






一、Hadoop
Hadoop是有Apache基金会所开发的分布式系统处理架构,是一个能够对大量数据进行分布式处理的软件框架,以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop框架最核心的设计就是HDFS(Hadoop Distributed File System)和MapReduce。
HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算。
对外部客户机而言,HDFS就像一个传统的分级文件系统,可以创建、删除、移动或重命名文件。个人理解我们现在使用的网盘就是这种思想。
MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
MapReduce的思想是“分而治之”,mapper负责将严格复杂的任务分成若干简单的任务,分成的简单任务规模会大大缩小,且能够并行计算,彼此之间不存在依赖关系。reducer负责将map之后得到的结果进行汇总。
二、Hive
首先,需要了解数据仓库。
数据仓库:一个更好地支持企业或者组织的决策分析处理的面向主题的、集成的、不可更新的、随时间不断变化的数据集合。
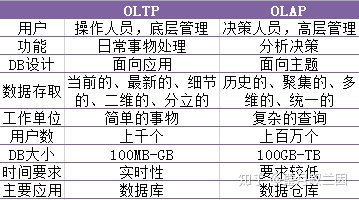
传统的数据库,主要是面对OLTP(联机事物处理),比如银行的交易;
数据仓库主要面对OLAP(联机分析处理),侧重决策分析。
关于OLTP与OLAP,比较如下:
数据仓库在数据行业扮演的角色如下图所示

数据源是由多种方式得来的,比如爬虫、企业内部数据等,通过对二手域名交易平台数据源里面的数据进行ETL操作,将数据存储进数据仓库,利用OLAP服务器进行决策分析,最后生成数据报表或者进行数据挖掘。
ETL:一种数据仓库技术,是指从数据源进行抽取(extract)、转换(transform)和加载(load)的过程。
数据仓库和OLAP服务器是基于多维数据模型的。多维数据模型将数据看做数据方体,通过维度(dimension)和度量(measure)来定义。
多维数据模型可以通过关系型数据库或者多维数组来实现。

关系型数据库适应性、伸缩型和扩展性好,不存在数据稀疏问题,但访问效率较慢;而相应地,多维数组则是存储效率高,访问速度快,但不同维度的访问效率差别较大(可以分成几个数据快的方式存储来解决),且数据稀疏时将影响效率(采用数据压缩技术来解决)。
多维数据操作主要有以下几类:
- 切片(slice)和切块(clice):在SQL中加入WERE/HAVING进行过滤。
- 上卷(roll up)和下钻(drill down):不同粒度的转换
- 旋转(pivoting):转动观察数据的角度
简单了解数据仓库之后,再来看看Hive。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据映射为一张数据表,可以将SQL语句转化为MapReduce任务进行运行。
个人的理解,首先Hive是依赖于Hadoop存在的,其次因为MapReduce语法较复杂,Hive可以将较简单的SQL语句转化成MapReduce进行计算。
Hive的优缺点:
优点:
- 类SQL,也即HQL,学习成本低
- 对大数据有优势(HDFS和MapReduce)
- 扩展性,支持用户自定义函数
- 容错性高
- 拥有统一的元数据进行管理
- 离线处理
缺点:
- HQL的表达能力具有局限性
- 效率较低
因此Hive主要应用场景是用于时效性不高的海量数据的处理,对于数据量不大反而没有优势,主要用在数据仓库上。















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









