最小二乘解常存在,然后这样的解未必是唯一的。当在方程无解的情况下,要找到最优解。就是要最小化所有误差的平方和,要找拥有最小平方和的解,即最小二乘。最小化就是把误差向量的长度最小化。
PnP问题解决了已知世界参考系下地图点以及相机参考系下投影点位置时3D-2D相机位姿估计问题,不需要使用对极约束(存在初始化,纯旋转和尺度问题,且一般需要8对点),可以在较少的匹配点(最少3对点,P3P方法)中获得较好的运动估计,是最重要的一种姿态估计方法。最后,如果知道世界参考系下的地图点,同时知道相机参考系下的地图点,可以通过ICP的方法去求解姿态。这样就构成了立体视觉中最重要的对极几何,PnP和ICP三种最常用的姿态估计方法。
求解PnP问题目前主要有直接线性变换DLT,P3P/AP3P,EPnP,UPnP以及非线性优化方法,还有SDP,NPL等,不常见,忽略。
DLT
直接构建一个12个未知数的[R|t]增广矩阵(先不考虑旋转矩阵的自由度只有3),取六个点对,去求解12个未知数(每一个3D点到归一化平面的映射给出两个约束),最后将[R|t]左侧3*3矩阵块进行QR分解,用一个旋转矩阵去近似(将3*3矩阵空间投影到SE(3)流形上)。
P3P
P3P方法是通过3对3D/2D匹配点,求解出四种可能的姿态,在OpenCV calib3d模块中有实现,但是对于相机远离3D平面(low parallax)或者视角垂直于3D平面的情况下效果不佳,不知道最近有没有更新过。论文Complete Solution Classification for the Perspective-Three-Point Problem中提到了一种改进的方法,可以消除这种退化的情况。
将世界坐标系下的ABC三点和图像坐标系下的abc三点匹配,其中AB,BC,AC的长度已知,<a,b>,<b,c>,<a,c>也是已知,通过余弦定理可以求出A,B,C在相机参考系中的坐标,然后使用类似ICP的坐标系对齐,就可以求得当前相机薇姿。
通过余弦定理构建二元二次方程组【2】可以求解出OA,OB,OC之间的长度比例,从而确定世界坐标系下的相机位姿。可以想象一下为什么会出现四个解,在空间中的位置是什么样的,以及为什么在远离3D点平面或者视角垂直3D点平面时,会出现退化情况。
EPnP
需要4对不共面的(对于共面的情况只需要3对)3D-2D匹配点,是目前最有效的PnP求解方法。
The aim of the Perspective-n-Point problem—PnP in short—is to determine the position and orientation of a camera given its intrinsic parameters and a set of n correspondences between 3D points and their 2D projections. It has many applications in Computer Vision, Robotics, Augmented Re- ality and has receivedmuch attention in both the Photogrammetry and Computer Vision communities. In particular, applications such as feature point-based camera tracking require dealing with hundreds of noisy feature points in real-time, which requires computationally efficient methods.
空间中任意3D点的坐标可以用4个不共面的3D点坐标的权重表示
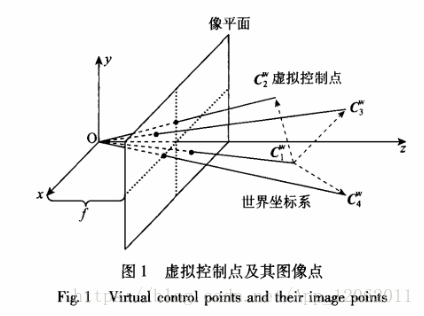
通常选取世界坐标下的四个控制点坐标为Cw=[0,0,0,1]T, [1,0,0,1]T,[0,1,0,1]T,[0,0,1,1]T;通过n个3D点在相机平面的投影关系,以及与这四个控制点的权重关系,构建一个12*12方阵,求得其零空间特征向量,可以得到虚拟控制点的相机平面坐标,然后使用POSIT算法即可求出相机位姿。
通常在用EPnP求得四对点下的封闭解后,可以将该解作为非线性优化的初值,优化提高精度














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









