




在学习和搭建 SSM(Spring + SpringMVC + MyBatis)框架 时,明确编写顺序能帮助我们更清晰地理解各组件的依赖关系和整体流程。SSM 框架的核心是分层架构,各层职责明确,编写顺序需遵循“从基础到上层、从配置到业务”的逻辑。以下是详细的编写顺序及理由说明:
一、整体架构与分层逻辑
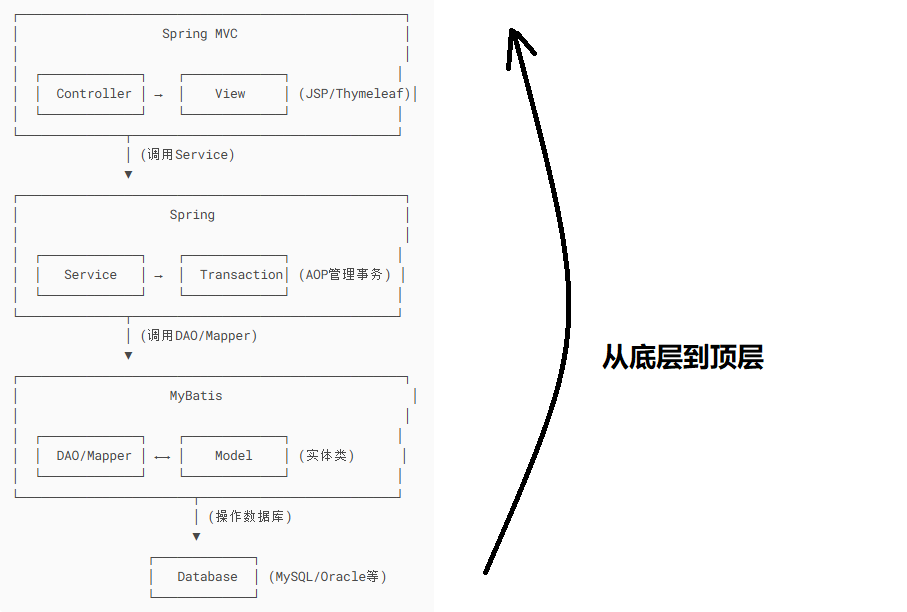
SSM 框架遵循经典的 MVC 分层架构,结合持久层、业务层、控制层的职责划分,各层依赖关系如下:
数据库设计 → 实体类(Model)→ 持久层(MyBatis)→ 业务层(Service)→ 控制层(Controller)→ 视图层(View)
同时,框架的配置文件需要优先准备,为各层提供运行环境支持。
二、详细编写顺序及步骤
1. 环境准备与基础配置(优先完成)
在编写业务代码前,需先搭建框架运行的基础环境,包括依赖管理、核心配置文件等。
-
步骤1:创建 Maven 项目并引入依赖
在pom.xml中添加 SSM 框架的核心依赖,包括:- Spring 核心依赖(
spring-context、spring-beans等) - SpringMVC 依赖(
spring-webmvc) - MyBatis 依赖(
mybatis)及 MyBatis 与 Spring 的整合包(mybatis-spring) - 数据库驱动(如 MySQL 的
mysql-connector-java) - 连接池(如
druid或c3p0) - Web 相关依赖(
javax.servlet-api、jsp-api等)
- Spring 核心依赖(
-
步骤2:编写核心配置文件
配置文件是框架运行的基础,需按以下顺序编写(因部分配置依赖其他配置):- 数据库连接配置(如
db.properties):存储数据库 URL、用户名、密码等信息,供后续 Spring 配置引用。 - Spring 配置文件(如
applicationContext.xml):- 配置数据源(加载
db.properties中的信息)。 - 配置 MyBatis 的 SqlSessionFactory(整合 MyBatis,指定 mapper 映射文件路径)。
- 配置 Mapper 接口的扫描(通过
MapperScannerConfigurer自动生成 Mapper 实现类)。 - 配置事务管理(基于 Spring 的声明式事务)。
- 配置数据源(加载
- SpringMVC 配置文件(如
spring-mvc.xml):- 配置注解驱动(
mvc:annotation-driven),支持@Controller、@RequestMapping等注解。 - 配置组件扫描(指定 Controller 所在的包路径)。
- 配置视图解析器(如 InternalResourceViewResolver,指定 JSP 视图的前缀和后缀)。
- 配置注解驱动(
- Web.xml 配置:
- 配置 Spring 的监听器(
ContextLoaderListener),加载applicationContext.xml。 - 配置 SpringMVC 的前端控制器(
DispatcherServlet),加载spring-mvc.xml并指定拦截路径(如*.do或/)。 - 配置字符编码过滤器(
CharacterEncodingFilter),解决中文乱码问题。
- 配置 Spring 的监听器(
- 数据库连接配置(如
2. 业务代码编写(按分层顺序)
在配置文件就绪后,按“数据层 → 业务层 → 控制层 → 视图层”的顺序编写业务代码,确保下层为上层提供支持。
-
步骤1:设计数据库表
根据业务需求创建对应的数据库表(如user、product等),明确表结构、字段类型、主键及关联关系(如需)。 -
步骤2:编写实体类(Model/Entity)
实体类是数据库表的映射,每个类对应一张表,每个属性对应表中的一个字段。
例如:数据库表user对应实体类User,包含id、username、password等属性,并生成 getter/setter 方法。 -
步骤3:编写持久层(MyBatis 的 Mapper)
持久层负责与数据库交互,通过 MyBatis 实现 CRUD 操作:- 编写 Mapper 接口:定义数据操作方法(如
UserMapper接口,包含selectById、insert等方法)。 - 编写 Mapper 映射文件(XML):
- 与 Mapper 接口同名,放置在资源目录下(如
src/main/resources/mapper/UserMapper.xml)。 - 通过
<select>、<insert>等标签编写 SQL 语句,并与 Mapper 接口的方法通过id关联。 - 注意:MyBatis 也支持注解方式编写 SQL,但复杂 SQL 建议用 XML 方式。
- 与 Mapper 接口同名,放置在资源目录下(如
- 编写 Mapper 接口:定义数据操作方法(如
-
步骤4:编写业务层(Service)
业务层封装核心业务逻辑,依赖持久层的 Mapper 接口:- 编写 Service 接口:定义业务方法(如
UserService接口,包含login、register等方法)。 - 编写 Service 实现类:
- 实现 Service 接口,通过
@Service注解标记为 Spring 管理的 Bean。 - 通过
@Autowired注入 Mapper 接口实例,调用其方法操作数据库。 - 在需要事务管理的方法上添加
@Transactional注解(需配合 Spring 事务配置)。
- 实现 Service 接口,通过
- 编写 Service 接口:定义业务方法(如
-
步骤5:编写控制层(Controller)
控制层接收用户请求,调用业务层处理,并返回视图或数据:- 编写 Controller 类:
- 通过
@Controller注解标记,通过@RequestMapping指定请求路径。 - 通过
@Autowired注入 Service 接口实例,调用业务方法处理请求。 - 通过
@RequestParam或@RequestBody接收请求参数,通过Model或ModelAndView传递数据到视图,或通过@ResponseBody返回 JSON 数据。
- 通过
- 编写 Controller 类:
-
步骤6:编写视图层(View)
视图层负责展示数据,通常使用 JSP、HTML 等:- 在 JSP 中通过 EL 表达式(
${})或 JSTL 标签获取 Controller 传递的数据。 - 编写表单页面(如登录页、注册页),表单提交路径对应 Controller 的
@RequestMapping路径。
- 在 JSP 中通过 EL 表达式(
3. 测试与运行
- 部署项目到 Tomcat 服务器,启动服务器。
- 通过浏览器访问视图页面,提交请求,验证各层是否正常工作(如数据库操作是否成功、业务逻辑是否正确、视图是否正常展示)。
三、核心依赖关系总结
编写顺序的核心是遵循“依赖前置”原则:
- 配置文件依赖:
db.properties→applicationContext.xml(Spring 核心)→spring-mvc.xml(SpringMVC)→web.xml(整合 Web 环境)。 - 业务代码依赖:数据库表 → 实体类 → Mapper(持久层)→ Service(业务层)→ Controller(控制层)→ View(视图层)。
按此顺序编写,可有效减少因依赖缺失导致的错误,清晰理解 SSM 框架的运行流程。
简单整理一下:
SSM项目文件编写顺序建议
以下是基于SSM(Spring+SpringMVC+MyBatis)框架的项目文件合理编写顺序,分为几个主要阶段:
1. 项目基础搭建阶段
- pom.xml - 配置项目依赖(Spring, SpringMVC, MyBatis等)
- database.sql - 创建数据库表结构
- jdbc.properties - 配置数据库连接信息
- web.xml - 配置Spring和SpringMVC的DispatcherServlet
2. Spring配置阶段
- spring-context.xml - 配置Spring核心(扫描包、数据源、事务等)
- spring-mvc.xml - 配置SpringMVC(视图解析器、静态资源等)
- mybatis-config.xml - MyBatis基础配置
- logback.xml - 日志系统配置
3. 实体与持久层
- entity/User.java - 创建用户实体类
- mapper/UserMapper.java - 用户Mapper接口
- mybatis/mapper/UserMapper.xml - 用户Mapper的SQL映射文件
4. 业务逻辑层
- service/UserService.java - 用户服务接口
- service/impl/UserServiceImpl.java - 用户服务实现类
5. 控制器层
- controller/IndexController.java - 首页控制器
- controller/UserController.java - 用户相关控制器
6. 视图层
- views/user/list.jsp - 用户列表页面
- views/user/add.jsp - 用户添加页面
- views/user/edit.jsp - 用户编辑页面
7. 文档与构建
- README.md - 项目说明文档
- 让Maven构建生成target/目录
补充说明
- 这个顺序遵循了从底层到上层的开发原则,先配置后实现
- 实际开发中可能会根据需要进行调整,比如先写测试用例(TDD)
- 每个阶段完成后可以进行简单的测试验证
- 对于团队开发,可以按模块并行开发

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









