









RT、
如果网上一搜,会有很多答案。
譬如:Class类,是获取类的类模板实例对象,通过反射的机制获取。
根据API中的定义:
Class.getName():以String的形式,返回Class对象的“实体”名称;
Class.getSimpleName():获取源代码中给出的“底层类”简称。
单看这种书面文字的话,可能有人还是不明白他们的区别,下面我就将通过代码以及图片的形式,让大家直观地看到它们的区别,代码很简单,结果也很简单。
代码如下:
public class Main {
private static final String TAG1 = Main.class.getName();
private static final String TAG2 = Main.class.getSimpleName();
public static void main(String[] args) {
System.out.println("getName ----- " + TAG1 + "\n" + "getSimpleName ----- " + TAG2);
}
}结果图片如下:
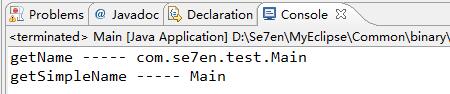
如上图所示,我们可以很清晰明了地看出它们的区别:
getName ----“实体名称” ---- com.se7en.test.Main
getSimpleName ---- “底层类简称” ---- Main














 4674
4674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









