







业务背景
7号10:00创建活动,7号0:00到7号10:00之间下单未支付的用户push催付,7号10:00后用户下单5分钟内没有支付,以PUSH的方式催付
方案
0-10点间数据可理解为离线数据,可通过创建一个ad-hoc查询任务,并吐出人群到给发送服务。
下单后5分钟后没有支付以push催付,采用Redis的延迟列队方案
如果为下单半个小时后催付,建议采用DB轮询方案。
https://blog.csdn.net/asd491310/article/details/90418292中列举了延迟任务的解决方案,不论是RocketMQ、TimingWheel等方案,基本思路是有效减少扫描数据集。
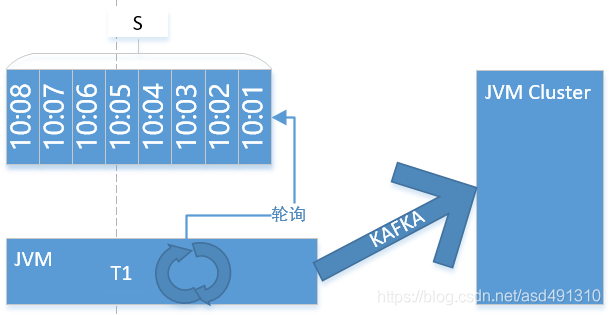
集合S按时间排序,T1轮询队头若干个元素,判断是否符合条件,若符合条件,就取出所有符合条件的元素。
假设每5分钟符合预期的元素有1000个以上,建议通过消息中间件发送给专门消息上发送的集群处理
假设每5分钟符合预期的元素在1000以内,建议采用Reactor线程池模式。
方案思考:
优点:实现简单,轮询消耗资源少
缺点:按延迟时间建立延迟队列,建议按1、5、10分钟做延迟队列,不建义随意创建延迟队列,不好维护,一个队列最大吞吐量为单台Redis的吞吐量。
数据结构
假设每5分钟内的订单数据为10000以内,5秒轮询一次
a. Sorted sets,timestamp为score
1. 查找元素是否到达可发送时间:
ZREMRANGEBYSCORE key min max
时间复杂度: O( log(N)+ M),其中 N 是已排序集合中元素的数量,M 是由操作移除的元素数量,复杂度为1004
注意:这里不使用ZCOUNT key min max
时间复杂度: O( log(N)),其中 N 是有序集合中元素的数量。复杂度为4。当ZREMRANGEBYSCORE 没有返回数据时时间复杂度均为O( log(N)),同ZREMRANGEBYSCORE 可简化应用代码逻辑,查找、获取数据、删除数据代码统一了。也可取一个元素存储在本地做轮询。减少轮询对Redis的开销
2. 删除已移除购物车的元素
ZREM key member [member ...]
时间复杂度: O( M * log(N)),其中 N 是有序集合中元素的数量,M 是要移除的元素的数量,复杂度为4*1
3. 新增元素
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
时间复杂度:添加每个项目的O(log(N)),其中N是排序集合中元素的数量,复杂度为4
延迟时间内数据量10000以内,Sorted sets为笔者建议数据结构,数据量在往上建议,查找元素步骤与获取数据步骤分离,减少对Redis的压力。
b. List ,按插入顺序存储
假设秒级误差可以忽略,那么从5秒级的视角看,List也是一个有效有序的列表,且符合业务预期
1. 查找元素是否到达可发送时间:
LINDEX key index
时间复杂度: O(N)其中N是要到达索引处元素的遍历元素的数量。
LINDEX key 0 查询列表第一个元素,复杂度为1
2. 删除已移除购物车元素
LREM key count value,时间复杂度为O(N),不建议使用。移除购物车的订单建议使用string结构存储,有效期为10分钟。
不支持
3. 新增元素
lpush/rpush,复杂度为1
4. 获取元素
lpop/rpop,复杂度为1

















 8228
8228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









