







这个实验主要爬取新闻网站首页的新闻内容保存到本地,爬取内容有标题、时间、来源、评论数和正文。
工具:python 3.6 谷歌浏览器
爬取过程:
###一、安装库:urllib、requests、BeautifulSoup
1、urllib库:Urllib是python内置的HTTP请求库。用这个库可以用python请求网页获取信息。
主要用到的函数:
data = urllib.request.urlopen(qurl).read()
#qurl为网页的网址,利用这个函数可以获取该网页的内容data
2、requests库:requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多。这个实验我两个库都用了,作用类似。
data = requests.get(url).text
3、BeautifulSoup库
当我们通过上面两个库获得了网页的数据的时候,我们需要从数据中提取我们想要的,这时BeautifulSoup就派上了用场。BeautifulSoup可以为我们解析文档,抓取我们想要的新闻标题、正文内容等。
4、re 库
正则表达式的库,正则表达式大家都明白的。
###二、爬取新闻首页,得到所有要爬取新闻的链接
因为新闻首页首页只有新闻的标题,新闻的具体信息要点进标题链接进入另一个网页查看。所以我们首先要在新闻首页把所有要爬取新闻的链接保存到一个txt文件里。先上代码再解释。
def getQQurl(): #获取腾讯新闻首页的所有新闻链接
url = "http://news.qq.com/"
urldata = requests.get(url).text
soup = BeautifulSoup(urldata, 'lxml')
news_titles = soup.select("div.text > em.f14 > a.linkto")
fo = open("D:/news/QQ链接.txt", "w+") # 创建TXT文件保存首页所有链接
# 对返回的列表进行遍历写入文件
for n in news_titles:
title = n.get_text()
link = n.get("href")
fo.writelines(link + "\n")
fo.close()
函数的前两行代码前面已经解释了,就解释一下三四行代码吧。
soup = BeautifulSoup(wbdata, ‘lxml’) #解析获取的文件,解析器为lxml
news_titles = soup.select(“div.text > em.f14 > a.linkto”)
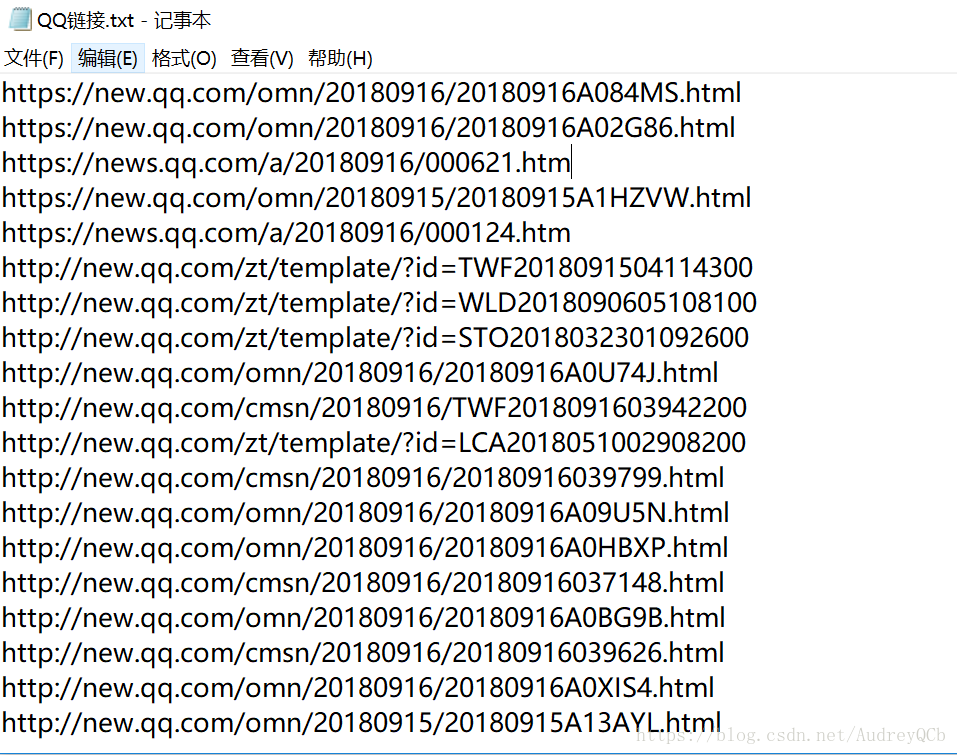
分析新闻网页源代码的时候我们可以发现,首页新闻的链接大多数在图片中的地方
由此我们可以利用soup.select()把所有 标签div.text > em.f14 > a.linkto对应的数据挑选出来,因此是一个列表。再用get(“herf”)把链接挑选出来,写在TXT文件里面。
一般新闻网站首页的新闻链接按板块不同在源代码中的标签也不同,挑选规则也不同。如果想挑选多个板块的新闻的话可以多写几种规则。

###三、根据链接文件依次爬取每个链接对应的新闻数据
当把所有新闻的链接写在一个文件后,我们剩下要做的就是循环读取每个链接,利用第二步得到链接类似的办法得到新闻的相关数据。
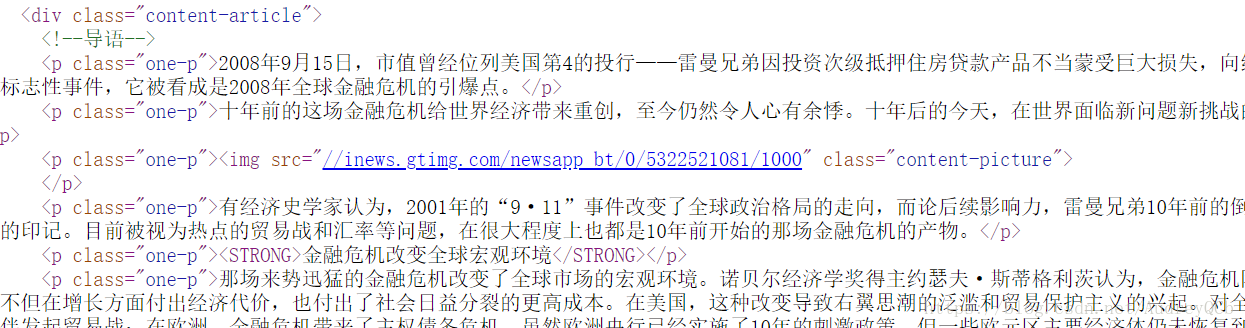
分析新闻的网页源代码我们可以发现,标题都放在title标签下,而正文内容都在p标签下,由此我们可以用
content = soup.select(‘p’) # 选择正文内容
title = soup.select(‘title’) # 选择标题 将它们挑选出来,时间和来源等信息可以用类似的方法挑选。
当这些信息被挑选出来后,它们都是以列表的形式,所以我们要将它们依次写入文件,整体代码如下。
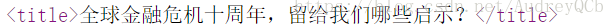
def getqqtext():
qqf = open("D:/news/QQ链接.txt", "r")
qqurl = qqf.readlines() # 读取文件,得到一个链接列表
i = 0
# 遍历列表,请求网页,筛选出正文信息
for qurl in qqurl:
try:
data = urllib.request.urlopen(qurl).read()
data2 = data.decode("gbk", "ignore")
soup = BeautifulSoup(data2, "html.parser") # 从解析文件中通过select选择器定位指定的元素,返回一个列表
content = soup.select(' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









