



第一次报错
clickhouse_driver.errors.ServerException: Code: 202.
DB::Exception: Received from 10.128.55.14:9000. DB::Exception: Too many simultaneous queries. Maximum: 100. Stack trace
最开始CK出现问题是报上方所描述的错误,并发查询超过了限制100,这个问题最开始是以为我们的任务比较集中可能会会有超过100的可能,不过通过查询历史的执行记录发现,CK的分布式表查询会将查询发送给集群中有这张分布式表的节点查询。那其实假如说我在A节点查询分布式表 TEST 那 查询可能会被广播到 A节点 和 B节点 和 C节点。那经过排查,在生产环境中13、14节点在查询时超过了100个并发。
第一次报错的解决方案
这个问题实际上网上是有解决方案的 就是增加可以并发查询的上限 调整成400左右 每个节点都需要调整,这个参数是可以做到热更新无需重启服务。当然 只有 13、14节点超过并发限制这是一个伏笔是一个隐患。
/etc/clickhouse-server/config.xml文件中的<max_concurrent_queries>100</max_concurrent_queries>参数可增大观察优化,这个是全局的配置参数,改完后需要重启ck集群,默认是100,改完后可SELECT * FROM system.server_settings WHERE name = 'max_concurrent_queries';查询验证
第二次报错
来到了今天的主角
ru.yandex.clickhouse.except.ClickHouseUnknownException: ClickHouse exception, code: 1002, host: 10.128.55.32, port: 8124; Code: 159. DB::Exception: Watching task /clickhouse/task_queue/ddl/query-0001016086 is executing longer than distributed_ddl_task_timeout (=1200) seconds. There are 1 unfinished hosts (0 of them are currently active), they are going to execute the query in background. (TIMEOUT_EXCEEDED) (version 22.2.2.1)
这个报错是由于CK的分布式DDL在某一台节点上执行超时所导致的,那我们上面说了 13 、14这两个节点并发查询超过了100,这就说明13 、14 堆积了查询处理速度跟不上其他集群
查询13 、14 的system.replication_queue表可以看到 13 、14节点堆积了很多合并请求
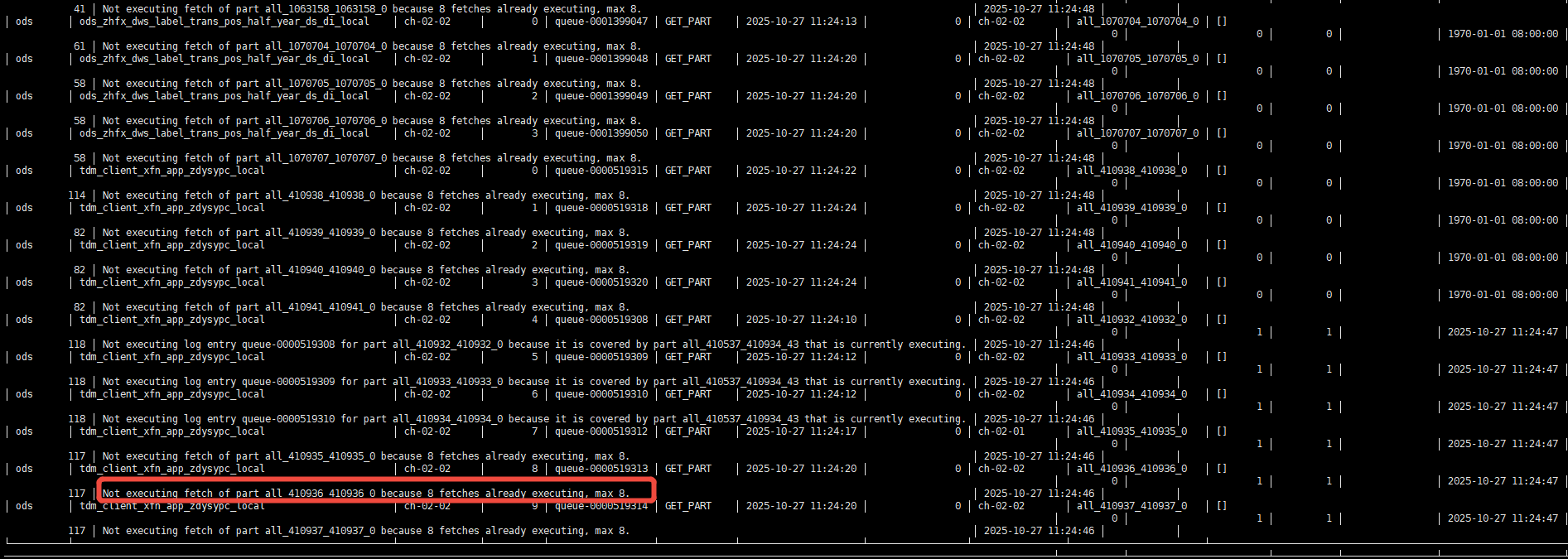
再看报错的 ddl语句
SELECT hostName() AS current_node, entry, query, cluster, status, exception_code, exception_text FROM system.distributed_ddl_queue WHERE query LIKE '%OPTIMIZE TABLE cdm.dwd_tyzt_bussiness_count_local%FINAL%' ORDER BY entry DESC LIMIT 10
这里截图没了,大概就是13 14 节点执行时间超长(ddl语句就算是报了超时,还是会在后台执行完)所以其实是可以看到13 14 节点执行时间的 我这边的执行时间有30分钟左右了。
然后我们在通过system.distributed_ddl_queue表中的entry字段到ck日志中去找对应的ddl执行日志
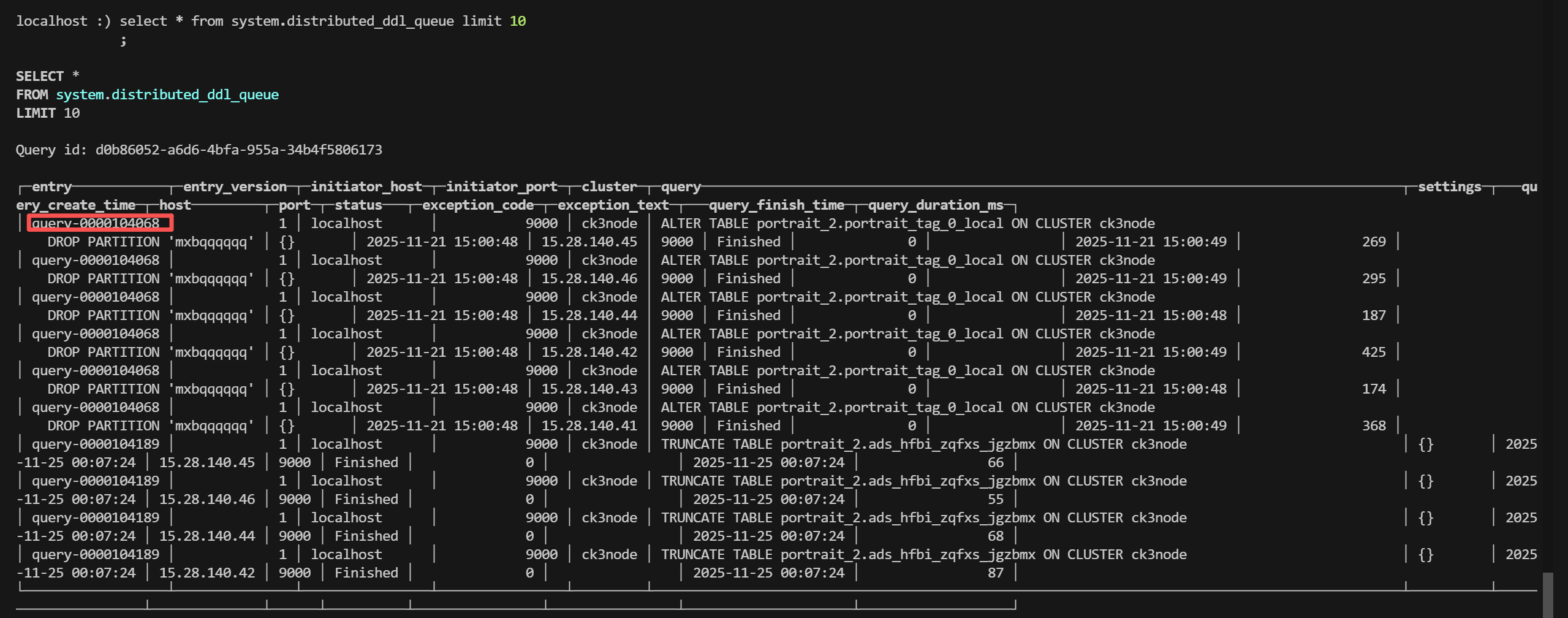
每个节点都看一下 tail -n 100000 /data/clickhouse/log/clickhouse-server/clickhouse-server.log | grep --color=always -A 40 'query-0000104338' 根据实际的entry搜索
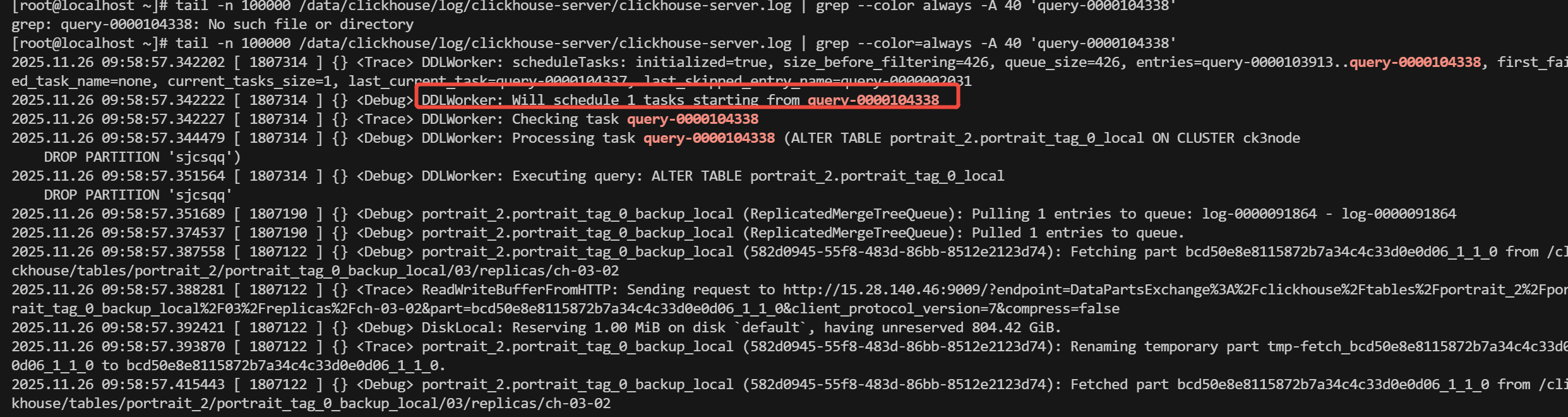
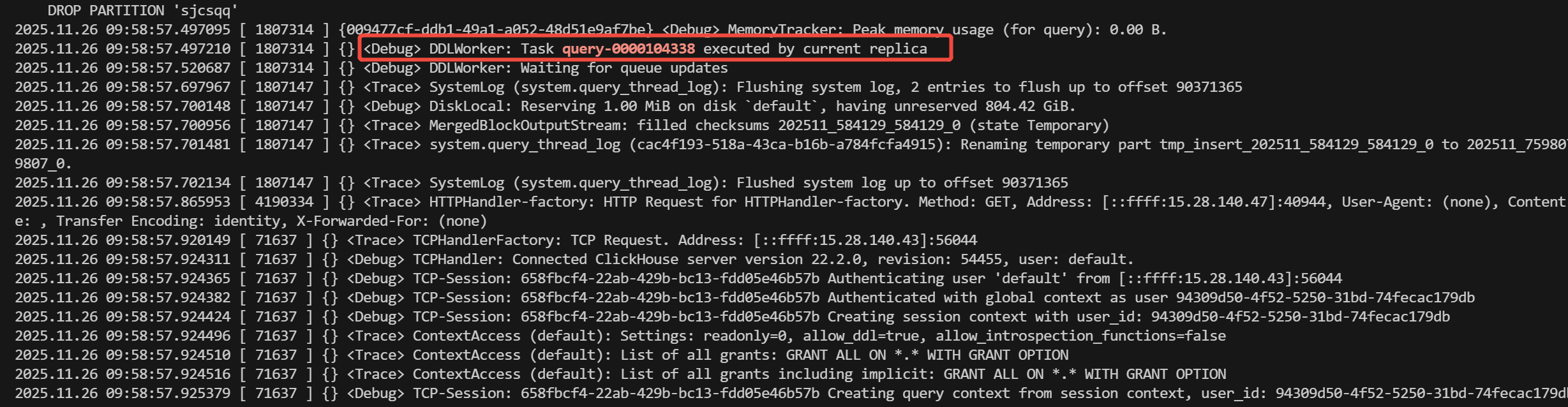
观察这两个时间,我发现 13、14节点平均执行一个分布式ddl会需要3-7秒 而其他节点都是秒执行
这样一来二去 13 、 14 节点处理ddl的速度会越来越慢 导致会延迟超过30分钟 很恐怖。
解决方案
第一天。我选择增加ddl超时时间限制,想着通过增加超时时间来规避超时报错。结果第二天还是会超时。。
理论上我的ck节点配置都差不多 没有可能延迟这么高。。我使用top命令看了一下cpu使用情况。。结果发现。。。zk的cpu使用率非常非常高,而我的13 ck节点 部署了一个zk。13和14又是同一个分片副本。于是我用arthas 看了一下zk的jvm 情况。。。结果发现 前辈在部署zk的时候使用默认jvm配置。。应该是1000m的堆内存。被打爆了 zk在疯狂gc试图挤出一些内存来用 导致cpu飙升,以及 ck的分布式任务依靠zk来实现数据的交换。那也许13 14 用到了当前的zk (其他节点的zk堆内存也块满了 但是没13节点这么严重)。所以最后我调整了zk的jvm启动参数 重启zk。并且添加ck 合并分片的线程数量(8)个调整到32个。这个问题彻底解决。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









