









作者:小小明
常规arff文件读取
之前有位群友遇到了arff格式的数据,却不知道怎么读取:

然后我让这位群友把文件发我,给我分析一下,我用文件编辑器打开后,发现格式如下:
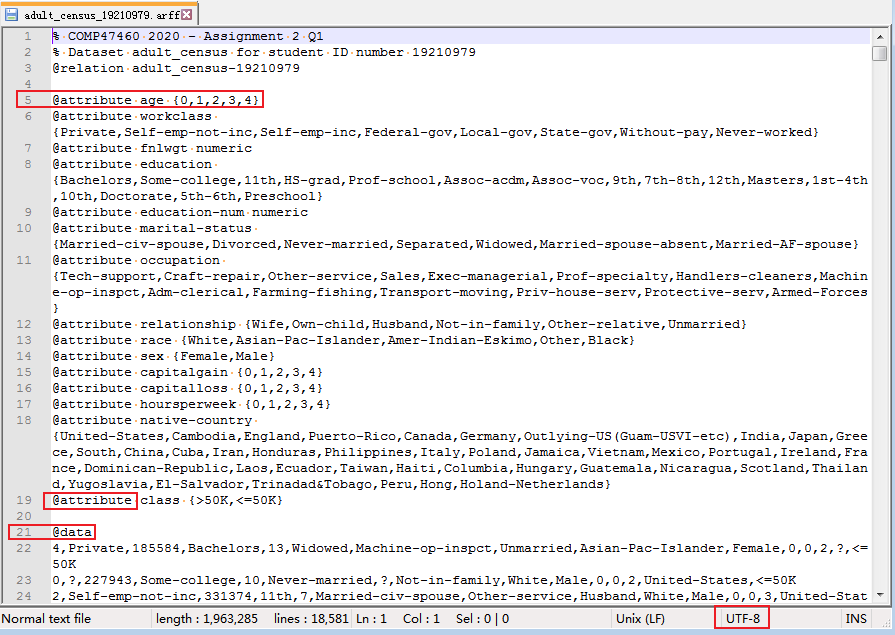
只是一个文本文本而已,解析文本文件我实在太擅长了。可以看到:
- 编码是utf-8
- 列名都在以@attribute开头的行
- 数据在@data的后面的部分
理解了这三点,我马上就能用pandas直接读取它,下面看看代码:
import pandas as pd
with open("adult_census_19210979.arff", encoding="utf-8") as f:
header = []
for line in f:
if line.startswith("@attribute"):
header.append(line.split()[1])
elif line.startswith("@data"):
break
df = pd.read_csv(f, header=None)
df.columns = header
df
结果:
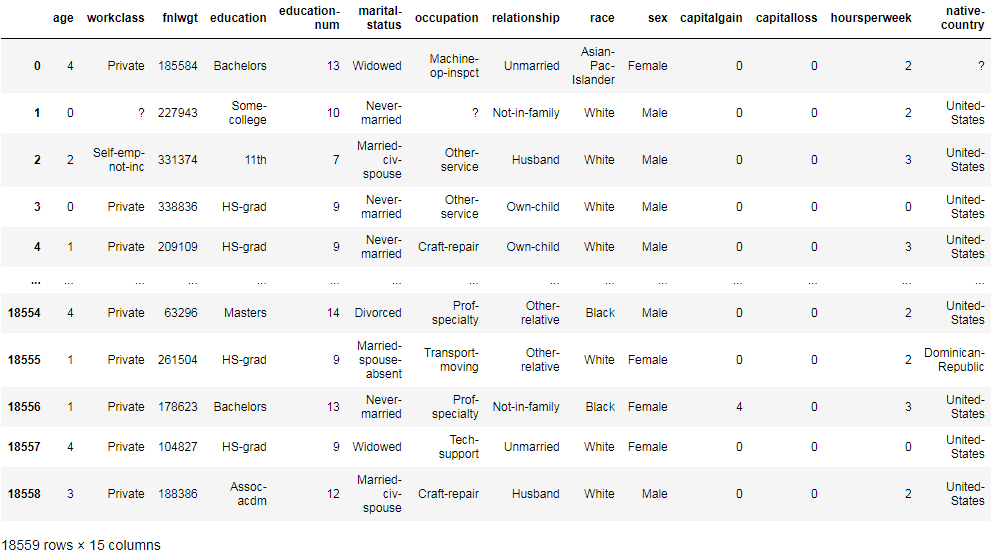
为了后续使用方便,我们可以将上面的代码封装成函数:
def read_arrf(file):
with open(file, encoding="utf-8") as f:
header = []
for line in f:
if line.startswith("@attribute"):
header.append(line.split()[1])
elif line.startswith("@data"):
break
df = pd.read_csv(f, header=None)
df.columns = header
return df
这样,读取任何arrf文件都方便,只需要直接传入即可:
read_arrf("adult_census_19210979.arff")
然后我得到了:

不过其实scipy已经含有读取这种常规的arff文件的方法:
import pandas as pd
from scipy.io import arff
data, _ = arff.loadarff("adult_census_19210979.arff")
df = pd.DataFrame(data)
df
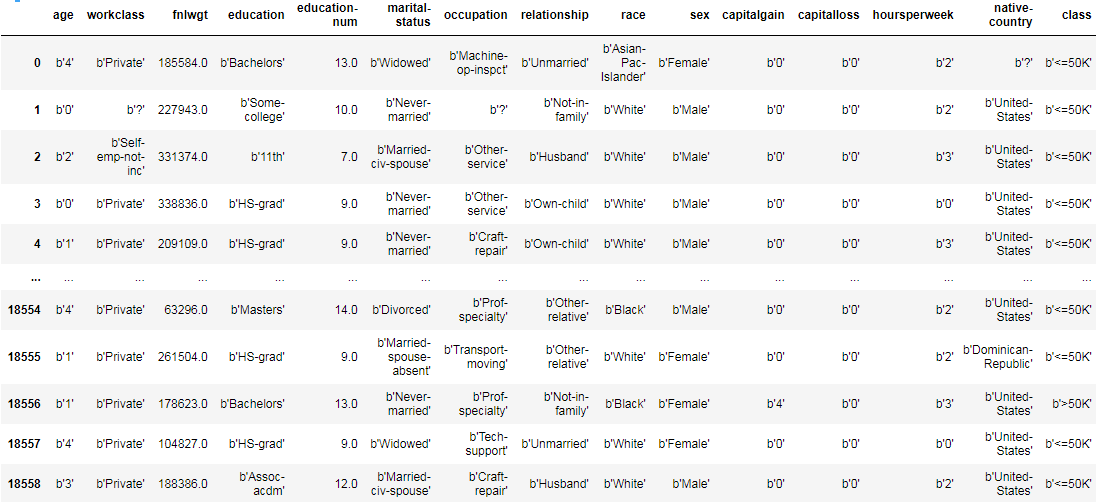
不一样的地方主要在于字符串都会读成字节的形式。
稀疏矩阵形式的arff文件读取
这只是开胃小菜,昨天有位即将从电子科技大学毕业的网友联系到我,说arff文件不仅仅只有上面的存储形式,还有以稀疏矩阵的格式存储的。
数据文件来源:http://sites.labic.icmc.usp.br/text_collections/?C=D;O=A
例如:
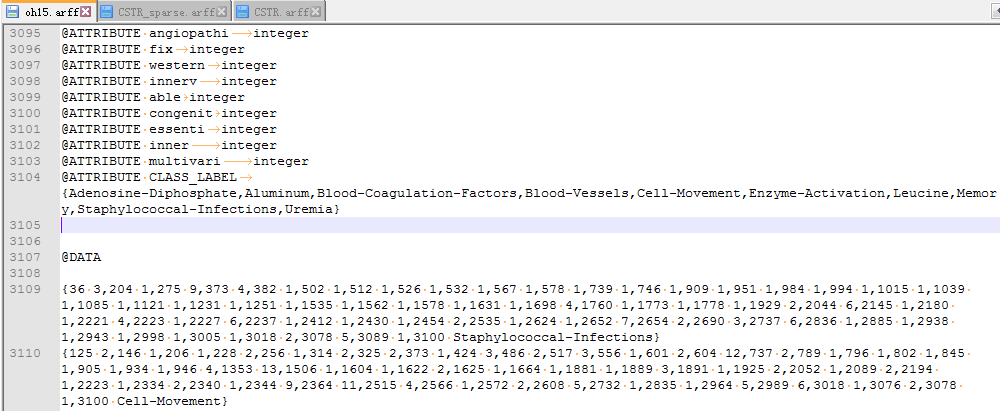
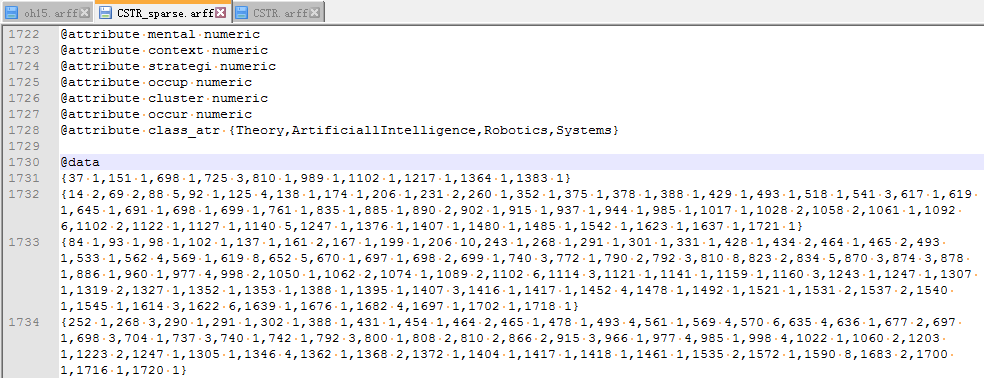
以稀疏矩阵形式存储时,存储格式是指定位置存对应的值(空格分割)。
最终完整的读取代码为:
import pandas as pd
def read_sparse_arrf(file):
with open(file, encoding="utf-8") as f:
header = []
default_field = {}
field_num = 0
for line in f:
if line.startswith("@attribute") or line.startswith("@ATTRIBUTE"):
_, name, field_type = line.split()
header.append(name)
if field_type.startswith("{"):
default_field[field_num] = field_type[1:-1].split(",")[0]
field_num += 1
elif line.startswith("@data") or line.startswith("@DATA"):
break
default_field_keys = set(default_field.keys())
width = len(header)
data = []
for line in f:
line = line.strip()
if not line:
continue
tmp = [0]*width
flags = set()
for kv in line[1:-1].split(","):
k, v = kv.split()
k = int(k)
if k not in default_field_keys:
v = int(v)
flags.add(k)
tmp[k] = v
for k in default_field_keys-flags:
tmp[k] = default_field[k]
data.append(tmp)
return pd.DataFrame(data, columns=header)
测试读取:
df = read_sparse_arrf("CSTR_sparse.arff")
df

df = read_sparse_arrf("oh15.arff")
df
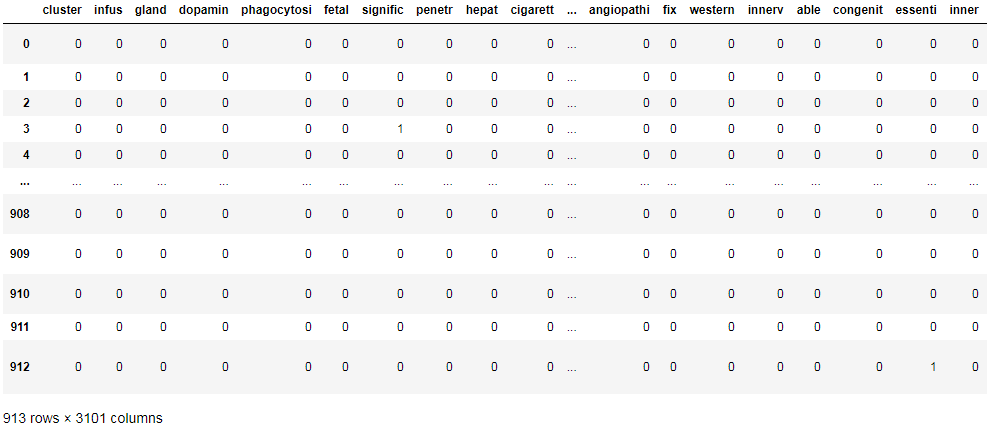
注意:上面代码假设了稀疏矩阵形式的arrf文件,非{}可选形式,均为数值类型。
最终这位朋友对结果还挺满意的:
我感觉要感谢这个朋友指出我没有碰到过的这种arrf格式,所以这个红包我就不收了。















 3587
3587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











