







前沿的生成式 AI 模型和高性能计算(HPC)应用推动了前所未有的计算需求,客户正在突破技术极限,以在各行各业中带来更高保真度的产品和体验。
大型语言模型(LLM)的规模在近年来呈指数级增长(以参数数量衡量),反映了人工智能领域的一个重大趋势。仅仅5年的时间跨度里,模型大小从数十亿参数增长到数千亿参数。随着 LLM 规模的扩大,它们在广泛的自然语言处理任务上的性能表现也显著提高,但规模的增加也带来了巨大的计算和资源挑战。训练和部署这些模型需要大量的计算能力、内存和存储空间。
选择推理所需计算资源时,LLM 的规模是非常重要的考虑因素。更大的 LLM 需要更多 GPU 内存来存储模型参数和中间计算结果,同时也需要更强大的计算能力来执行推理所需的矩阵乘法和其他运算。更大规模的 LLM 需要更长时间来执行单次推理传递,这增加了计算复杂性,可能导致推理延迟加大,而这对于需要实时或接近实时响应的应用来说是一个需要解决的关键因素。
为满足客户在深度学习、生成式 AI 和 HPC 工作负载方面对高性能和可扩展性的需求,亚马逊云科技宣布采用 NVIDIA H200 Tensor Core GPU 的 Amazon EC2 P5e 实例现已在海外地区正式可用!亚马逊云科技是第一家在生产环境中提供 H200 GPU的领先云厂商。此外, Amazon EC2 P5en 实例(Amazon EC2 P5e 实例的网络优化版本)也将很快推出。

Amazon EC2
扫码查看更多
本文将主要介绍这些实例的核心功能和适用的案例场景。
Amazon EC2 P5e 实例简介
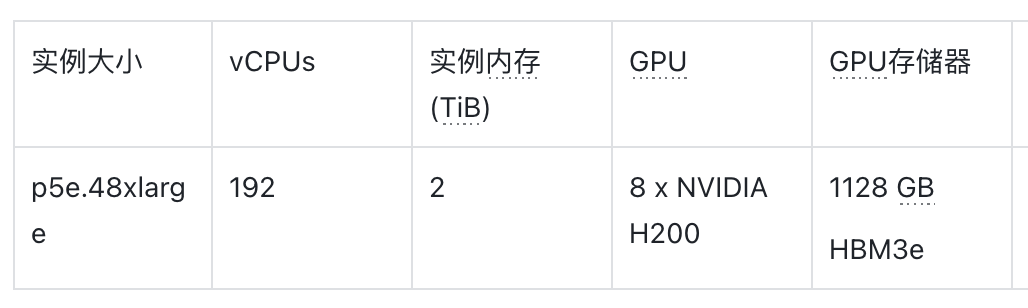
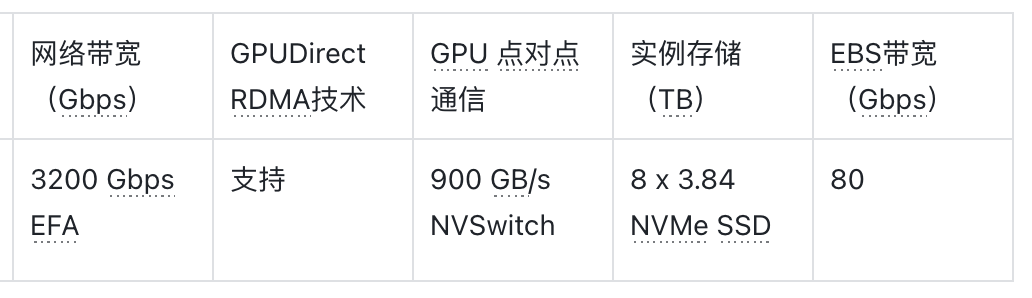
Amazon EC2 P5e 实例由 NVIDIA H200 GPU 提供支持,与搭载 NVIDIA H100 Tensor Core GPU 的 Amazon EC2 P5 实例相比,Amazon EC2 P5e 实例的 GPU 内存容量提高了 1.7 倍,GPU 内存带宽提升了 1.5 倍。
Amazon EC2 P5e 实例配备了 8 个 NVIDIA H200 GPU,总计 1128 GB 高带宽 GPU 内存,搭配第三代 AMD EPYC 处理器、2 TiB 系统内存和 30 TB 本地 NVMe 存储。Amazon EC2 P5e 实例还提供 3,200 Gbps 的总网络带宽,支持 GPUDirect RDMA 技术,通过绕过 CPU 进行节点间通信,降低延迟并提高可扩展性能。
下表总结了该实例的详细信息。
Amazon EC2 P5en 实例即将推出
GPU 加速计算的瓶颈之一可能在于 CPU 和 GPU 之间的通信。这两个组件之间的数据传输可能会耗费大量时间,特别是对于大型数据集或需要频繁数据交换的工作负载。这一挑战可能会影响广泛的由 GPU 加速的应用程序,如深度学习、高性能计算和实时数据处理。在 CPU 和 GPU 之间移动数据可能会导致延迟,降低整体效率。此外,对于分布式系统上的机器学习工作负载,网络延迟也可能成为一个问题,因为数据需要在多台机器间传输。
Amazon EC2 P5en 实例将于 2024 年推出,可以帮助解决以上挑战。Amazon EC2 P5en 实例将 NVIDIA H200 GPU 与定制的第四代 Intel Xeon 可扩展处理器相结合,实现了 CPU 和 GPU 之间的 PCIe 5.0 连接(高速串行计算机扩展总线标准)。这些实例将提供 CPU 和 GPU 之间高达四倍的带宽,并降低网络延迟,从而提高工作负载性能。
Amazon EC2 P5e 实例的使用案例
Amazon EC2 P5e 实例是训练、微调和推理运行复杂的 LLM 和多模态基础模型的理想选择,这些模型支持极具挑战性和计算密集型的生成式 AI 应用程序,包括问答对话、代码生成、视频和图像生成、语音识别等。
对于部署 LLM 进行推理的客户,使用 Amazon EC2 P5e 实例可获得多重关键优势,使其成为如上工作负载的绝佳之选。
Amazon EC2 P5e 实例中 H200 GPU 更高的内存带宽可让 GPU 更快地从内存中获取和处理数据,从而降低推理延迟,这对于对话式人工智能系统这类实时应用程序至关重要,因为用户期望近乎即时的相应。更高的内存带宽还能提供更高的吞吐量,使 GPU 每秒处理更多的推理任务。在 Amazon EC2 P5e 实例上部署 7000 亿参数的 Meta Llama 3.1 模型时,与使用 P5 实例相比,可以获得高达 1.87 倍的吞吐量提升,高达 40% 的成本降低(1)。
现代 LLM 规模庞大,拥有数百亿参数,在推理过程中需要大量内存来存储模型和中间计算结果。在标准 Amazon EC2 P5 实例上,这可能需要使用多个实例来满足内存需求。然而,Amazon EC2 P5e 实例的 GPU 内存容量提高了 1.76 倍,您能够使用单个实例来容纳整个模型,实现扩展,避免了分布式推理系统带来的复杂性和开销,如数据同步、通信和负载均衡。在单个 Amazon EC2 P5e 实例上部署 4050 亿参数的 Meta Llama 3.1 模型时,与使用两个 Amazon EC2 P5 实例相比,可以获得高达 1.72 倍的吞吐量提升,高达 69% 的成本降低(2)。
Amazon EC2 P5e 实例更大的 GPU 内存还支持在推理过程中使用更大的批量规模,从而实现更好的 GPU 利用率,更快的推理时间和更高的整体吞吐量。对于推理需求量大的客户,这些额外内存尤其有利。
(1)Input Sequence Length 121, Output Sequence Length 5000, batch size 10, vLLM framework
(2)Input Sequence Length 121, Output Sequence Length 50, batch size 10, vLLM framework
在优化推理吞吐量和成本时,客户可以调整批量大小、输入输出序列长度和量化级别等参数,因为这些参数对性能和成本影响重大。尝试不同的配置,可以找到性能和成本之间的最佳平衡,满足特定使用场景需求。
总结来说,更高的内存带宽、更大的 GPU 内存容量以及对更大批处理规模的支持,使 Amazon EC2 P5e 实例成为部署 LLM 推理工作负载的绝佳选择。与其他方案相比,Amazon EC2 P5e 实例可显著提升性能、降低成本并简化运营。
Amazon EC2 P5e 实例还非常适合内存密集型的HPC 应用程序,例如模拟、药物发现、地震分析、天气预报和金融建模。对于使用动态规划(DP)算法的应用,如基因组测序或数据分析加速,客户也可以通过 Amazon EC2 P5e 实例对 DPX 指令集的支持获得进一步优势。
开始使用 Amazon EC2 P5e 实例
在启动 Amazon EC2 P5 实例时,您可以使用 Amazon Deep Learning AMIs(DLAMI)来支持 Amazon EC2 P5 实例。DLAMI 为机器学习从业者和研究人员提供了基础设施和工具,以便在预配置的环境中快速构建可扩展、安全、分布式的机器学习应用程序。您可以使用 Amazon Elastic Container Service(Amazon ECS)或 Amazon Elastic Kubernetes Service(Amazon EKS)的库,借助亚马逊云科技深度学习容器(Amazon Deep Learning Containers)在 Amazon EC2 P5 实例上运行容器化应用程序。

Amazon Deep
Learning AMIs
扫码了解更多

Amazon Elastic
Container Service
扫码了解更多

Amazon Elastic
Kubernetes Service
扫码了解更多

Amazon Deep
Learning Containers
扫码了解更多
左右滑动查看更多
Amazon EC2 P5e 实例现已正式可用
Amazon EC2 EC2 P5e 实例现已在美国东部(俄亥俄州)亚马逊云科技区域提供 P5e.48xlarge 规格,可通过如下页面获取。关于实例的更多信息,您可参阅 Amazon EC2 P5 实例页面获取。

Amazon EC2 P5 实例
扫码查看更多
本文作者
Avi Kulkarni
亚马逊云科技全球业务发展高级专家
Karthik Venna
亚马逊云科技首席产品经理
Khaled Rawashdeh
亚马逊云科技高级产品经理
Aman Shanbhag
亚马逊云科技全球业务发展高级专家
Pavel Belevich
亚马逊云科技机器学习框架团队高级应用科学家
Dr. Maxime Hugues
亚马逊云科技全球首席生成式AI解决方案架构师
Shruti Koparkar
亚马逊云科技高级产品营销经理


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9446
9446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









