






引言
为了紧跟人工智能领域的最新进展,我们转向了LLM基准测试,以此来衡量哪些LLM处于领先地位。从最广为人知的基准测试——Open LLM排行榜开始,我们立刻发现排行榜的前10名几乎被命名中包含“MoE”的模型所霸占!
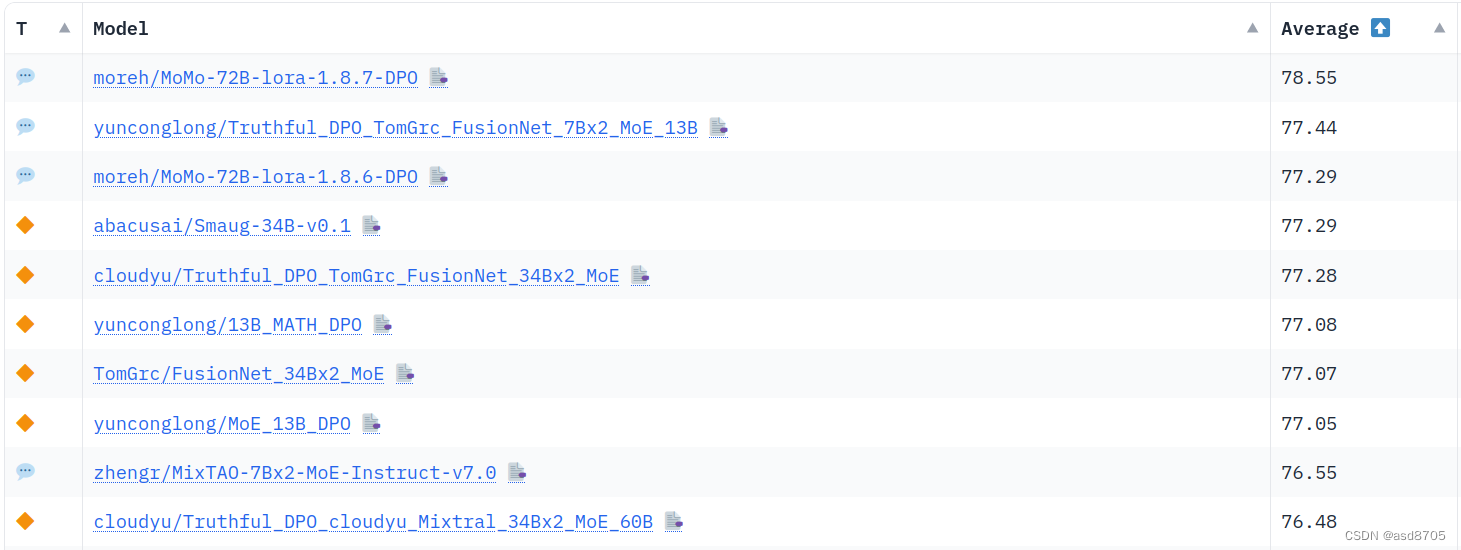
为了证实这一趋势,我们转向了Chatbot Arena基准测试,这是评估最佳整体语言模型的标准。在这里,顶级10名又一次被MoE所主宰!实际上,GPT4被怀疑就是其中之一,并且它与Mistral的模型Mixtral(Mix表明其MoE架构)并肩出现。
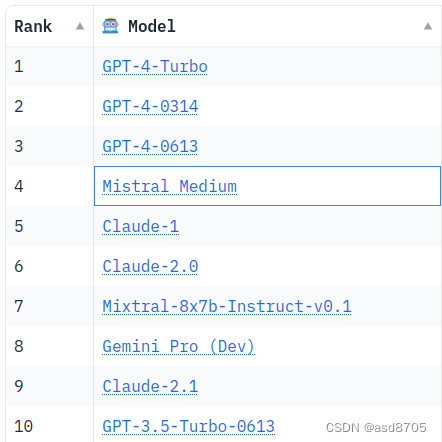
面对这一现象,引入MoE(Mixture-of-Experts)是什么以及使用它们带来的性能提升变得至关重要。
混合专家(MOE):预期
乍一看,混合专家似乎是提供绝佳解决方案的法宝,它承诺:
更好的性能,
更快(因此成本更低)的模型训练,
显著降低推理成本。
但是什么是MoE呢?
让我们从解释如何提高LLM性能开始。目睹了深度学习历史性的兴起的机器学习专家,首先会简单地增加我们模型的参数数量。混合专家是一种更精细的方式来实现这一点。
混合专家的架构
什么是专家?它只是具有独特、独立学习权重的神经网络。

混合专家的第二个构建块是路由器:
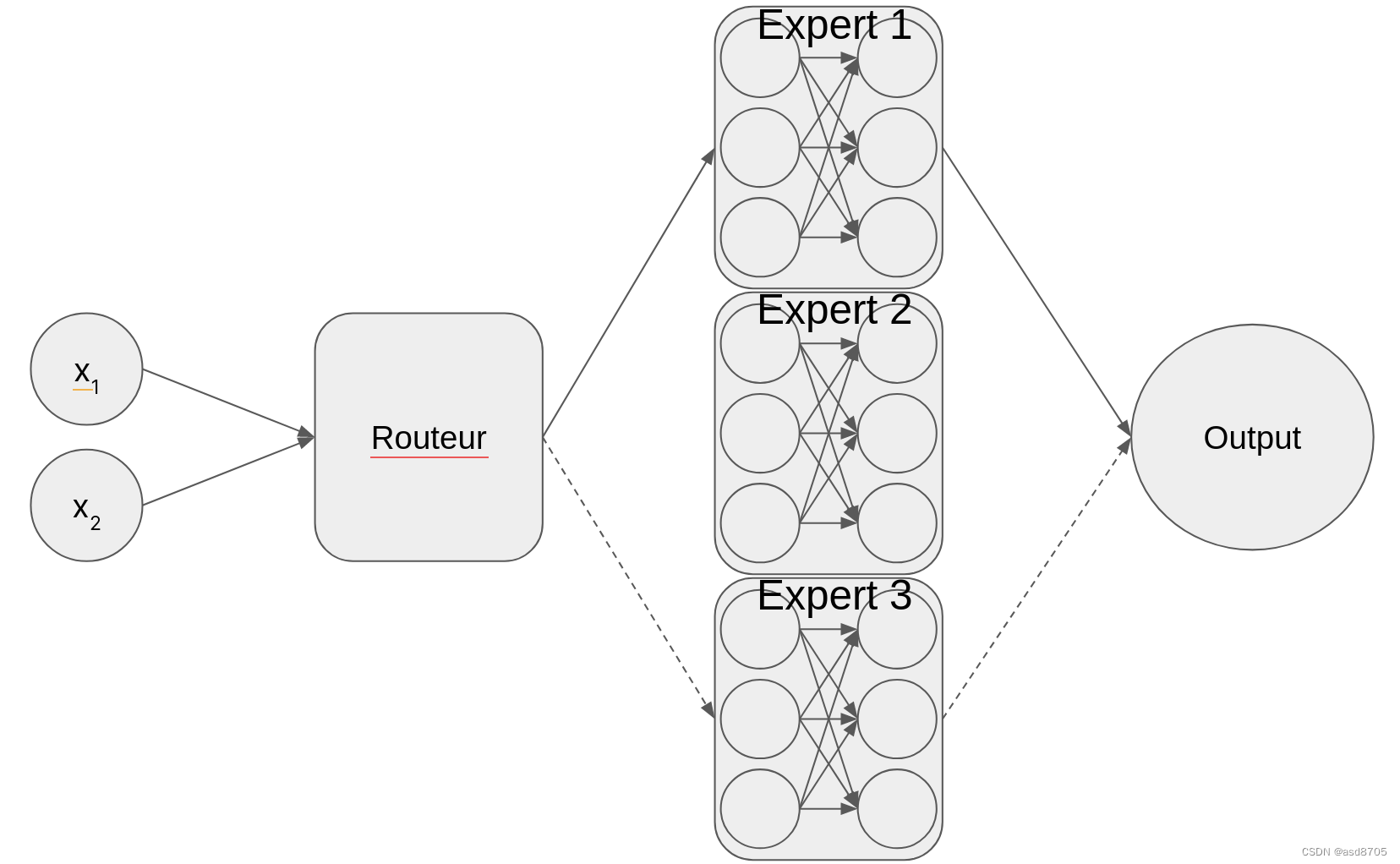
路由器将模型接收的令牌作为输入,并将其重定向到最合适的专家(们)。这是一个关键细节,因为每个令牌(~单词)可能会通过不同的专家。然后,各个专家的结果被聚合和归一化以形成模型输出。
更正式地说,路由器是一个学习模型(G),而MoE操作可以表示为以下方程(其中是专家网络):
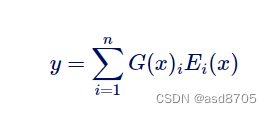

到目前为止,我们省略的一个重要细节是,在介绍中提到的MoE存在于Transformer架构中,这引入了一些细微差别。
专家及其路由机制被引入以替代Transformer架构中的前向传播块。注意力层是共享的(对于不太数学的人,这就是为什么Mistral 8x7b实际上是47b模型而不是56b模型的原因)。通过这种方式,我们可以看到每个Transformer块中的专家是不同的。
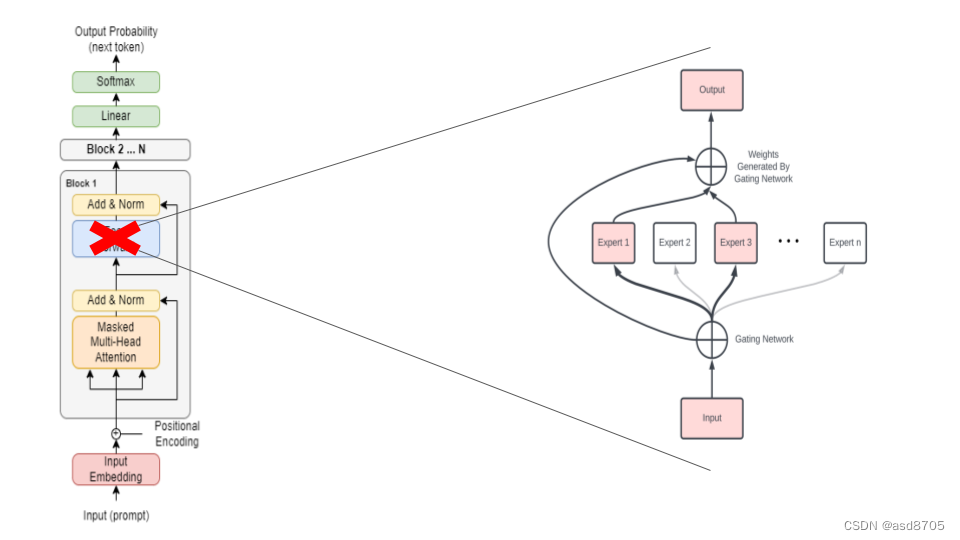
MoE的优势:
- 更有效的推理/预训练:MoE能够以额外的参数“免费”获得提升。实际上,Top-k机制确保了大部分专家并未被使用,因此在推理时,我们仅使用参数的一部分。通过路由机制优化这一比例,该机制同样被训练。
- 更经济的训练:MoE训练更为高效。通过将参数分配给不同的专家,需要计算的梯度数量显著减少。结果,训练速度更快,节省了时间和金钱!
专家的特殊化:
- 传统意义上的专家:我们通常认为专家是某一特定领域内有专长的人。这是否也适用于我们的MoE专家?
实际上,专家并非主题专家,这与我们的直觉相悖。确实,没有哪个专家在特定的Pile数据集主题上承担了显著高于其他专家的负载。唯一的例外是“DM Mathematics”,这似乎指向了一种语法上的专业化。
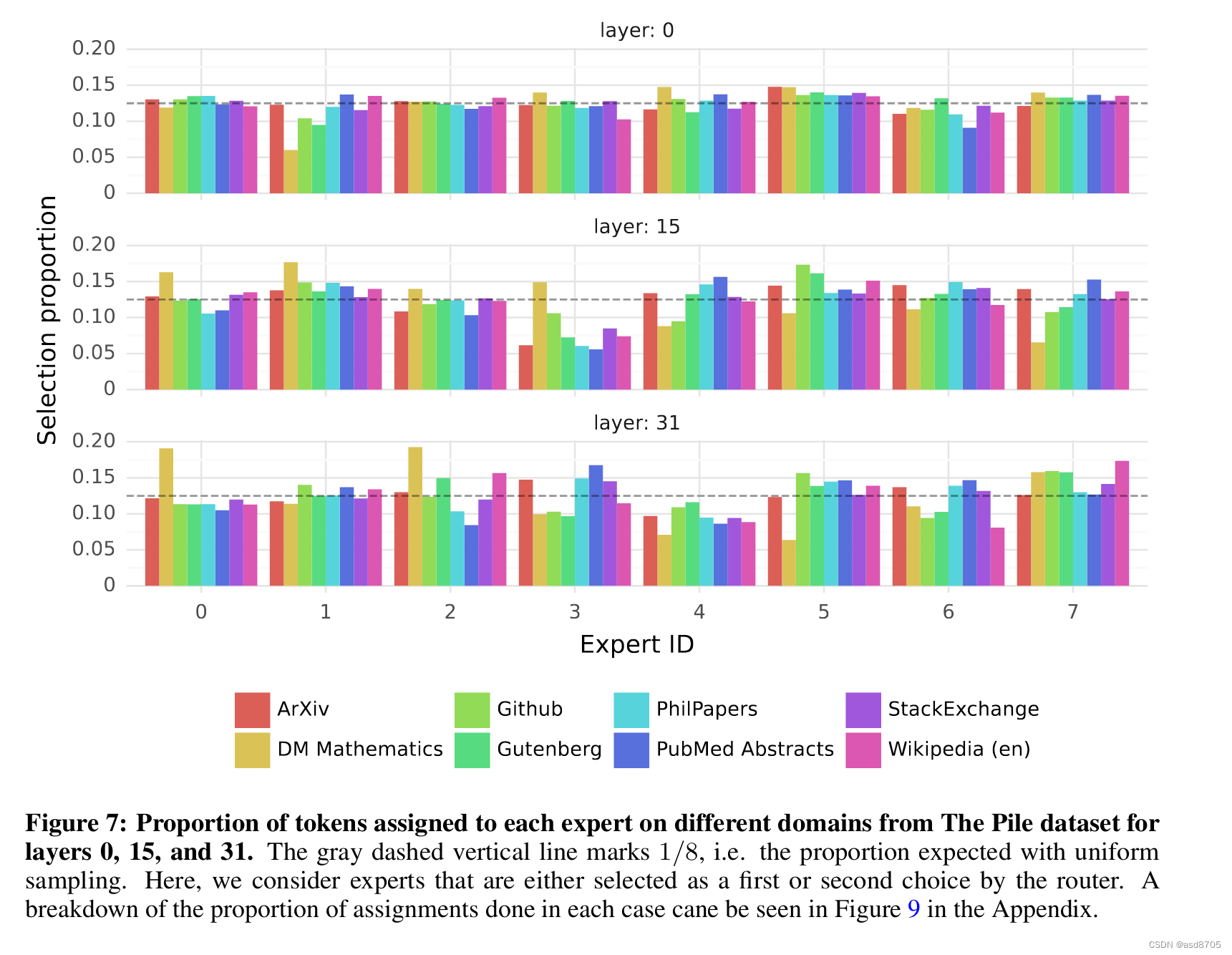
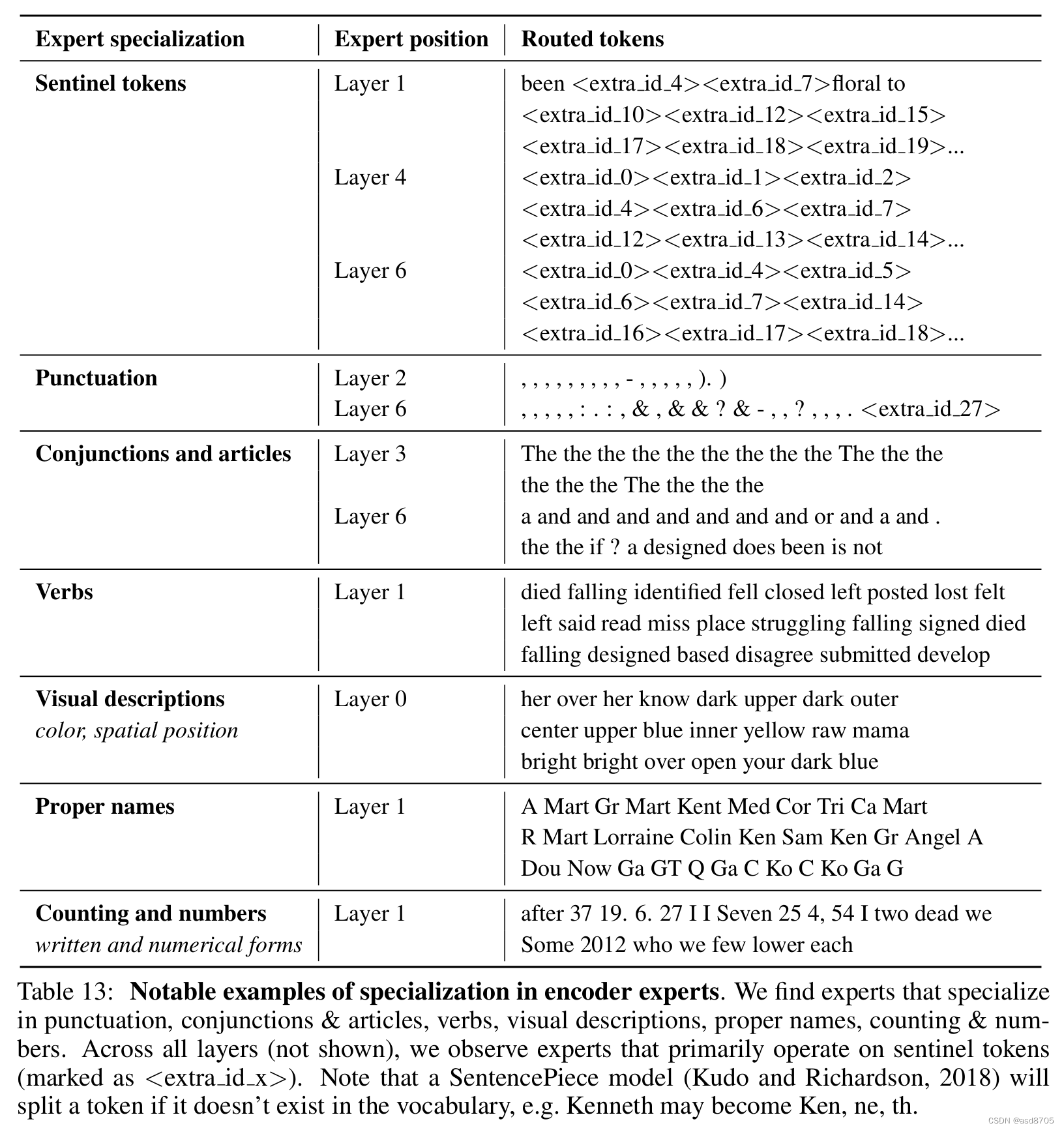
然而,似乎也有一些专家专门处理某些类型的标记,例如标点符号或连词。不过,这些专业化的结果仍然是例外,下表中选取的例子并没有明确的语义或语法专业化。
MoE的劣势:
除了它们的本质不同,MoE模型在微调时的行为与传统模型有所不同。MoE更容易过拟合。一般来说,专家的数量越少,模型越容易微调。但也有例外,例如在TriviaQA数据集上,MoE的微调表现更优秀。
尽管MoE只使用了部分参数,但仍然需要将整个模型及其所有专家加载到内存中。这就意味着需要配备具有VRAM(视频内存)的机器来选择MoE。
这一特性表明,如果拥有所需的VRAM资源并且需要高推理吞吐量,那么选择MoE是合适的。否则,密集型模型(相对于MoE而言)更适合。
结论:
混合专家是提高大语言模型性能的一种简单方法,且成本较低,推理成本也更低。然而,这种架构也伴随着自身的挑战。这种模型需要额外的内存资源(VRAM)才能加载,这同时降低了模型的适应性,使其在先验上更难微调。
简而言之,混合专家代表了性能提升的重要一步,但要充分利用其优势,需要在硬件和专业知识上进行重大投资。
References
- Blog huggingface: https: //huggingface.co/blog/moe
- Mistral paper: Mixtral of Experts
- Switch Transformer: arXiv
- MegaBlocks: ArXiv, Github


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









