







上一篇文件介绍了linux内存管理以及大页内存的原理,有了原理的支撑,接下里分析dpdk大页内存源码就轻松了,才不会云里雾里不知道在说啥。所谓的dpdk大页内存的实现,说白了就是dpdk自己实现了一套大页内存的使用库,这个和libhugetlbfs.so是类似的,就是自己实现了大页内存的申请,释放操作, 替代了传统的malloc, free系统调用。先从整体上看下dpdk大页内存有哪些内容。
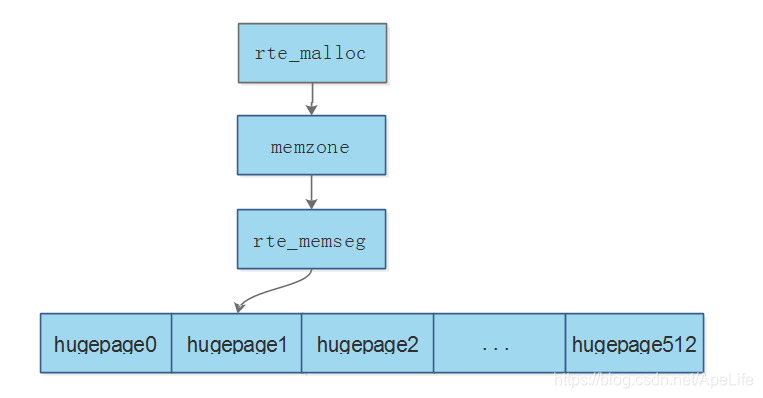
当应用层需要申请内存时,直接调用rte_malloc接口进行内存申请; 而rte_malloc实际上是从memzone内存区获取内存的,这个内存区存储着已经被所有应用层申请的内存。那memzone内存区中的内存又是从哪里来的呢?答案是直接从rte_memseg段内存中获取来的, 这个段内存中维护着当前哪些段内存还没有被使用。而段内存又是从哪里获取到内存的呢?答案是从每个大页内存中获取,将物理内存上连续的大页存放到一个段内存中。由此可见,rte_malloc最终的底层调用,是从大页内存申请内存空间的,也可以验证dpdk的实现说白了就是自己实现了一个malloc, free的内存管理方式。下面一一来看下大页内存,段内存,内存区,以及ret_malloc的实现。
一、大页内存的映射
1、大页内存初始化
大页内存初始化,其时就是扫描/sys/kernel/mm/hugepages目录,查看系统支持哪几种大页内存,例如2M,4M等,然后将系统支持的每种大页内存的页面大小,大页内存的挂载目录,以及每一种大页内存的个数保存到internal_config配置结构中的hugepage_info。大页内存的初始化是从eal_hugepage_info_init接口开始的,来看下这个接口的实现。
-
int eal_hugepage_info_init(void) -
{ -
//打开/sys/kernel/mm/hugepages目录 -
DIR *dir = opendir(sys_dir_path); -
//扫描/sys/kernel/mm/hugepages,查看支持多少种大页类型 -
struct dirent *dirent = readdir(dir); -
while(dirent != NULL) -
{ -
//获取每种大页内存的页面大小 -
struct hugepage_info *hpi = &internal_config.hugepage_info[num_sizes]; -
hpi->hugepage_sz = rte_str_to_size(&dirent->d_name[dirent_start_len]); -
//获取每种大页内存挂载的目录,例如/mnt/huge -
hpi->hugedir = get_hugepage_dir(hpi->hugepage_sz); -
//获取没一种大页个数 -
hpi->num_pages[0] = get_num_hugepages(dirent->d_name); -
dirent = readdir(dir); -
} -
}

通常系统只会有一种大页,每种大页目录下nr_hugepages文件记录着这种类型的大页总个数,free_hugepages记录着这种大页剩余多少个大页还可以使用。通过读这些大页配置文件的方式,获取到每种大页的信息,并保存起来。为什么要记录这些信息呢?为了后续可以根据保存的大页个数,大页大小,在/mnt/huge目录下创建大页内存配置,并进行大页内存的映射操作。
get_hugepage_dir这个接口用来获取每种大页的挂载目录,也是通过读文件的方式来获取大页的挂载目录。读取/proc/mounts文件中存在hugetlbfs那一行,就知道挂载到哪个目录了。例如:

最后将系统支持的这些种类的大页,按照大页的小,从大到小排序。
swap_hpi(&internal_config.hugepage_info[j-1], &internal_config.hugepage_info[j]);需要注意的是eal_hugepage_info_init这个接口只有主进程才会执行,从进程是不会调用这个接口的。到此大页初始化就完成了。
2、大页内存共享配置映射
dpdk支持主从进程方式,主进程必须在从进程之前运行起来,主进程只有一个,从进程可以有多个。为了让主从进程之间共享大页内存,需要维护一个配置结构,记录着当前映射了哪些大页内存,哪些可以使用,哪些已经被分配使用了。主从进程都可以访问这个配置结构, 从而主从进程都可以知道当前哪些大页可以被使用,进而从这些大页上申请空间。这个配置结构dpdk的实现方式是把它放到共享内存中,以便主从进程都可以访问。rte_config.mem_config成员记录着这个配置结构的信息。分别来看主从进程主了什么操作。
-
static void rte_config_init(void) -
{ -
switch (rte_config.process_type) -
{ -
case RTE_PROC_PRIMARY: -
//主进程创建共享内存配置 -
rte_eal_config_create(); -
break; -
case RTE_PROC_SECONDARY: -
//从进程打开共享内存配置后,映射到从进程自己的地址空间 -
rte_eal_config_attach(); -
//睡眠等待主进程设置完成共享内存配置 -
rte_eal_mcfg_wait_complete(rte_config.mem_config); -
//从进程重新映射共享内存配置 -
rte_eal_config_reattach(); -
} -
}
主进程通过创建/var/run/.rte_config文件,然后设置文件大小为rte_config.mem_config结构大小,最后将这个文件进行共享内存映射。
-
//主进程创建/var/run/.rte_config文件 -
mem_cfg_fd = open(pathname, O_RDWR | O_CREAT, 0660); -
//主进程映射/var/run/.rte_config到主进程空间 -
rte_mem_cfg_addr = mmap(rte_mem_cfg_addr, sizeof(*rte_config.mem_config),PROT_READ | PROT_WRITE, MAP_SHARED, mem_cfg_fd, 0);
从进程打开这个文件,将文件内容映射到从进程地址空间。
-
//从进程打开/var/run/.rte_config文件 -
mem_cfg_fd = open(pathname, O_RDWR); -
//从进程将/var/run/.rte_config文件内容映射到从进程空间 -
rte_mem_cfg_addr = mmap(NULL, sizeof(*rte_config.mem_config),PROT_READ | PROT_WRITE, MAP_SHARED, mem_cfg_fd, 0
需要注意的是,为什么从进程需要进行两次配置文件映射? 第一次映射时,有可能主进程还没有完成所有的大页内存映射操作,这个时候主从进程虚拟地址空间有可能不一样,主从进程虚拟地址空间不一样,零拷贝就无从谈起。因此从进程睡眠等待主进程完成所有大页内存映射操作,主进程完成映射后,会打标记,从进程根据标记就可以知道主进程完成了映射。接着从进程进行第二次映射,从而保证了主从进程之间的虚拟地址空间是一摸一样的,保证了零拷贝的可行性。
3、大页内存的映射
在大页内存初始化以及配置映射完成后, 接下里就可以进行大页内存的映射了。先来看主进程是如何进行大页内存映射,主进程大页内存映射,说白了就是在/mnt/huge目录下创建大页内存配置,然后将大页配置映射到共享内存中,同时维护了一张页表,记录着每一个大页文件在内存中的虚拟地址与物理地址映射关系。先整体感受下这个结构:

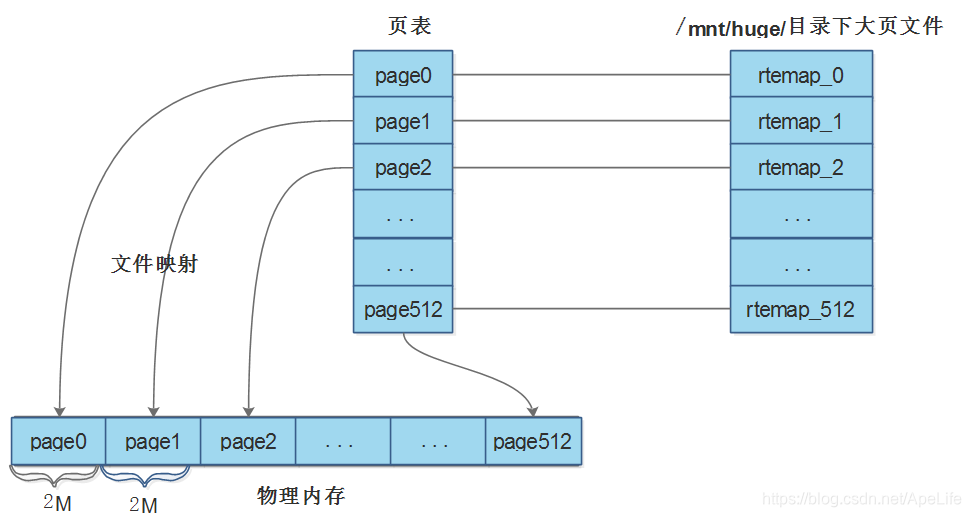
假设linux系统上大页大小为2M, 大页个数512;则主进程大页内存的映射就是维护了上面这样的一个结构。创建了一个大页表,里面有512条记录,每个记录的结构为hugepage_file,每条记录都记录着/mnt/huge目录下相应大页文件映射到物理内存中的位置,每一个大页文件都映射到了物理内存2M空间。了解了整体映射关系,再来分析代码就简单了,大页映射代码入口为:rte_eal_hugepage_init。
(1)、大页表的创建
如何知道需要创建多大的页表呢?这就要用到上面提到的大页内存初始化中保存的结果了,internal_config配置结构中的hugepage_info字段记录了系统支持多少种大页,一共有多少个大页。根据这个信息来创建大页表。
-
//创建大页表 -
tmp_hp = malloc(nr_hugepages * sizeof(struct hugepage_file)); -
memset(tmp_hp, 0, nr_hugepages * sizeof(struct hugepage_file));
(2)、第一次大页映射
大页内存映射一共要经历2次映射操作,为什么经过2次映射呢?这是因为每个进程4G逻辑地址空间是连续的,但映射后的虚拟地址空间不一定连续。因此第一次映射后的虚拟地址空间不一定是连续的, 而第二次映射根据物理内存做了相应的调整, 物理内存上连续的大页,尽量保证虚拟地址空间上的这些大页也是相连续的,连续的页而不是分散在各处能够提高内存的性能。
第一次映射时,map_all_hugepages传进来的orig参数为1,第二次创建来的参数为0。每个页表项纪录着这个大页文件的编号,大页文件的大小,大页文件名,以及大页文件映射后的虚拟地址
-
//第一次映射,保存大页信息 -
if (orig) -
{ -
//每个页的编号,大页个数为512的情况下,页编号0--512 -
hugepg_tbl[i].file_id = i; -
//大页大小 -
hugepg_tbl[i].size = hugepage_sz; -
//获取/mnt/huge/目录下的各个大页文件,例如/mnt/huge/rtemap_235 -
eal_get_hugefile_path(hugepg_tbl[i].filepath,sizeof(hugepg_tbl[i].filepath),hpi->hugedir,hugepg_tbl[i].file_id); -
}
接下里进行第一次映射操作,如果/mnt/huge目录下相应的大页文件不存在,则会创建这个大页文件。同时将第一次映射后的虚拟地址保存到页表中的orig_va字段中
-
//将/mnt/huge目录下相应的大页文件映射到内存中,文件不存在则创建。 -
fd = open(hugepg_tbl[i].filepath, O_CREAT | O_RDWR, 0755); -
virtaddr = mmap(vma_addr, hugepage_sz, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); -
if (orig) -
{ -
//第一次映射,将映射后的虚拟地址保存在orig_va -
hugepg_tbl[i].orig_va = virtaddr; -
} -
//vma_addr逻辑地址是连续的,但逻辑地址映射后的虚拟地址virtaddr不一定是连续的 -
vma_addr = (char *)vma_addr + hugepage_sz;
(3)、虚拟地址转为物理地址
将大页表中每个页表项中的虚拟地址转为物理地址,然后保存到页表项中的physaddr字段。为什么要进行转换呢?是为了对物理地址进行排序,然后根据物理内存上连续的大页,使得虚拟地址空间上的大页也尽量连续。find_physaddrs函数来实现虚拟地址到物理地址的转换, 在dpdk大页内存原理这篇文章末尾已经详细分析了是如何将虚拟地址转为物理地址的,这里就不再重复了。
(4)、将物理地址进行排序
sort_by_physaddr接口来负责将页表中的物理地址进行排序,排序的规则: 如果linux系统是64位,则按照物理地址,从大到小排序; 如果linux系统是32位,则按照物理地址,从小到达排序。排序的目的是为了判断物理页是否连续,从而也根据连续的物理页使得对应的虚拟页也尽量连续
(5)、第二次大页映射
上面已经分析了为什么要进行第二次大页映射,这里就不再重复了。第二次映射时map_all_hugepages传进来的参数orig为0, 来看下这个流程。
-
if (vma_len == 0) -
{ -
//第二次映射 -
//统计连续物理内存空间的大小,根据连续物理内存空间开辟连续虚拟内存空间大小 -
#ifdef RTE_ARCH_PPC_64 -
//64位时按照物理地址,从大到小排序, -
if (hugepg_tbl[j].physaddr != hugepg_tbl[j-1].physaddr - hugepage_sz) -
{ -
break; -
} -
#else -
32位时按照物理地址,从小到达排序 -
if (hugepg_tbl[j].physaddr != hugepg_tbl[j-1].physaddr + hugepage_sz) -
break; -
#endif -
//获取一块连续的虚拟内存空间,尽量保证虚拟页页连续。如果没有足够的连续页,则有多少是多少 -
vma_addr = get_virtual_area(&vma_len, hpi->hugepage_sz); -
if (vma_addr == NULL) -
vma_len = hugepage_sz; -
}
区分32位还是64位系统,统计连续的物理内存页,从而也尽可能使得虚拟页也是连续的。如果无法满足足够多的连续虚拟页,则有多少连续的虚拟页,就使用这些连续的虚拟页,提高内存的性能。
-
//接下里从连续的虚拟页中进行分割,使得后续的每个页都从这个连续的虚拟页中进行分割获取 -
virtaddr = mmap(vma_addr, hugepage_sz, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0); -
hugepg_tbl[i].final_va = virtaddr;
第二次映射完成后,此时将映射后的虚拟地址保存到了每个页表项中的final_val中。那之前第一次映射的orig_va虚拟地址空间就没用了,可以调用unmap_all_hugepages_orig解除第一次映射的虚拟地址空间。
(6)、大页表内存映射
上面只是创建了大页表,此时大页表还没有映射到共享内存中。如果没映射到共享内存,则这个大页表是有可能在内存不足时被交换到磁盘swap分区,影响内存性能。通过create_shared_memory接口,将页表也映射到共享内存中,映射的文件为/var/run/.rte_hugepage_info,之后从进程也可以访问这个文件进行页表的映射
-
//创建大页表共享内存 -
hugepage = create_shared_memory(eal_hugepage_info_path(), nr_hugefiles * sizeof(struct hugepage_file));
到此为止,大页内存文件第二次映射完成,大页表也映射完成了。此时这些大页文件已经映射到共享内存了,所有的主从进程都可以使用这些大页内存。这些大页内存永远都常驻在内存中,而不会因为内存不足而被交换到磁盘swap分区,影响内存性能。页表映射到共享内存后,此时页表也是常驻在内存中,永远都不会因为内存不足而被交换到swap分区中。因此可以看出,不管是页表还是大页内存,都通过共享内存方式映射到了内存中,被所有的主从进程共享,且永远不会被交换到磁盘swap分区,提高了内存性能与tlb命中。
上面提到的这些都只是主进程进行共享内存映射。那从进程如何操作呢?从进程调用rte_eal_hugepage_attach这个接口进行共享内存映射,实现就很简单了,大部分都是做些异常判断。简单打开/var/run/.rte_hugepage_info页表文件,然后映射到共享内存中,而不需要像主进程一样创建/mnt/huge目录下的大页文件。之后从进程也可以访问这些共享内存了。
主从进程在映射完大页内存以及页表后,就可以供更高层,例如段内存,内存区,rte_malloc来调用了。大页内存是dpdk的基石,是dpdk底层维护的内存空间,应用层申请内存最终都是从这些大页内存上申请的。因为大页内存是通过共享内存来实现的,并且保证了主从进程虚拟地址空间的一致性,这也是零拷贝的基础。
二、段内存的实现
在将/mnt/huge目录下的大页内存文件映射到共享内存后,以及将页表也映射到共享内存后,按道理大页内存已经就可以被应用层用来申请空间了。那为什么dpdk还需要将属于同一个cpu且前后相互连续的,大小也相同的这些大页组成一个内存段呢? 那是为了提升内存性能的缘故, 连续的物理大页,虚拟大页总比散落在内存中各个位置的大页性能强吧,方便管理也不容易产生内存碎片。
感性认识下段内存的结构。从图中可以看出每个段内存元素都可以指向物理内存上连续的多个大页。例如段0指向0---3物理页;段1指向3这个物理页;段2指向4-5这两个物理页
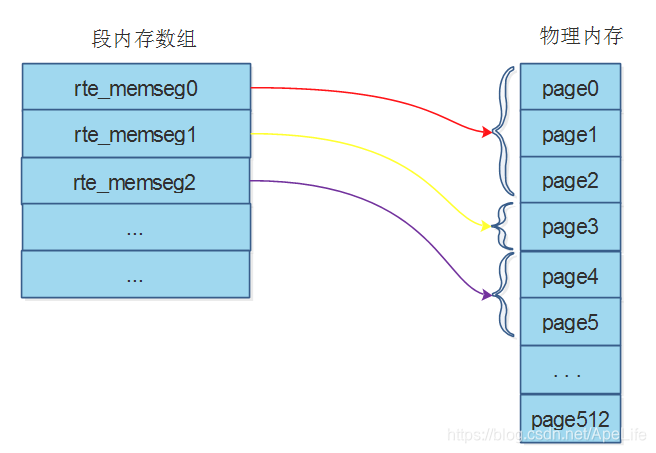
在rte_eal_hugepage_init函数的末尾,会将页表中记录的所有大页内存进行分割。将处于同一个cpu;且前后物理内存,虚拟内存都相互连续; 前后页大小也相同的大页组成一个内存段。这些内存段存放在前面已经提到过的共享内存配置rte_mem_config中的memseg数组中,这样主从进程都可以从这个内存段数组指向的大页上申请内存。也就是说内存段将大页内存管理起来了, 每个内存段都记录着多个还可以被使用的大页的内存信息。高层调用者,例如memzone内存区在需要申请内存时,只需要向内存段申请就好了,无需知道底层大页内存内部的实现细节,体现了分层的设计思想。。
-
if (new_memseg) -
{ -
//新的段内存结构 -
mcfg->memseg[j].len = hugepage[i].size; -
mcfg->memseg[j].socket_id = hugepage[i].socket_id; -
mcfg->memseg[j].hugepage_sz = hugepage[i].size; -
} -
else -
{ -
//一个段内存可能会占用多个连续的大页内存 -
mcfg->memseg[j].len += mcfg->memseg[j].hugepage_sz; -
}
内存段数组创建好了, 默认内存段都是空闲的,表示内存段对应的大页都是可以被使用的。共享内存配置rte_mem_config中的free_memseg记录着当前哪些内存段是可以被使用的,刚创建完时这个free_memseg空闲内存段数组的内容就是共享内存配置rte_mem_config中的memseg这个内存段数组的内容,这个在rte_eal_memzone_init接口中完成初始化。
-
int rte_eal_memzone_init(void) -
{ -
//填充空闲内存段 -
for (i = 0; i < RTE_MAX_MEMSEG; i++) -
{ -
memcpy(&free_memseg[i], &memseg[i], sizeof(struct rte_memseg)); -
} -
}
这空闲内存段什么时候被使用呢? 在上层调用者memzone来申请内存时,会从空闲内存段free_memseg数组中指向的大页申请空间,申请完后会更新free_memseg内存段里面的len, phys_addr等大页地址信息。可以参考memzone_reserve_aligned_thread_unsafe接口的实现。
-
//更新内存段,内存段里面的部分内存已经被使用了 -
free_memseg[memseg_idx].len -= len; -
free_memseg[memseg_idx].phys_addr += len; -
free_memseg[memseg_idx].addr = (char *)free_memseg[memseg_idx].addr + len;
三、内存区memzone的实现
rte_memzone内存区有什么作用呢? 这个是和上面提到的memseg内存段有关联的。内存段里面记录的是当前哪些大页可以被使用;而内存区记录的是从内存段指向的大页中申请了多少内存,将申请的内存零拷贝保存到内存区中,和内存段相反,内存区记录的是哪些大页已经不可用了。每次从内存段中申请一次内存,都会创建一个rte_memzone内存区结构,保存从内存段指向的大页中申请的大页空间。从图中可以看出不管内存区,还是内存段,指向的内存空间都是在大页内存上

(1)、内存区初始化
内存区初始化操作,除了会将上面提到的空闲内存段初始化外,还会初始化内存区本身。共享内存配置rte_mem_config中的memzone数组,每个数组元素记录着从内存段指向的大页中申请了多少内存,这些内存现在是被使用了。因为rte_mem_config配置结构被映射到了共享内存,因此主从进程都可以访问这个内存区。 初始化时将这些内存区清0
-
int rte_eal_memzone_init(void) -
{ -
//内存区初始化 -
mcfg->memzone_idx = 0; -
memset(mcfg->memzone, 0, sizeof(mcfg->memzone)); -
}
(2) 、申请内存
应用层调用rte_memzone_reserve函数申请内存时,实际上就是从内存段指向的大页中申请。申请的过程默认是从内存段中查找满足条件最小的内存段,如果传入的len参数为0,则查找满足条件最大的那个内存段,从内存段指向的大页中申请,申请成功后,更新空闲内存段中相应记录,表示哪些大页已经被分配使用了。
申请成功后将创建一个内存区,保存这些从内存段指向大页申请的空间。
-
//更新内存段,内存段里面的部分内存已经被使用了 -
free_memseg[memseg_idx].len -= len; -
free_memseg[memseg_idx].phys_addr += len; -
free_memseg[memseg_idx].addr = (char *)free_memseg[memseg_idx].addr + len; -
//从内存段指向的内存中获取到内存区后,保存到memzone中 -
struct rte_memzone *mz = &mcfg->memzone[mcfg->memzone_idx++]; -
snprintf(mz->name, sizeof(mz->name), "%s", name); -
mz->phys_addr = memseg_physaddr; -
mz->addr = memseg_addr; -
mz->len = requested_len; -
mz->hugepage_sz = free_memseg[memseg_idx].hugepage_sz; -
mz->socket_id = free_memseg[memseg_idx].socket_id; -
mz->flags = 0; -
mz->memseg_id = memseg_idx;
(3)、内存区的查询
在内存区上查询某个命名的内存区是否存在,调用rte_memzone_lookup接口就可以了,实现非常简单,这里就不啰嗦了。每次申请内存的时候,将会创建一个内存区,这个内存区是有名字的,查询的时候根据这个名字来查询就好了。
四、dpdk内存分配(rte_malloc, rte_free)
rte_malloc, rte_free这两个接口是应用层调用最多的接口,应用层调用两个接口进行内存的申请与释放。调用rte_malloc时,会申请一个内存区memzone,从内存区指向的大页内存中申请空间。由于这两个接口的实现涉及算法层面的东西,很难讲清楚。用图形方式来表达可能会更好。先来看下rte_malloc内存分配的实现。
1、rte_malloc
在共享内存配置rte_mem_config中,有一个malloc_heaps堆数组,每个cpu都有一个这样的堆结构,存放每个cpu自己调用rte_malloc申请的内存。由于这个内存配置存放在共享内存中,因此主从进程都可以访问。每个cpu堆结构里面有一个free_head数组链表,默认有五个空闲链表,每一个链表元素大小都不相同。第一个链表每个元素的大小为0-256; 第二个链表元素大小为256-1024; 第三个链表元素大小为1024-4096等等,可以看下面这张图。例如当要申请1500字节的空间时,应该从第二个空闲链表中获取空闲的内存。
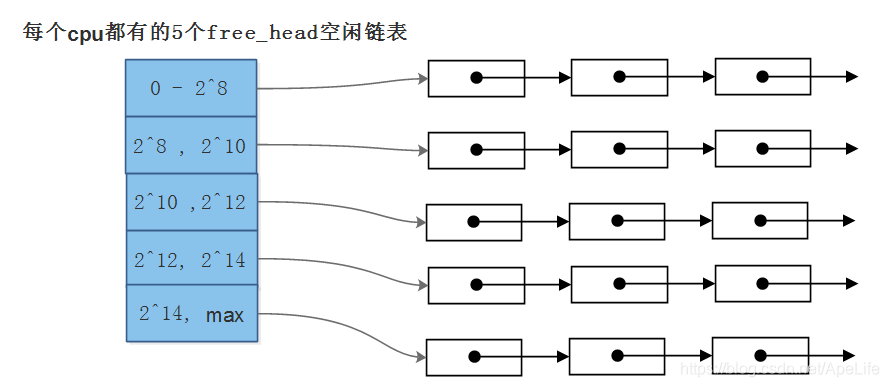
为了方便说明,我这里假设所有链表节点都在第2个空闲链表上(256---1024), 其他链表都是一样的操作。假设应该层第一次申请空间,则会从内存区数组一次性获取一个大的内存区,通常比应用层申请的空间大。然后将这个内存区分割成两部分,每一个部分都有一个malloc_elem头部结构。其中第一部分为未使用的内存,第二部分只有一个已经使用了的头部,没有数据。然后将第一部分这个未使用的内存加入到空闲链表中。


应该层申请空间时,则会查找这个空闲链表,发现有空闲的内存空间,因此再次分割上面这个未使用的内存。将未使用的这部分空间从后往前再次分割成两部分,并用prev指针连接起来。

应该层继续申请空间时,则会查找这个空闲链表,发现还有剩余空间,则会再次分割上面这个未使用的内存。将未使用的这部分空间从后往前再次分割成两部分,并用prev指针连接起来。

接着应用层继续申请内存空间,如果上面这个空闲的内存没有足够的内存时,则会再次从内存区数组指向的大页内存上申请一个内存,然后将未使用的空间挂载到空闲链表。可以看出空闲链表是通过free_list连接起来的。

总结下申请内存的过程, 优先从本cpu的空闲链表中获取,如果没有则从其他cpu的空闲链表中获取。根据应用层申请空间的大小,从本cpu的5个空闲链表中选择一个,查看这个空闲链表是否有满足大小的空闲内存,如果有则在这个空闲链表中获取;如果没有则从内存区中获取一个新的大内存,并将剩余的空间加入到空闲链表中。
需要注意的是,不管一个内存区被分割为多少个struct malloc_elem元素,这些元素都执向同一个内存区。
-
void * rte_malloc_socket(const char *type, size_t size, unsigned align, int socket_arg) -
{ -
//从本物理cpu堆上获取内存 -
ret = malloc_heap_alloc(&mcfg->malloc_heaps[socket], type, size, align == 0 ? 1 : align); -
//本物理cpu堆上没有足够的内存,则从其他物理cpu上获取 -
for (i = 0; i < RTE_MAX_NUMA_NODES; i++) -
{ -
ret = malloc_heap_alloc(&mcfg->malloc_heaps[i], type, size, align == 0 ? 1 : align); -
} -
}
-
//在内存区申请一个size大小的堆元素 -
static int malloc_heap_add_memzone(struct malloc_heap *heap, size_t size, unsigned align) -
{ -
mz = rte_memzone_reserve(mz_name, mz_size, numa_socket, mz_flags); -
}
分割每个空闲链表元素是在malloc_elem_alloc这个接口中完成的,表达能力有限,没法把这个给讲清楚,请谅解。可以参考上面的图来分析这个代码,不会复杂的。
2、rte_free
调用rte_free可以释放已经申请的内存空间。如图中的内存位置是要被释放的。

释放后的内存布局如下: 这个被释放的空间被重新加回到空闲链表中,通过free_list给连接起来了。但prev指针仍然指向前一个位置,这个是不会变的。

接着如果需要把这个链表中第一个被使用的内存给释放,则释放后的布局如下,会将前后两个空闲的内存给合并成一个大的空闲区域。

到此为止,dpdk大页内存的实现已经分析完成了,接下来的文章将分析dpdk内存池的实现。















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









