







在优化理论中,目标函数会有多种形式:如果目标函数和约束条件都为变量的线性函数, 称该问题为线性规划; 如果目标函数为二次函数, 约束条件为线性函数, 称该最优化问题为二次规划; 如果目标函数或者约束条件均为非线性函数, 称该最优化问题为非线性规划。每个线性规划问题都有一个与之对应的对偶问题,对偶问题有非常良好的性质,以下列举几个:
- 对偶问题的对偶是原问题;
- 无论原始问题是否是凸的,对偶问题都是凸优化问题;
- 对偶问题可以给出原始问题一个下界;
- 当满足一定条件时,原始问题与对偶问题的解是完全等价的;
比如下边这个例子,虽然原始问题非凸,但是对偶问题是凸的:
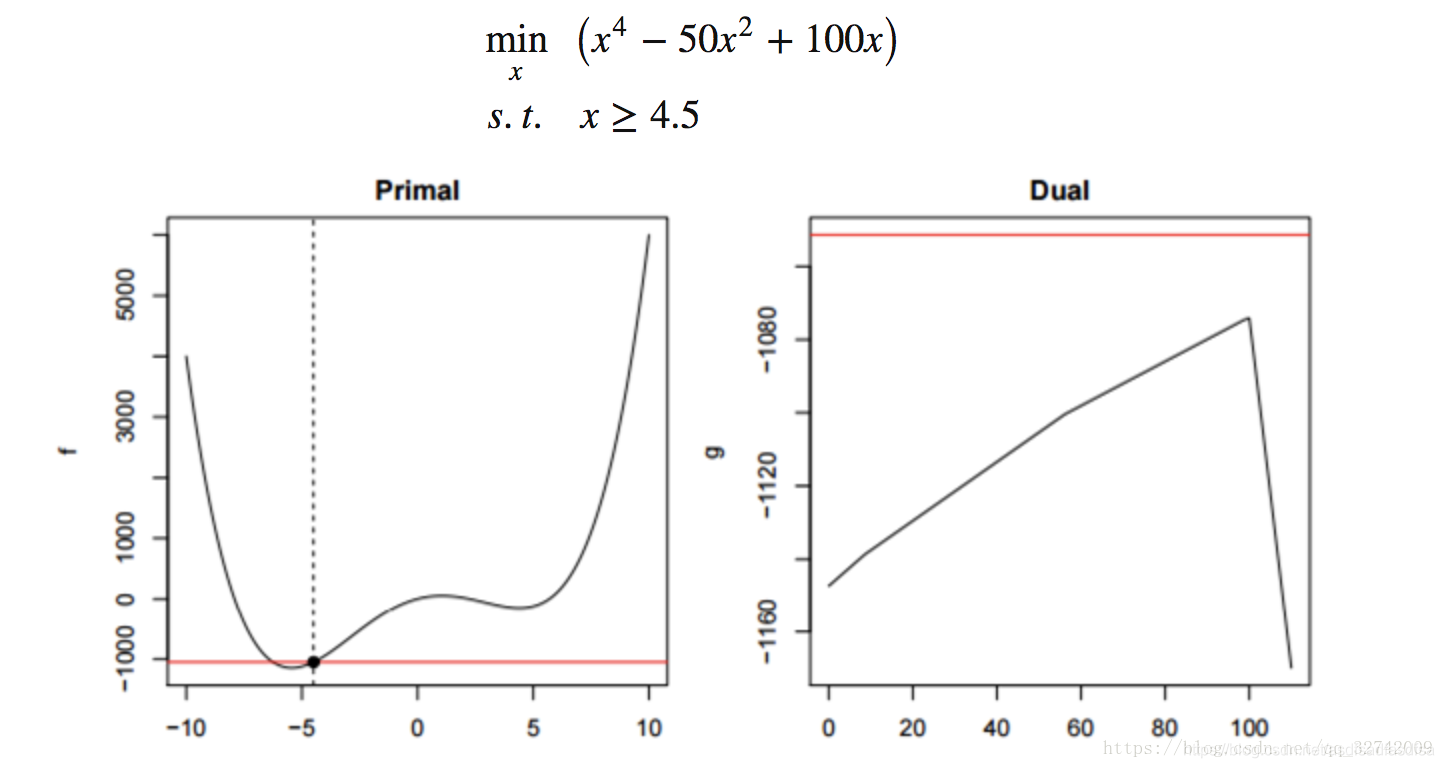
原问题与对偶问题的关系:简单了说,如果原问题是一个在一定的约束下,最大化一个企业的生产利润。那么它的对偶问题就是希望用最小代价把这个企业的所有资源收购过来。
原问题与对偶问题简单例子:
原问题:
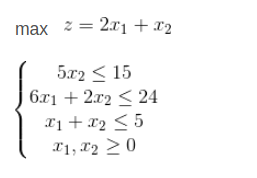
对偶问题:
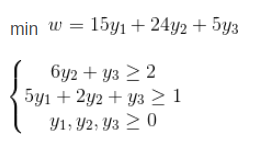
原问题与对偶问题变换规则:
- 原问题是求极大,对偶问题就是求极小,反之同理。
- 一个问题中的约束条件个数等于另一个问题中的变量数。
- 一个问题中目标函数的系数是另一个问题中约束条件的右端项。
- 约束条件在一个问题中为“<=”,则在另一个问题中为“>=”。
原问题与对偶问题的性质:
- 弱对偶性
- 最优性
- 无界性
- 强对偶性
- 互补松弛性
开始进入正题!
原始问题
首先给出不等式约束优化问题:
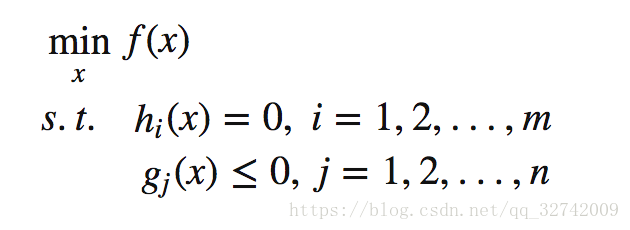
定义 Lagrangian 如下:
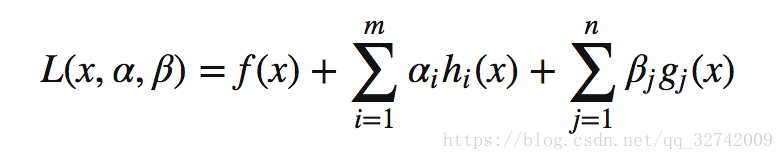
根据以上 Lagrangian 便可以得到一个重要结论:

这段话需要多读几遍,确保理解。后面半句中,如果等式条件不被满足,且等式条件为负,那就让乘子变成负无穷大,同样会得到L无穷大,依旧会导致问题无解。故必须满足约束条件。
对偶问题
上式与原优化目标等价,将之称作原始问题 , 将原始问题的解记做,如此便把带约束问题转化为了无约束的原始问题,其实只是一个形式上的重写,方便找到其对应的对偶问题,首先为对偶问题定义一个对偶函数(dual function) :
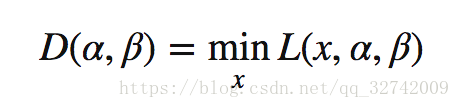

直观地,可以理解为最小的里最大的那个要比最大的中最小的那个要大。具体的证明过程如下:

这个性质便叫做弱对偶性(weak duality),对于所有优化问题都成立,即使原始问题非凸
原始问题和对偶问题关系:

之前提过无论原始问题是什么形式,对偶问题总是一个凸优化的问题,这样对于那些难以求解的原始问题 (甚至是 NP 问题),均可以通过转化为偶问题,通过优化这个对偶问题来得到原始问题的一个下界, 与弱对偶性相对应的有一个强对偶性(strong duality) ,强对偶即满足:
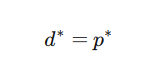
强对偶是一个非常好的性质,因为在强对偶成立的情况下,可以通过求解对偶问题来得到原始问题的解,在 SVM 中就是这样做的。当然并不是所有的对偶问题都满足强对偶性 ,在 SVM 中是直接假定了强对偶性的成立,其实只要满足一些条件,强对偶性是成立的,比如说 Slater 条件与KKT条件。
Slater 条件

也就是说如果原始问题是凸优化问题并且满足 Slater 条件的话,那么强对偶性成立。需要注意的是,这里只是指出了强对偶成立的一种情况,并不是唯一的情况。例如,对于某些非凸优化的问题,强对偶也成立。SVM 中的原始问题 是一个凸优化问题(二次规划也属于凸优化问题),Slater 条件在 SVM 中指的是存在一个超平面可将数据分隔开,即数据是线性可分的。当数据不可分时,强对偶是不成立的,这个时候寻找分隔平面这个问题本身也就是没有意义了,所以对于不可分的情况预先加个 kernel 就可以了。
KKT条件
假设 与
分别是原始问题(并不一定是凸的)和对偶问题的最优解,且满足强对偶性,则相应的极值的关系满足:
这里第一个不等式成立是因为 为
的一个极大值点,最后一个不等式成立是因为
,且
,(
是之前 (*) 式的约束条件)因此这一系列的式子里的不等号全部都可以换成等号。根据公式还可以得到两个结论:
1)第一个不等式成立是因为 为
的一个极大值点,由此可得:
2)第二个不等式其实就是之前的 (*) 式, 都是非正的,所以这里有:
也就是说如果,那么必定有
;反过来,如果
那么可以得到
,即:
这些条件都似曾相识,把它们写到一起,就是传说中的 KKT (Karush-Kuhn-Tucker) 条件:
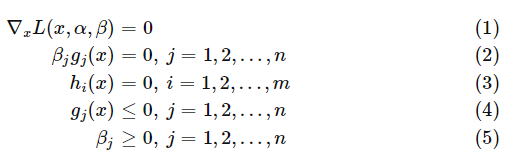
总结来说就是说任何满足强对偶性的优化问题,只要其目标函数与约束函数可微,任一对原始问题与对偶问题的解都是满足 KKT 条件的。即满足强对偶性的优化问题中,若 为原始问题的最优解,
为对偶问题的最优解,则可得
满足 KKT 条件
总结:
对于求解最优解问题,为了解决约束条件(不管是等式约束还是不等式约束)引入了拉格朗日因子把约束添加到目标式子中,通过对偶方式把问题转移到求解拉格朗日因子上;
KKT条件是针对不等式约束下的强对偶问题最优解的限制条件, 对于等式约束的强对偶问题最优解无需KKT条件约束?
强对偶问题求解的技巧是调换最大最小目标, 然后令最大最小目标的偏导数等于, 最大最小问题中的参数相互带入即可求解
具体可以对比SVM和MaxEnt对偶问题应用, 前者为不等式约束, 后者为等式约束
参考:














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









