






下面对
http://www.svmhz.com/shaonvmanhua/进行爬取,对大神的博客(
http://www.jianshu.com/p/8b4a589f7980)进行详解:
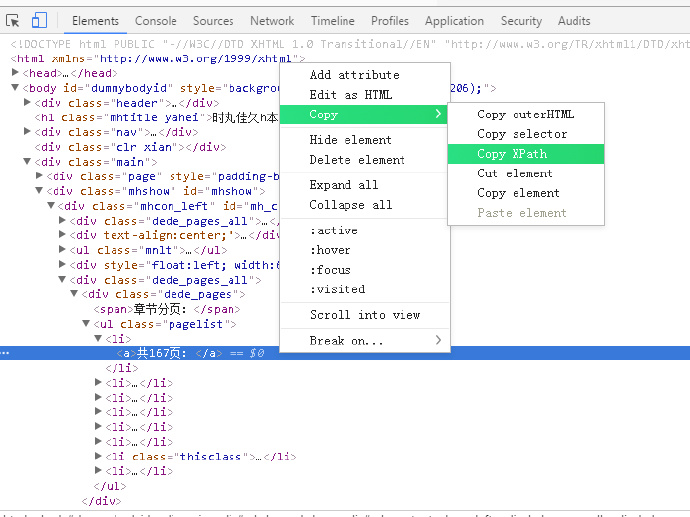
根据网页图片查看响应代码,选中√的地方
查看源代码的方法,浏览器页面按下F12,然后鼠标移动到某个图片时,下面的代码就会变暗
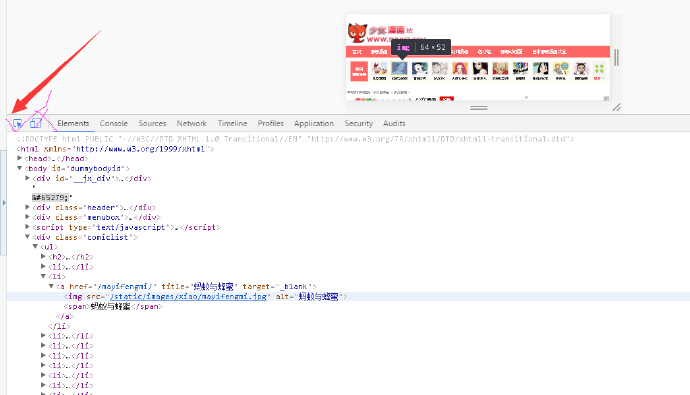
如下,选中网页上的图片时,下面的响应代码就会变暗
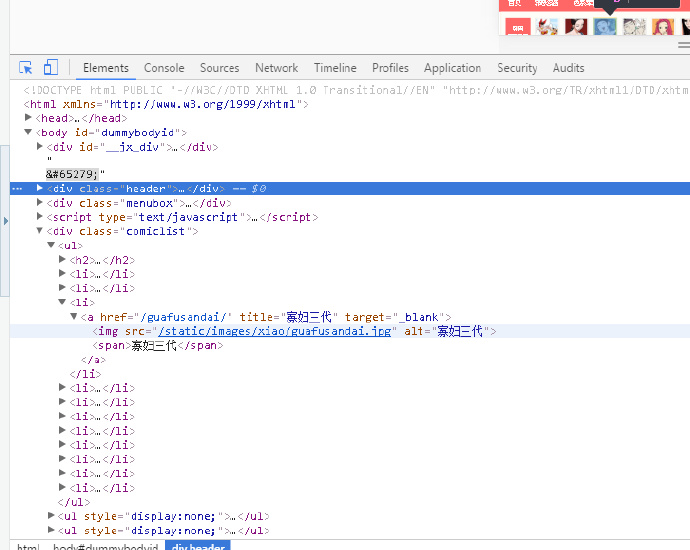
鼠标挪动到图片上就出现了
下面对爬虫的代码进行逐行解释
------------------------------ 下面解释get_index_page(offset)函数-----------------------------
url
=
'http://www.svmhz.com/shaonvmanhua/list_4_%s.html'
% offset
解释:


以上两张图的3是对应的
该图中的3是对漫画列表提供索引
offset相当于形参,把数据传给s,所以两者前面都有%s
该代码大意比较清楚,如果等待时间比较长,则响应异常,输出相关异常信息
------------------------------get_index_page(offset)函数-------------------------
######## 下面解释parser_index_page(html)函数-----------
入口参数html代表的是网页源代码
listcon_tag = soup.find('ul', class_='listcon')#属性为listcon的列表
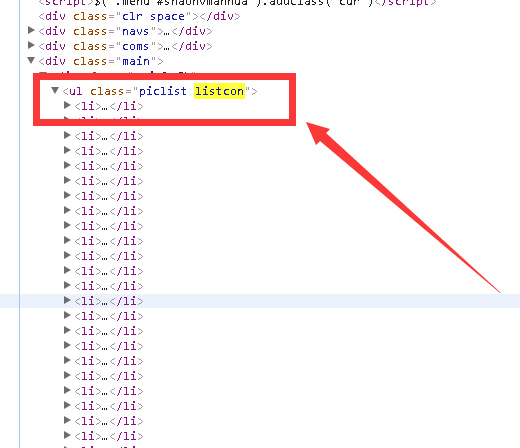
列表中的元素<li>........</li>是每本漫画书的入口
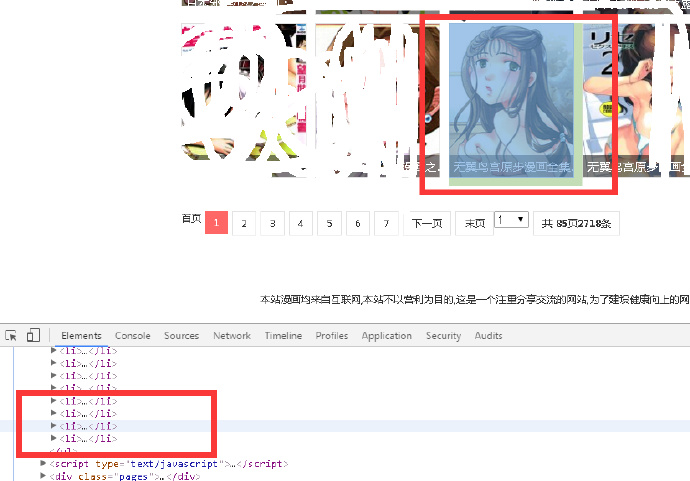
随便打开列表中的一个元素,会发现以下内容

url_list = listcon_tag.find_all('a', attrs={'href': True})
这句话是对网页源代码中 包含的所有漫画书连接 进行提取,得到满足需要的部分网页源代码
urls = ['http://www.svmhz.com' + url['href'] for url in url_list]#遍历子网页的子网页,遍历干净为止。
上述代码也就是说,从url_list集合(当前网页的部分源代码)中提取出对链接修饰的部分,拼接到当前网址:
拼接后的结果传给urls集合
该函数的目的是为了获取每本漫画的入口地址,也就是漫画的第一页的地址
函数解释结束
########parser_index_page(html)函数解释结束#########
##############get_image_page(url, total)函数讲解############
入口参数url举例:
http://www.svmhz.com/shaonvmanhua/9894.html
total举例(纯数字) :89
list_url = [ ]
解释:
创建一个列表
list_url.append(url)
在列表中加入每一本漫画入口地址
url = url.split('.html', 2)[0]
把这个url以.html为标记切割2次,切割结果中取第一个
for i in range(2,total+1):
解释:
total+1是取不到的,所以循环的区间是[2,total+1)
urls = url + '_' + str(i) + '.html'
ulrs举例:
这个已经是具体到了某特定漫画书的具体某一页了
也就是说该函数的大意是:首先获得每本函数的入口地址,切割改地址后,
后面拼接上页码和html,形成新的地址。
也就是说该函数的目的是:从漫画入口地址=>漫画具体某一页的地址。
新地址存入list_url集合
############get_image_page(url, total)函数讲解结束######
##############parser_image_page(url)讲解#############
该函数的目的是为了获取带有总页数信息
函数的前面部分是为了判断响应是否超时
htmls = etree.HTML(html)
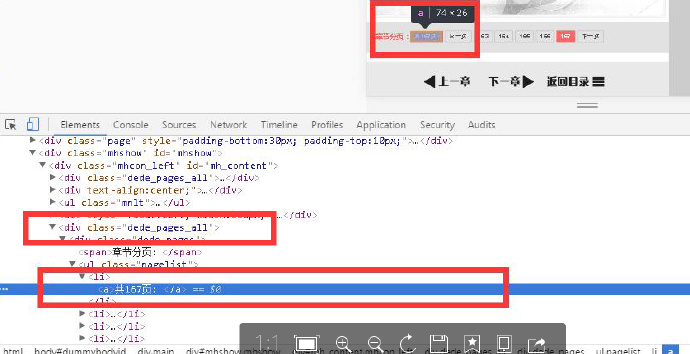
total = htmls.xpath('//*[@id="mh_content"]/div[@class="dede_pages_all"]/div/ul/li[1]/a/text()')[0]#右键复制网页源码中的Xpath,然后粘贴
粘贴的办法是:
粘贴结果是://*[@id="mh_content"]/div[4]/div/ul/li[1]/a
对上述结果进行修改,用 text()函数获取内容
div[4]修改为:
div[@class="dede_pages_all"]
div[@class="dede_pages_all"]要作为一个整体来看,也算是特征匹配
dede_pages_all来自下图:
此类路径成为xpath,用于对页面的对象存储的所在路径进行定位。
xpath就是js代码中存储某个标签对应的类对象的路径,根据该路径直达图片的存储网址
最终该函数返回total,也即漫画的总页数
-----------------parser_image_page(url)函数讲解结束---------------------------------
---------------------------------get_image_src(url)讲解---------------------------------
该链接是漫画的具体第几页的链接
该函数的作用是向链接发送请求,并且获得响应。
------------------------------------get_image_src(url) 讲解结束-----------------------
-------------------------------
parser_img_src(html)讲解
-------------------------------
if语句前出现的变量所代表的对象的具体举例:
titles=【日本漫画】色列本子之[U.R.C] 慧ちゃん限定(13)_少女漫画站
title_page= 【日本漫画】色列本子之[U.R.C] 慧ちゃん限定(13)
title= 【日本漫画】色列本子之[U.R.C] 慧ちゃん限定
if语句后出现的变量的含义如图示
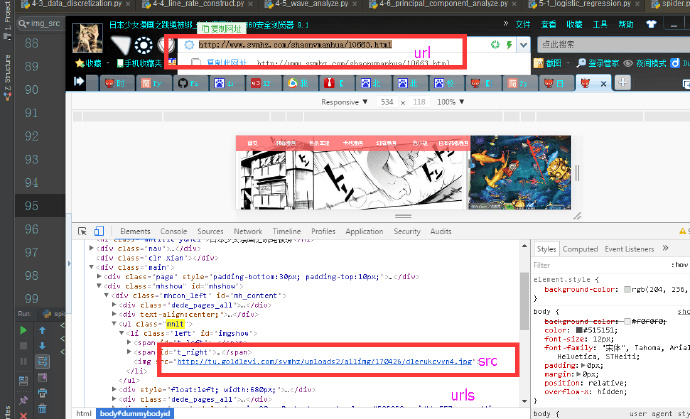
如上图,

img_span
= soup.find
(
'ul',
{
'class'
:
'mnlt'
}
)
用于在网页源代码中找到图片的存储地址所在的范围
可以看到,上图中有个<img src>接下来进行正则提取,
进一步锁定范围
锁定符合特征的<img src>
img_src
= img_span.find_all
(
'img',
src
=re.compile
(
'^http://tu.goldlevi.com/svmhz/uploads2/allimg/[0-9]{1,}/(.*?).jpg$'
))
上面的(。*?)是贪婪匹配
for url in img_src:
urls = url['src']
down_image(urls, title, titles)#调用了down_image函数
从url中进一步提取src部分然后赋值给urls,这样urls就得到了图片的存储地址
这里必须一步步搜索范围,否则会把其他不相关的图片包括进来
-------------------------------
parser_img_src(html)讲解结束
---------------------------
---------------------------
down_image(url, title, titles)
-------------------------------
入口参数举例
url = http: // tu.goldlevi.com / svmhz / uploads2 / allimg / 161129 / 2 - 161129102620.jpg
title = 莲子酱绅士福利本 动漫本子邪恶少女漫画
titles = 莲子酱绅士福利本 动漫本子邪恶少女漫画_少女漫画站
调用
save_image函数进行下载,本函数还进行请求,判断请求是否会超时
------------------
down_image(url, title, titles)讲解结束
-------------------------------
------------------------save_image(content, title, url, titles)讲解----------------
path
=
'D:/pic/'
+
str
(title
)
#确定保存在哪个文件夹下面
if not os.path.exists (path ) : #如果文件夹不存在,就进行保存
if not os.path.exists (path ) : #如果文件夹不存在,就进行保存
os.mkdir(path)

file_name的开头是结构,后面是path,titles和.jpg,分别替换用彩色线条连接的部分
------------------------------save_image(content, title, url, titles)结束----------------
#########################结尾###################
if __name__ == '__main__':
groups = [x for x in range(1, 86)]#爬http://www.svmhz.com/shaonvmanhua/的一部分,总共有85页
pool = Pool()
pool.map(main, groups)#

########################结尾讲解结束###################
——————————————————————附上Python3.6源代码——————————————————————————
#-*- coding: utf-8 -*-#-*- coding: utf-8 -*-
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
from multiprocessing import Pool
from lxml import etree
import requests, os, re
def get_index_page(offset):#√
url = 'http://www.svmhz.com/shaonvmanhua/list_4_%s.html' % offset#offset是形参,用来传给s
try:
response = requests.get(url)
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
print('链接返回出现异常')
return None
except RequestException:
print('爬虫出现异常')
return None
def parser_index_page(html):#√该函数是为了找到漫画对应的连接在什么地方
soup = BeautifulSoup(html, 'lxml')
listcon_tag = soup.find('ul', class_='listcon')#属性为listcon的列表
#在源码中被ui包起来的部分,也就是找到被ul包围起来的列表
if listcon_tag:
url_list = listcon_tag.find_all('a', attrs={'href': True})#找到所有的修正部分
#print("url_list",url_list)
if url_list:
urls = ['http://www.svmhz.com' + url['href'] for url in url_list]#遍历子网页的子网页,遍历干净为止。
return urls#获得各个漫画本的入口的集合,例如http://www.svmhz.com/shaonvmanhua/9642.html
def get_image_page(url, total):#√该函数是为了获取所有子网页的集合
list_url = []#python的列表创建
list_url.append(url)
#print("################")
#print("url = ",url)
#print("################")
#print("total = ",total)
url = url.split('.html', 2)[0]#把这个url以.html为标记切割2次,切割结果中取第一个
for i in range(2,total+1):#total+1是取不到的
urls = url + '_' + str(i) + '.html'#ulrs举例:http://www.svmhz.com/shaonvmanhua/6952_165.html,这个已经是具体到了某特定漫画书的具体某一页了
list_url.append(urls)
return list_url#这个函数之所以这么处理,并且序号从2开始,是因为漫画打开后的第一页是没有页码的,页数从每本漫画的第2页才开始
def parser_image_page(url):#获取带有总页数信息的字符串
try:
response = requests.get(url)
response.encoding = response.apparent_encoding
if response.status_code == 200:
html = response.text
htmls = etree.HTML(html)#提取页面数据
total = htmls.xpath('//*[@id="mh_content"]/div[@class="dede_pages_all"]/div/ul/li[1]/a/text()')[0]#右键复制网页源码中的Xpath,然后粘贴
if total:
return total#这里返回的信息举例:“本漫画共69页”
print('链接异常')
return None
except RequestException:
print('爬虫异常')
return None
def get_image_src(url):
#print("此处的url",url)#举例:http://www.svmhz.com/shaonvmanhua/9370_4.html
try:
response = requests.get(url)
print("response",response)
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
print('链接异常')
return None
except RequestException:
print('爬虫异常')
return None
def parser_img_src(html):#这里html是网页源码
soup = BeautifulSoup(html, 'lxml')#soup是beautifulsoup解析过的html
titles = soup.select('title')[0].get_text()#有可能会有其他的title,但是不需要,这里指需要第一个,
#print("这里分割:", titles)#日本漫画】色列本子之[U.R.C] 慧ちゃん限定(2)_少女漫画站,(2)是页码
title_page = titles.split('_', 2)[0]#titles是创立图片时需要使用的名字,title是创立文件夹需要的名字
#print("title_page=",title_page)
title = title_page.split('(', 2)[0]#保留(左边的部分
#print("title=", title)
img_span = soup.find('ul', {'class': 'mnlt'})
if img_span:
img_src = img_span.find_all('img', src=re.compile('^http://tu.goldlevi.com/svmhz/uploads2/allimg/[0-9]{1,}/(.*?).jpg$'))
if img_src:
for url in img_src:
urls = url['src']
down_image(urls, title, titles)#调用了down_image函数
def down_image(url, title, titles):#根据入口链接对漫画进行下载
#url = http: // tu.goldlevi.com / svmhz / uploads2 / allimg / 161129 / 2 - 161129102620.j
#title = 莲子酱绅士福利本 动漫本子邪恶少女漫画
#titles = 莲子酱绅士福利本 动漫本子邪恶少女漫画_少女漫画站
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content, title, url, titles)#调用函数进行对图片的保存
print('链接异常')
return None
except RequestException:
print('爬虫异常')
return None
def save_image(content, title, url, titles):
path = 'D:/pic/' + str(title)#确定保存在哪个文件夹下面
if not os.path.exists(path):#如果文件夹不存在,就进行保存
os.mkdir(path)
file_name = '{0}/{1}.{2}'.format(path, titles, '.jpg')#{1}.{2}中{1}是名字,{2}是后缀,{0}是文件夹路径
#print("file_name=",file_name)
if not os.path.exists(file_name):#如果以该文件为名义的文件不存在
with open(file_name, 'wb') as f:#读写建立一个新的二进制文件
f.write(content)
print('保存漫画成功', title, url)
f.close()
def main(offset):
html = get_index_page(offset)#html初始化
for url in parser_index_page(html):#这里的html是按了F12之后出现的网页源代码,in后面是深层次便利后的 子网页连接的集合
html = parser_image_page(url)#html代表总页码相关的字符串,例如“本漫画共有89页”
total = int(re.compile('(\d+)').search(html).group(1))#从带有总页码信息的文字字符串中提取出纯数字信息,提取后结果为:89
for img_url in get_image_page(url, total):#传入参数,url=某本特定的漫画书入口网址,total:该漫画书页码,该句对哪本漫画书中的第几页进行了精确的确定
#该函数返回该特定的漫画书中各个页码对应的连接的集合****
htmls = get_image_src(img_url)#get_image_src是获取url并且在函数里面调用下载函数
parser_img_src(htmls)
##两重for循环的话
##第一个for循环把某个特定漫画的总页码数total和该特定漫画在首页的入口url递给第二个for循环
##那么有一重是负责遍历首页的各种连接的
##有一重是用来遍历该连接中的各种子连接的
##第二个for循环是用来遍历某个特定漫画的各个页并进行下载的
##第一个for是用来遍历首页推荐的各种漫画的
if __name__ == '__main__':
groups = [x for x in range(1, 86)]#爬http://www.svmhz.com/shaonvmanhua/的一部分,总共有85页
pool = Pool()
pool.map(main, groups)#
————————————————————————————————————————————————————
Reference:

















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









